Sense Code Message
內容表格
沒有標頭在LSI IMR產品於event log中常常會看到以下這種形式的日誌紀錄:

此紀錄是為LSI的感測代碼(Sense Code)型式. 這種未預期(Unexpected)的代碼通常可以具體的判讀目前RAID controller究竟發發生了何種狀況?時間點與目的. 但是他有一個缺點, 從人類行為角度觀來看, 他並不好閱讀. 通常要進行人為上的解碼(decoding), 因此需要花費一些時間.
根據Intel的一份LSI RAID訓練文件顯示出改測代碼的基本佈局(layout). 如下圖所示:

根據上圖通常要在乎的是c到g的區塊. 重點在於f之後的區塊. 顯然在LSI RAID維護上, 感測代碼的解讀是相當重要且有意義的一環.f之後的區塊所呈現的形式如下:
Unexpected Sense Codes are error messages that are generated when a device attached to a RAID controller encounters an error and responds with a device based error message.
雖然感測代碼主要描述的錯誤問題(issue)的產生, 但並非全然都是設備問題點的產生. 具體上它只是描述當前的例外情況(exception). LSI IMR controller是如何導引這些代碼的產生, 如下表示:
1. IMR HBA會觸發相關命令與當前狀態的更新.
2. 如果設備端(target)的狀態並不是good(00h), 控制器會觸發REQUEST SENSE命令到設備端.
3. 從一個REQUEST SENSE回應的非預期感測代碼並且包含CDB(Command Data Block)的組成會被處理.
4. CDB包含發送到設備端的命令以及相關的感測數據包含從設備端發送的錯誤訊息, 訊息長度達到255bytes.
5. 一個被紀錄的項目包含以下的型式:
>>a. 事件的時間點
>>b. 引發的來源通道(channel)以及設備端
>>c. 符合標準的SAS/SATA CDB
>>d. 從設備端回傳的感測代碼(sense code)
6. 回傳的感測數據包含以下型式:
>>a. 感測鍵(SENSE key), byte 2
>>b. 感測代碼訊息(sense code), byte12
>>c. 感測代碼修飾符(sense code qualifer), byte 13
所以以前面第二張圖的佈局的公式展現如下所示:

前面提到過, 最重要的關注點是在CDB in Hex與Sense in Hex的一大串編碼的解讀. 以前面第一張圖的範例來進行解讀:
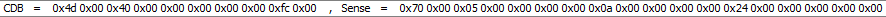
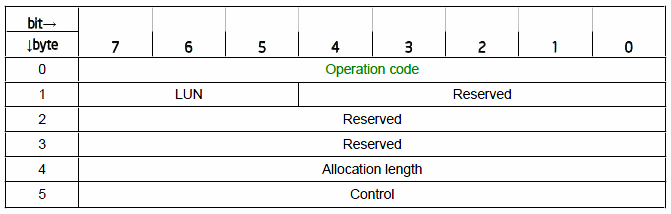
包含了CDB和Sense code的佈局. 首先來釐清CDB的佈局格式, 如下圖所示:

拆成10組byte區塊, 以Hex型式呈現. 每組記錄不同的描述情況. 當然這是其中一種型式, LSI RAID controller可以描述4種不同長度的CDB訊息: 6, 10, 12, 16等這四種CDB長度. 上面的範例屬於長度為10的CDB. LSI在描述CDB最重要的是第0組的byte代碼, 是為operation code, 為發生的操作情況.
上述的10bytes規格,他的stack佈局可如下所示:

以下的三張圖為描述Operation Code的相關列表(list):



根據前面的範例:
byte 0為4d, 從list判讀出這是LOG SENSE的operation code. 事實上這可能是一個程式的監控所造成的非預期感測的觸發, 這個觸發是個人之前使用Hard Disk Sentinel所引起的, 他會定期一段時間去刷新PD的當前運作狀況, 所以會引起RAID controller的偵測.
這個LSI傳回的CDB描述, 最大重點在於byte 0的確認, 用以判讀當前的操作情況, 其餘的一般維護上可以略過不計. 以下是6bytes CDB stack結構
以下的範例為之前發生的設備端問題點所觸發的CDB回傳:
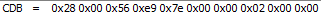
從operation code取得去查看前面的list對應的操作為何. 代碼28表示操作為讀取的情況發生. 這個CDB的回傳是個人之前使用CC去校正parity, 但是因為這是失敗的情況所傳回的相關回傳, 為讀取操作錯誤(read error). 詳細的問題點必須還要透過另外的sense data進行解讀, 也就是如下圈選的區塊所示:

Sense Code是一組超長段最大可以達到255bytes的代碼訊息. 主要他記載發生的錯誤與失敗情況, 顯然這是非常重要的解讀. 以下為LSI的Sense Code的stack佈局:
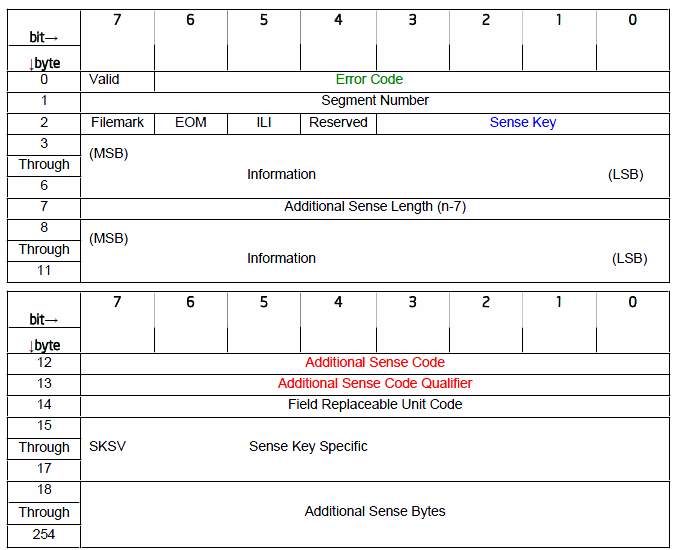
以其他顏色標記的字塊為Sense Code的重要解讀, 通常是不能忽略, 也是主要去說明的. 根據LSI的Sense Code回傳大多是以下的呈現長度:

標記的顏色表示4塊重要的必須解讀字塊, 依順序為: Error Code, SK, ASC和ASCQ等這四種.
Error Code大多情況回傳都是70. Error Code由target device所觸發的, 當然具體情況必須要視後續的其他字塊判讀而定.
The Error Code (Byte 0) for an unexpected sense code is usually 70. Sometimes this byte contains F0 instead because the 7th bit of the Byte 0 is valid, e.g., 0xF0 = 0x70 | 0x80, 0x70 indicates the current error on the target device and 0x80 indicates that the field contains valid information.
Sense Key是可以作為起頭的目錄標記, 與其他字塊組成表示為當前的具體情況. 可能的標記有:
>>00: 無情況
>>01: Soft Error
>>02: Not Ready
>>03: Medium Error
>>04: Hardware Error
>>05: Illegal Request
>>06: Unit Attention
>>07: Write Protect
>>0b: Aborted Command
>>0e|0x: Other
通常來說, SK為03或04皆為非常嚴重的臨界錯誤(critical error), 一旦出現時, 管理人員通常要有心理準備去面對. 其餘的ASC和ASCQ可以與SK進行組合來表示唯一的狀況. 以下列表可以表示相關情況的發生:

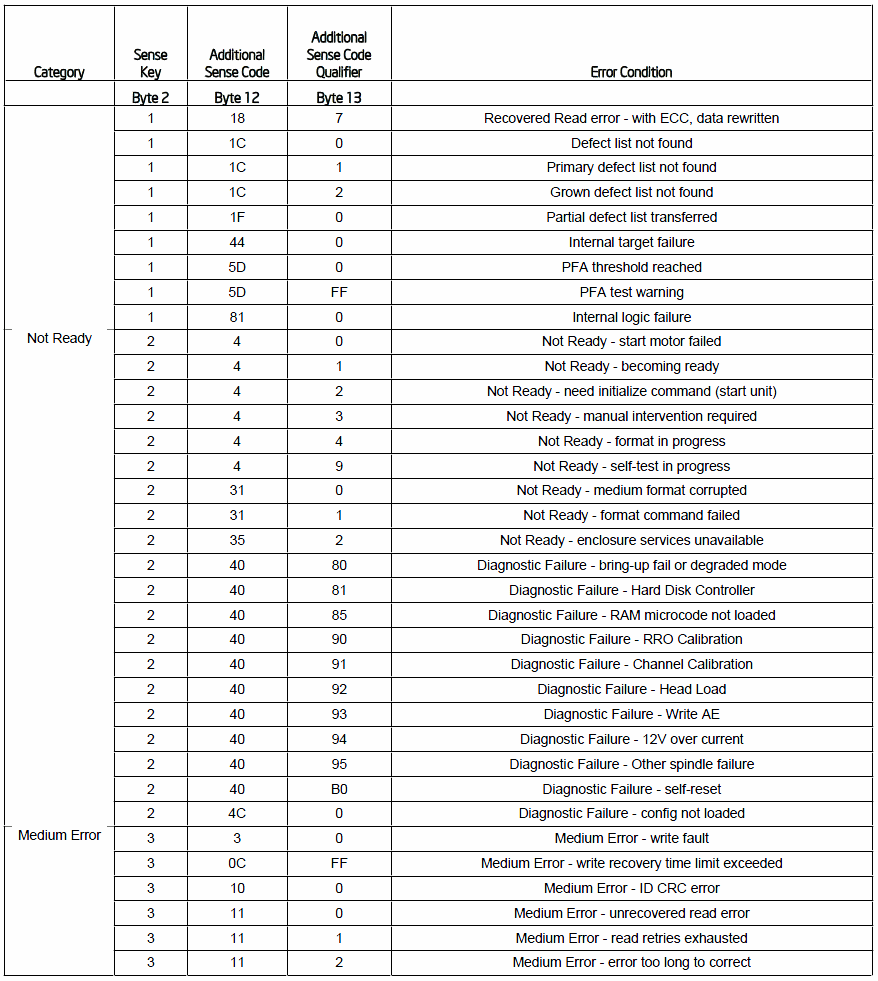
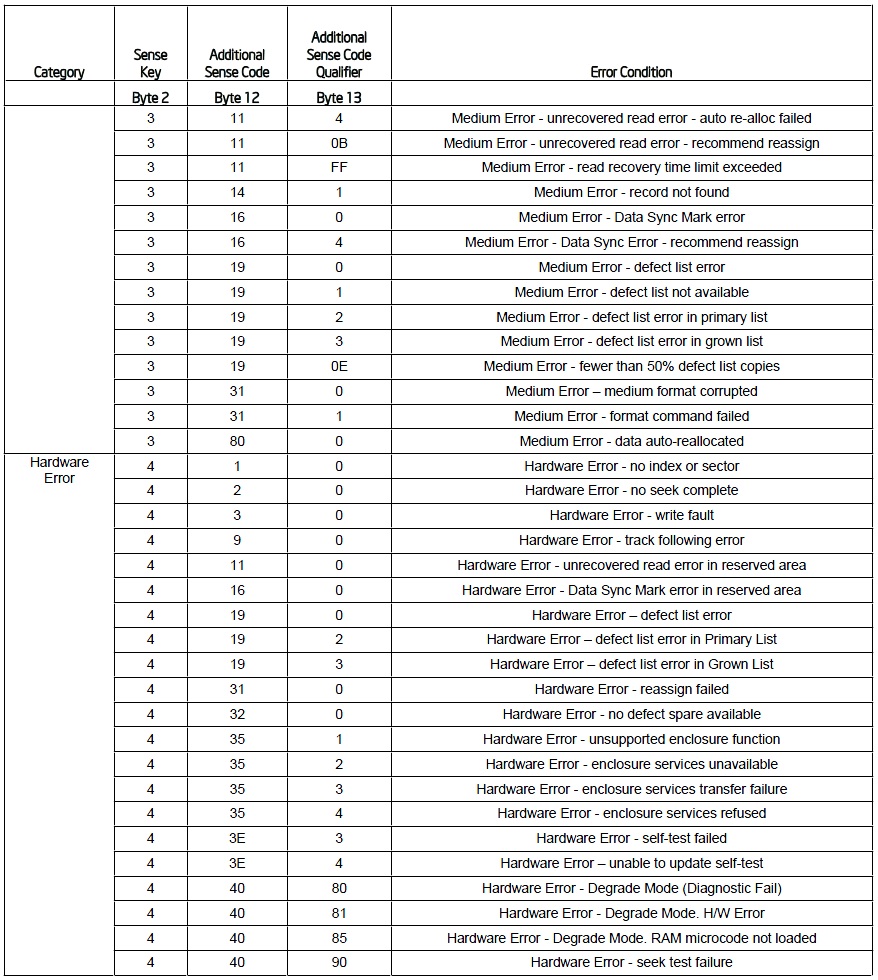




三組字塊進行組合, 並且為Hex型式, 因此表達的情況相當多. 管理人員大多只要記住SK即可, 其餘則依照列表進行查詢. 以下為一個範例來進行判斷:

首先byte 0為f0的錯誤代碼, 接下來看到byte 2的SK為03, 從SK看出大致上可以知道這是一個嚴重的臨界錯誤, medium error. 這時就需要有心理準備, 在來往後看ASC和ASCQ部分: 11和00. 所以SK+ASC+ASCQ=03 11 00. 馬上進行查表. 得知出了具體的情況:
Medium Error - unrecovered read error

顯然這是一個非常糟糕的情況. 這個情況會促使Media Error Count增加, 最後你只能把PD直接換掉(replace), 因為PD可以說是出現壞軌的情況了.
來看看另外一個範例, 如下所示:

Error Code為70, 直接追SK, 表示為05. Illegal Request, 還好這不是甚麼嚴重的問題, 最後05 24 00. 具體的情況如下: