內容表格
沒有標頭原作:OSSLab Vxr
一般RAID架構最簡單區分法就是分為Hardware RAID與Software RAID, 通常大部分人認為Hardware RAID內置了IOP(I/O Processor)可以分擔RAID運算, 例如最常被提到的XOR operation, 在特定的RAID模式下會用到此運算. 這個操作用來求得一個parity value, 作為復原資料之用途. 來自AMCC的一份文件-RAID 5/6 with PowerPC440SP/SPe, 圖中表明了這種設計:
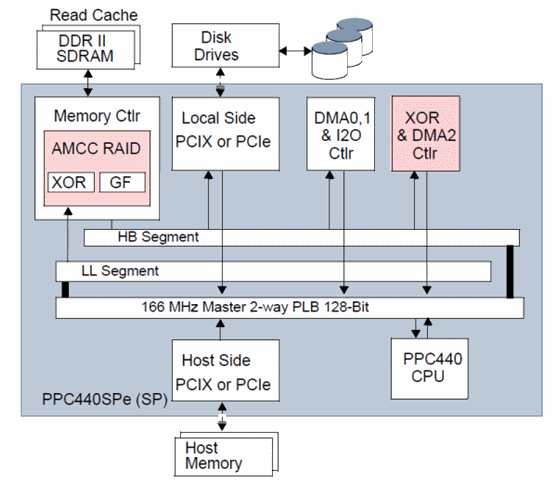
圖中這一整個PPC440SPe可以說是一個IOP, 其中有兩組單元用來操作最常被提及的XOR operation, 一個是與DMA Unit組合的XOR Assist, 另一個則是接附在Memory Controller的XOR/GF function硬線加速設計. 這兩種設計可被用來操作XOR operation取得直接的效益, 通常我們可以用一個統一的詞彙來通稱-Hardware RAID Assist, 硬體RAID輔助單元表示某種程度的硬線操作單元, 用來加速RAID運算. PPC440SPe的圖中還可以看到各個單元都連接在一組bus上, 這是IBM的PLB(Processor Local Bus, CoreConnect技術), Full-Duplex, crossbar架構, 128bits, 在166MHz下, 內部互連頻寬可以達到10. 4GB/s. 對於儲存設備來說, 這個數字是相當充裕的. Hardware RAID Assist的設計在Intel的IOP產品下同樣也可以見到, 我們可以看下面這張方塊圖表示:
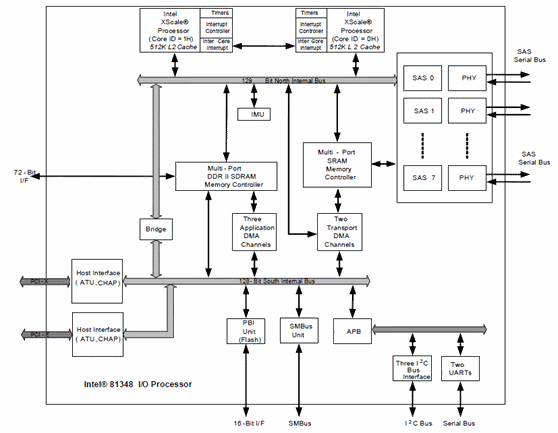
這張是來自Intel的一份文件-Intel 81348 IO Processor Datasheet所提及的, 其中Three Application DMA Channels(ADMA;4KB資料傳輸, Intel IOP333的AAU則是1KB/512bytes資料傳輸)包含了對XOR operation操作, 他被連接在Memory Controller上, 取得Cache Memory中的operand和result用來計算. 另外可以看到包含兩組bus(XSI): North和South, 128bits@400MHz, 獨立操作, 所以內部頻寬也是充裕的. IOP348是RoC架構, 可以看到他還整合了IOC的部分成為完整的RAID Controller.
到此我們可以知道一般Hardware RAID包含了Hardware RAID Assist的協助, 另外由於大量I/O操作下, Hardware RAID Assist會被頻繁使用到, 如果應用某種Cache機制將被操作的operand與result給快取住, 那勢必提升的效益是立竿見影的. 因此通常包含Hardware RAID Assist的設計還會搭配Memory Controller用來連接較高速的DRAM buffer作為Cache Memory. 在傳統RAID下, 對於小區塊資料I/O操作頻繁的處理, 應用DRAM作為Cache Memory所獲得的效果是極佳的(WB&RA), 例如像是Web Server的應用, DRAM buffer做為二級快取使用.
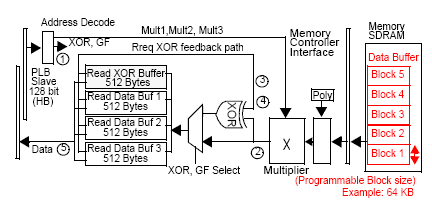
我們根據AMCC的另一份文件-AMCC RAID6 accelerator in a PowerPC IOP SOC, 兩張圖中可以看到DRAM buffer作為Cache Memory應用:
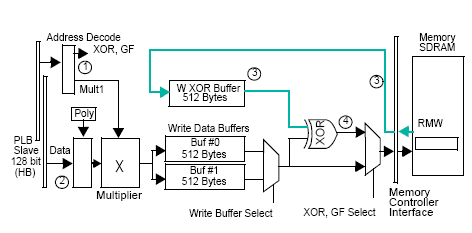
這張圖或許可能不太好懂, 這是AMCC對RAID 6的XOR/GF硬線加速設計, 利用Memory Controller附接一組特殊的Hardware RAID Assist, 這個輔助單元可以操作兩種計算:XOR和GF function, RAID 6應用基本上就是求得兩種parity用來做為復原資料之用, P和Q的parity, 快速講一下這個作法. RAID的最基本是透過Stripping技術將資料切割成條帶(Stripe)寫入每一顆儲存裝置裡, 假設說我條帶大小設成64KB, 目前現有裝置8顆硬碟, 通過條帶化後, 64/8=8KB, 一條Stripe便是8組數據值組成儲存在8顆硬碟上(D1, D2, D3, …, D8), 這樣做便會達成加速I/O存取速度. 這是一種典型的RAID 0操作. 不過在RAID 6會有一些複雜性的改變, 因為他需要消耗兩個parity存取, 這兩個parity算是某種形式的特殊數據值, 也就是說如果是D1, …, D8, 實際上是D1, …, D6, P, Q. 這樣意味著, 我們真正能儲存資料的空間是N-2顆硬碟總和, 基本上我們先別管他的計算順序和大小, 只要稍微知道他是如何做就好. RAID 5的基本模型是N-1顆硬碟總和, 拿一個parity作為校驗, 下面這張圖便可以表示:
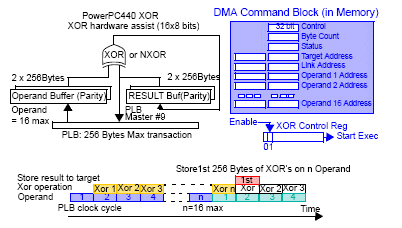
這是和DMA Unit組合的Hardware XOR Assist, 透過DMA Unit從Cache Memory取得數據後進行XOR operation, 再將result回存至Cache Memory. 假設有4顆硬碟, 那麼實際可用空間為4-1顆硬碟總和, 如果Stripe Size設定為128KB, 那麼條帶化後, 每顆硬碟儲存32KB數據, 其中有一組32KB數據必須做為parity使用, 也就是D1, D2, D3, P的組合, P的value求得方式基本上就是D1 xor D2 xor D3 =P, 你可以從圖上發現, AMCC的這個設計可以傳入達到16個資料流進行XOR operation求得P value(這樣其實會形成一個VD能使用的裝置數量會受到物理限制), 再放回Cache Memory. DMA Unit紀錄包括每個要進行XOR operation的operand位址.
回到RAID 6的那塊圖, 我們大概可以稍微知道RAID 5對於P value的求得方式, 那在AMCC的RAID 6又是如何求得呢?其實從剛開始第一張圖可以發現附接在Memory Controller的AMCC RAID的Hardware RAID Assist包含一個GF設計, GF function是Galois field的數學計算式, 我們不必理會他怎麼計算, 只要知道有個這硬線設計功能就可以了. XOR的部分基本上與RAID 5一樣, 在前面有講過如果有8顆硬碟, 在RAID 6中, 只有8-2顆硬碟可用空間(邏輯上概念), P和Q會分別占用掉一組條帶的2/8, 但是求得的方式是除了Q以外的原始切割數據進行XOR操作後取得P value, 也就是D1 xor D2 xor D3 xor . . . . xor D7, 至於Q parity則是將7/8包括P的每個數據先經過GF計算後, 在進行XOR operation便可取得(綠色走線傳回去至XOR buffer). 這樣我們就大概基本了解P和Q的求取方式了. 再者還可以知道, 利用Cache Memory的設計形式可以大幅加速存取時間, 對大量的I/O操作是有正面助益的(可以發現RAID 5/6對Cache Memory的使用是較為敏感的).
下面這張則是反方向從P, Q的parity和條帶中的資料計算求得原始資料, 這個看看就好.
我們大致上對Hardware RAID Assist有個了解, 不過RAID 6的實際設計是相當複雜, 每家算法未必相同, 但脫離不了基本的概念. 在Hardware RAID實務設計中, 從前面已經知道有兩個重要組成:一個是Hardware RAID Assist和Memory Controller設計, 這兩種設計的關鍵可以用以大幅提升大多RAID模式的性能, 在不需要進行XOR/GF function操作下的RAID模式, Cache Memory的支持還是有相當明顯的助益(WB/RA). 但是我們是否漏掉的一個部分沒有談到呢?看看前面的第一張圖吧?有沒有看到裡面有一個PPC440 CPU呢?這是我們本次所要談到的built-in Processor, 不要認為built-in Processor比起前面那兩種硬線設計不重要, 事實上他更是重要, built-in Processor可以協同相關的I/O操作與RAID計算, 例如interrupt處理或著Hardware Stripping, 以及像是一些定址操作, 例如將定址解碼後從Cache Memory取得相關資料, 或著一些偵錯機制的操作, Rebuild, OCE和ORLM都需要用到他. 因此可以說是重要程度極高. 一個好的built-in Processor方案是明顯對RAID性能是有幫助的. 在一個特殊的分離式RAID架構-3ware StorSwitch, StorSwitch架構是一個明顯的高度分離式方案, 在最後兩款款產品9650SE/9690SA, 由一顆I/O Processor-PPC405CR(built-in processor), AMCC特製多重DMA通道(32條)XOR加速器-G133 RAID engine和一顆I/O Controller組合而成. 9650SE是採用Marvell的IOC solution, 9690SA則是Emulex的IOC500.

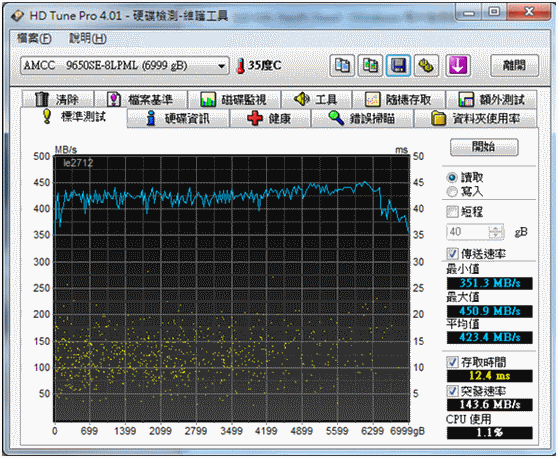
9690SA這個產品其實算是不錯, 經典的StorSwitch架構進行一些循序存取測試發現跌幅沒有像LSI較為嚴重, 尤其大型I/O資料區塊傳輸, 效果不差. 下面是從網路上擷取到9650SE RAID HBA拿8顆1TB FALS作HD TUNE測試成績, 你可以發現是相當區於平穩的, 並沒有像LSI那種斜坡式下降.
不過不管9650SE或是9690SA, 個人覺得他效能明顯沒有跟LSISAS1078並駕齊驅, 事實上我反而認為他效能不佳. 早期我拿9690SA用4顆SAS 15k. 6 146GB作RAID 5得到了悲劇性的結果.
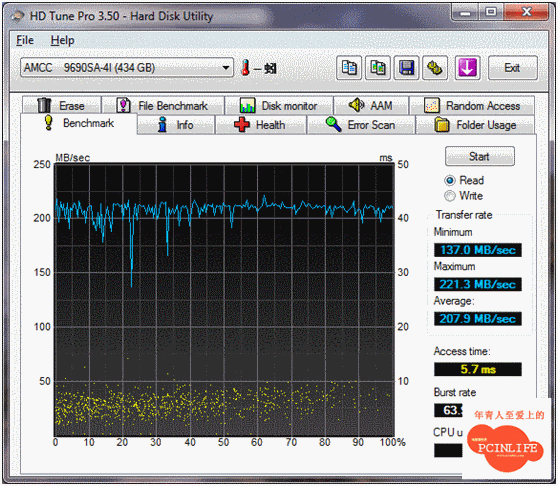
上圖便是用4顆15k. 6 146GB作RAID 5的成績, StorSwitch的優勢性讓跌幅趨於平穩, 可是取得的性能實在不好看. 那時我又作了一些其他測試.
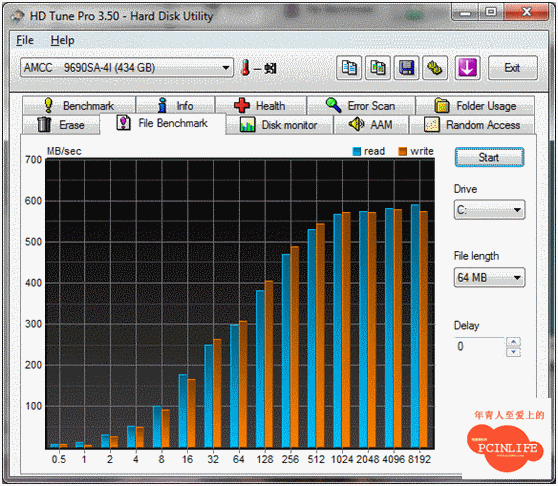
File Length為64MB, 其實就這個成績來說算是很勉強, 因為9690SA可能透過獨特的AMCC特製XOR加速器連接DDR2-533 512MB, 這個64MB的尺寸要塞到Cache Memory是ok的, 不過這個不到600MB的傳輸速度我覺得太慘了. 為了有更多證明, 我又拿了Crystal Disk Mark進行測試, 結果發現一個狀況. 在100MB小尺寸的檔案測試下, 怎樣都突破不了1GB的關卡.
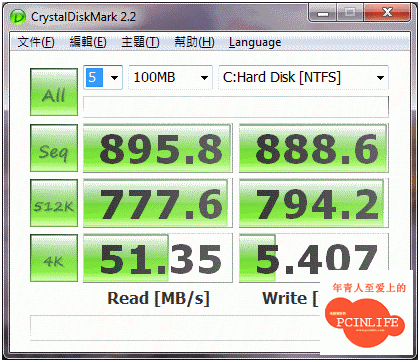
當時我拿LSISAS1078的對照組來看, 根本是天差地遠. 下圖是LSISAS1078的成績.
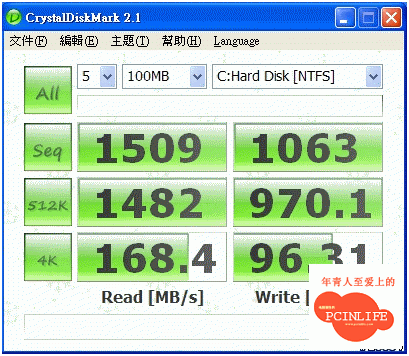
另外我還使用ATTO去檢測最大的循序存取速度還發現了某種瓶頸存在, 來看看這張測試結果:
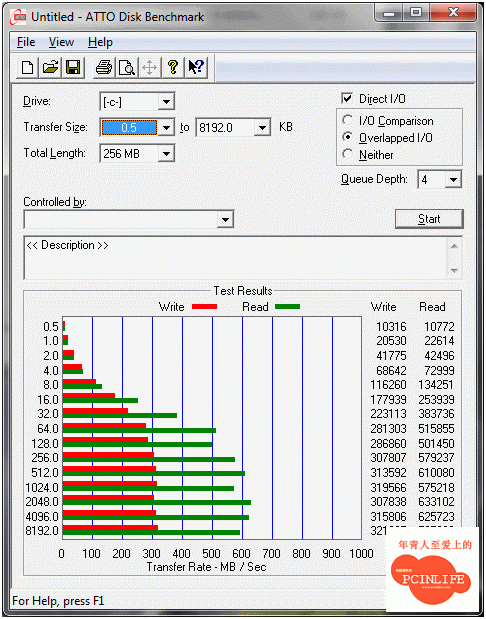
在QD4的情況下, 寫入被卡死在某個速度限制下, 讀取依然無法突破700MB/s. 真的是測的心灰意冷, 但測試歸測試, 還是要想想到底問題出在哪, 曾經想了一段時間, 我認為IOC是沒有認為問題的, 那顆IOC500去跟Intel的IOP34x產品對照看看吧. . , 長得非常像(廢話!因為有合作阿. . ), 所以我不太認為會出在IOC部分, 那特製的AMCC DMA多通道XOR加速器呢?那個XOR加速器提供32條DMA channels, 足以供應超過8個數量的儲存裝置使用, 可以說算是某種程度上的高級PM設計, 我認為瓶頸應該不是卡在那邊. 最後, 我想到了那顆PPC405CR的I/O Processor, 個人猜測整個bottleneck完全卡在那顆I/O Processor上, 為此去查了關於這顆I/O Processor的相關資料, 來看看這顆I/O Processor的方塊圖架構:
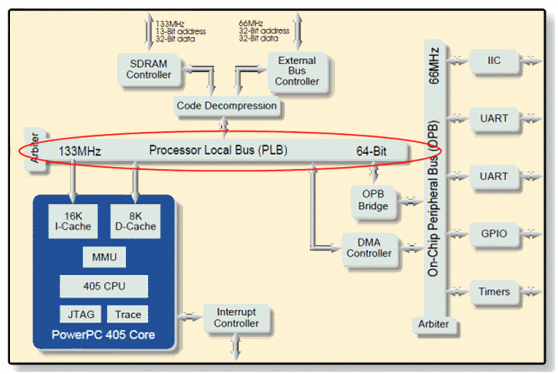
PPC405CR是一顆很古老的I/O Processor, clock只有266MHz, 比起LSISAS1078的PPC440, 性能可是差一大截, 按照AMCC的Product Selector Guide, 他的運算量只有506~520DMIPS左右, 一顆PPC440 Core可以達到1000DMIPS以上的運算量, 2倍資源的指令快取和4倍資源的資料快取(雙向), 這要怎麼比?MMU資源部分小弟還沒去詳查, 估計好不到哪去, 先不管這個PPC Core好了, 他連接的PLB也是個問題, 如果按照AMCC的設計沒甚麼變化的話, 這個PLB是比較早期的版本, 64bits@133MHz, 基本上與SDRAM的clock同步, 而且不是crossbar架構, 照這樣講, 頻寬換算就只有1GB/s左右而已, 如果按照這樣猜測的話, 不管接多少顆15k SAS硬碟, 打死根本都無法突破1GB/s的I/O傳輸量. 3ware也被LSI買走了, 相關的RAID stack技術也屬於LSI, StorSwitch這個架構也隨之完全被消滅, 這邊僅作為一個歷史的見解.
回到這邊我們所要談的主題-built-in processor, 前面我們已經知道一個有瓶頸存在的子處理器會帶來甚麼樣的性能瓶頸, 在現今的RAID架構下, 目前以RoC架構為主流導向, 因為它有其優點:
1. Layout佈局縮小.
2. 有助於costdown.
3. 良好的設計會使效益遠遠超過Discrete RAID架構.
4. 有效的內部互連頻寬完全不必考慮瓶頸存在.
5. 一個有效的Hardware RAID Assist設計可以大幅增強性能.
從這幾點可以知道, 整合I/O Processor, Hardware RAID Assist和IOC的RoC設計優勢遠遠不是Discrete RAID架構可以比的. 下面是一張LSISAS1078方塊圖架構:
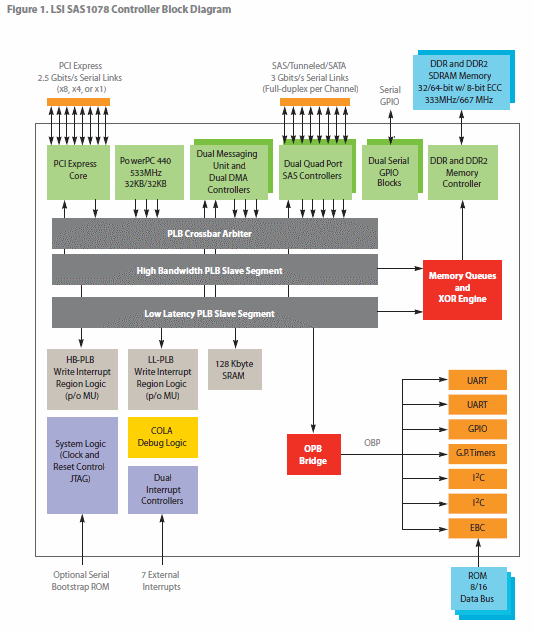
在這次的主題, 要探討built-in Processor的有無, 有甚麼樣的差異性?並不考慮特殊的Hardware RAID Assist, 因為僅在RAID 0下進行測試, 所以用不到. 我們會進行兩種方案的差異性測試:Driver-based RAID和IOP-based RAID. IOP-based RAID可以說是完整的Pure-Hardware RAID方案, 基本的特徵就是前面之前提過的. 透過硬線設計建立自有的RAID stack;資料安全性及整合性遠高過Driver-based RAID架構;遠不如近, 有較低的Response Time;built-in Processor協同計算, 比起要完全依靠Host-CPU的Driver-based RAID, 通常會有更好的性能. Driver-based RAID的Host-RAID Engine建立在裝置驅動程式(driver)上, 因此要必須承擔一定程度的風險. 下面這張是Driver-based RAID的架構圖, 取自Adaptec by PMC的一份文件:
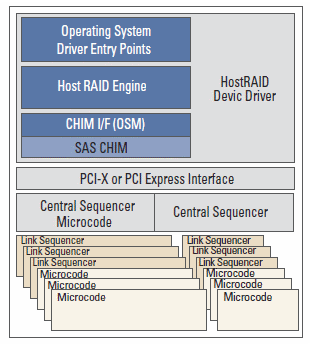
HostRAID Device Driver包含了Host RAID Engine, 所有相關的RAID計算都是由裝置驅動程式去實現的, 比方說萬一延遲寫入時, 發生不當的H/W Reset, 有可能會導致整顆VD毀損. 當然, 不管是Driver-based RAID或著Hardware RAID, 應該會包含某種程度的NVSRAM設計, 進行一種write journaling功能, 寫入小量的log(某種程度的checkpoint)至NVSRAM, 不正常的開機運作, 這樣的設計還是保有一定程度的安全性. 另外, 透過一張圖來表示Hardware RAID的stack架構, 如下所示:
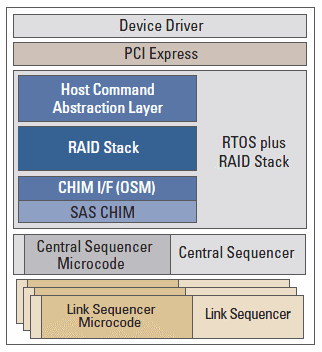
從上圖可以看到, Hardware RAID設計方案, 透過firmware包有自家的RAID stack來決定硬線功能設計上的使用, 這意味著縱有相關RAID硬線設計(Hardware RAID Assisr). 真正Hardware RAID是與否, 還得看firmware內容去決定, 例如LSI的LSISAS2008, 當透過RAIDKey啟用RAID5模式的時候, 由於他沒有任何Hardware RAID Assist設計. 基本上在IMR模式下, 算是Driver-based RAID架構, 而且性能受到很大的限制, 例如併發I/O數量只有31條, 跟LSISAS2108的1008條併發I/O數量相比, 簡直天差地遠. 其次就是built-in Processor可能會沒有效果, 因為相關的操作反而要依賴Host CPU. 在RAID 5模式下, 所得到的性能可以說只有淒慘兩個字可以形容. 個人認為LSISAS2008僅適合作為一般純HBA方案使用較為適合, 就算在IT模式下, 那顆built-in Processor應該也是會有效果的.
說了那麼多, 要進入測試的部分了, Driver-based RAID採用常見的Intel solution-ICH10R; IOP-based RAID依然是愛用的LSISAS2108高階主流方案. 這次應用拿兩顆Crucial C300 128GB x2去檢測. 使用的是ioMeter來查看有無built-in Processor的差異性. Driver-based RAID所有RAID相關計算要依靠Host CPU, 我這次拿Intel Xeon W3570的4C/8T@3. 20GHz CPU應該是相當Ok的.
ioMeter的測試是以最大I/O讀取性能測試為主, 來看下面的設定:
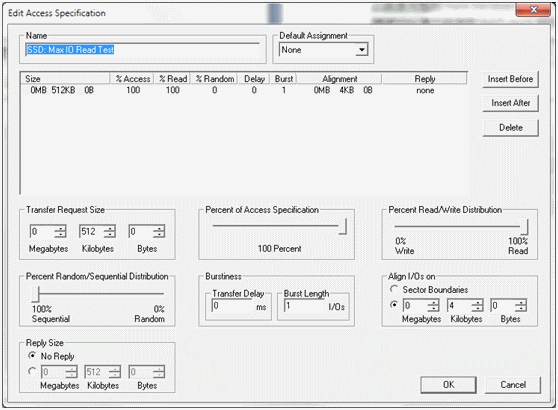
由於是測試SSD的關係, 請記得!要4K對齊測試, 否則結果會有問題. 個人會測試不同的QD深度來評估其差異. Stripe Size以64KB為主.
我們先看看Driver-based RAID與IOP-based RAID在CPU負載量的差異上:
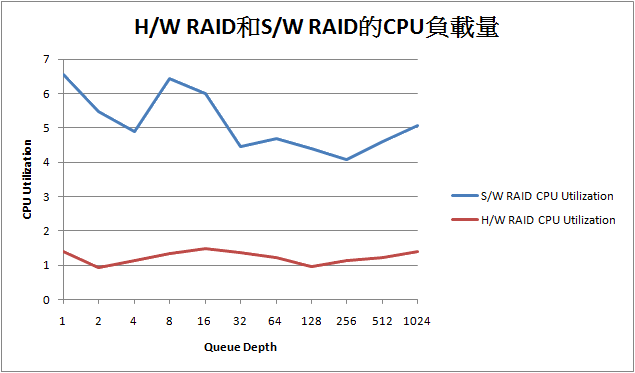
千萬不要以為這兩者之間差異很小, 因為這是用平均值來算, 靠CPU的威能才可以達到這樣. 如果把每個thread的負載量拆出來看, 那差異就大了. 這邊就不拆出來看了, 因為用CPU Effectivness就可以看出來了.
在來看看不同的I/O請求會造成對Host CPU的中斷數量差異:
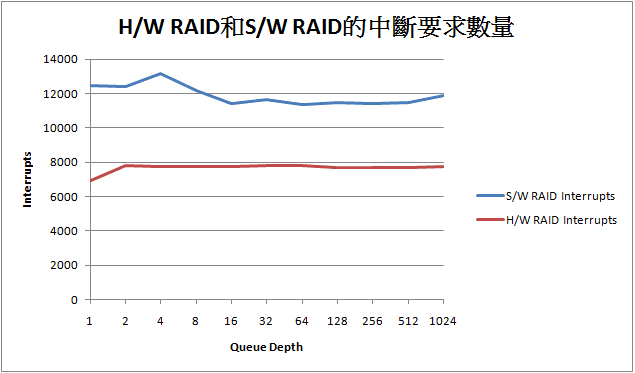
明顯可以看出Hardware RAID方案在這部分有其優勢性, 對Host CPU觸發的中斷數量遠遠低於Driver-based RAID, built-in Processor的作用還是可以看到的. 我們在來看看I/O平均回應時間的差異性:
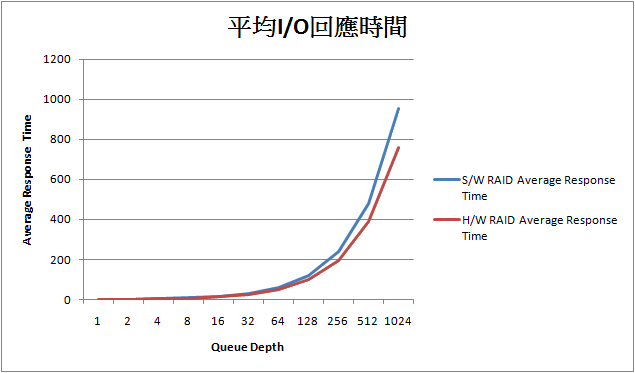
在QD愈深的情況下, Hardware RAID優勢明顯, 相對於最大I/O回應時間, 如下圖:
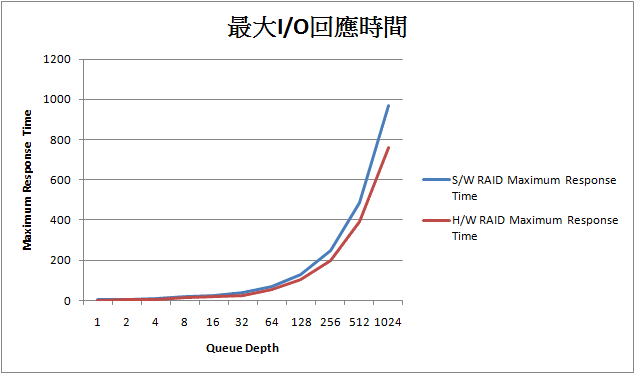
可以看出一個Hardware RAID方案優於Driver-based RAID是很正常的. 最後我們來看一個I/O子系統對於CPU所獲取的I/O存取效益為何:
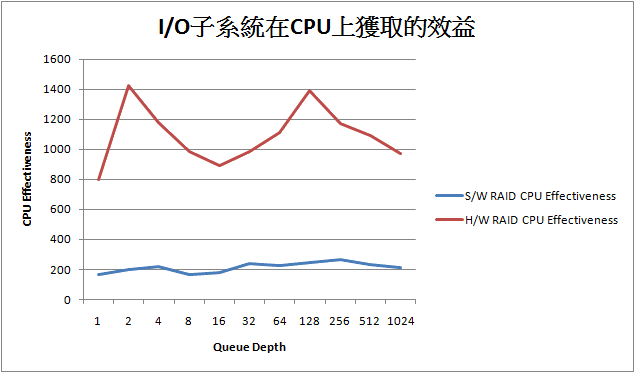
OK, …不得不說這個差異太過明顯, CPU Effectiveness其實可以算出來的, 他的公式表示如下:
CPU Effectiveness= IOPS/CPU Utilization
也就是說IOPS愈高, CPU使用量愈低, 所獲取的效益愈高, 不過由於這是測試循序的最大I/O傳輸, 大家IOPS都高不到哪裡. 但是可以看出的是IOP-based RAID對於CPU使用率是有效低於Driver-based RAID方案, 因此可以得到相當高的CPU Effectiveness.
最後, 透過這些測試便可以知道Hardware RAID相對於Driver-based RAID如何有其差異, 這邊主要並不是說兩者的好與壞, 僅是表示在built-in Processor的RAID架構, 可以獲得怎樣的效益.
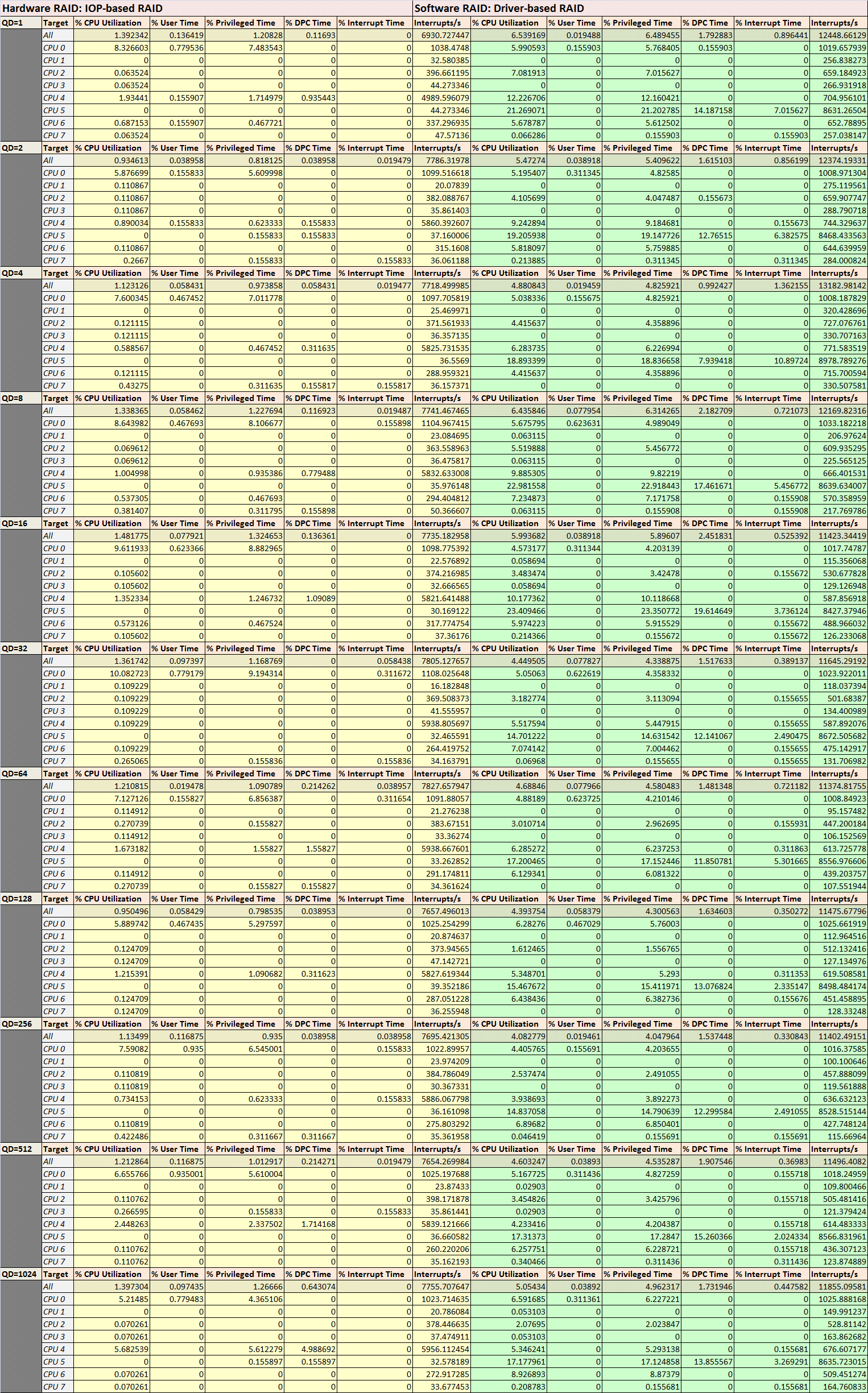
H/W RAID和S/W RAID的CPU負載表(點擊可放大...):
- Was this page helpful?
- 標籤 (Edit tags)
- 什麼連接到這裡
| Images 0 | ||
|---|---|---|
| No images to display in the gallery. |