SAS Expander的路由表概觀
內容表格
沒有標頭SAS Expander標準允許路由表的建立, 這個作用在於面臨路徑選擇的時候, 必須要依賴路由表的使用. 由於direct routing和subtractive routing無法應付這樣的情況.
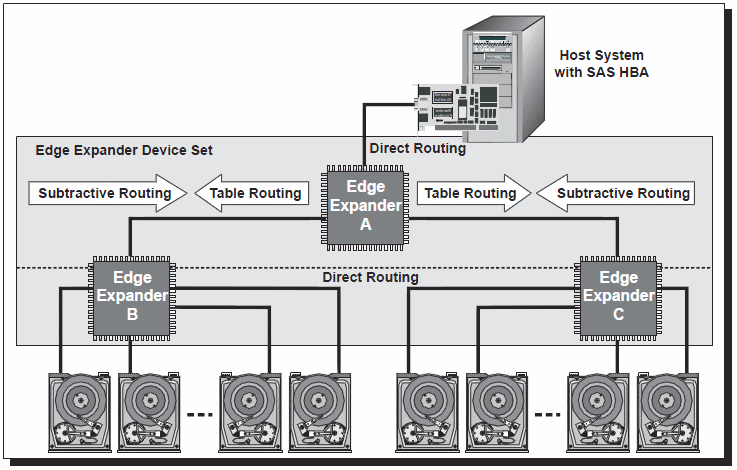
從上圖這個案例可以看到三種路由算法的使用, 一個Edge Expander Device Set可以看做是一個could. Expander B和C的downstream直接銜接end devices, 所以使用no routing的direct routing建立通訊即可. 當Expander B和C往upstream通訊的時候, 由於這並非存在於本身的既有目的端位址集合, 也就是說他必須要跨Expander通訊, 例如一個來自Expander C的請求發送至Expander B的目的端-某個target port對應, 由於Expander B上某個target port的SAS Address是不可能存在於Expander C上, 因此使用Subtractive routing來轉發送到Expander C.
No routing的direct routing和Subtractive routing都可以看出一種共通的情況, 那就是他們都不會面臨路徑選擇, 也就是只會有1對1的情況下, 當遇到路徑選擇的時候, 前面兩個路由算法就不適合使用了. 在SAS Expander標準下便改使用一種routing table紀錄的方式來提供更大範圍的裝置數量存取. 上圖的案例, 在Expander A轉發送請求, 面對downstream發生了路徑選擇的情況, 這時候無法去判別請求的目的端是屬於哪一個Expander(B or C???). 改用routing table記錄每個downstream的SAS Address便可解決這個問題, 也就是使用table routing算法. 下面另一個不太好看的HP案例可以看到使用了routing table進行downstream的SAS Address紀錄.

在說明這個案例的routing table應用以前, 必須要先知道routing table的綱要是如何定義的, 也就是table的metadata. 來自HP的一份SAS標準文件提供這方面的紀載, 如下所示:

首先說明table上的row與column的header定義, 在每個column的header定義了在Expander上每個實體輸出的對應端口賦予的唯一識別代碼. N<=number of phys -1, 由於索引(index)是從0開始計算, 所以必須減1; 而row的header就是對於每個的路由索引(route index), 路由索引值集終值會是索引值集合數量去減1得出, 因為索引值要從0開始計算.Expander route entry代表抵達的路由位址, 由column與row定址過後取得, entry包含了被蒐集的SAS Address以及開關位元資訊.
1. column header: 對於Expander上每個實體輸出賦予唯一的識別碼
2. row header: 對應到expander route entry所在位址的Expander路由索引(route index)
3. expander route entry: 透過column和row定址的每個Expander路由個體(route entry). 包含SAS Address和開關位元.
說明了table的綱要以後, 或許概念上可能還迷迷糊糊, 還是有很多疑問, 這邊將透過一個範例來說明table如何做routing, 使得在概念上更為清晰. 自製的一個範例圖如下所示, 這個範例圖比HP的案例較為簡單:
