生成式 AI 是由遠超過人類一輩子閱讀量的文字、影像、聲音所訓練而成,但卻缺乏普通人類的價值觀及基本判斷能力。「他」就像是個博學多聞、過目不忘的孩子,卻缺乏生活常識;偶爾胡說八道,又時常過度坦誠,因而需要隨時照料。因此,無論單純利用 AI 產生內容,或是將 AI 包裝為自家服務的公司,都應該特別小心謹慎。
##### LLM (大型語言模型) 語言模型支援的一般自然語言處理(NLP) 工作包括: - 文字分析,例如擷取關鍵詞或識別文字中的具名實體。 - 情感分析和意見挖掘,將文字分類為 *正面* 或 *負面*。 - 機器翻譯,其中文字會自動從一種語言翻譯到另一種語言。 - 摘要,其中摘要說明大型文字主體的主要重點。 - 對話式 AI 解決方案,例如 *聊天機器人* 或 *數位助理*,其中語言模型可以解譯自然語言輸入,並傳回適當的回應。 ##### 其他 - Agent (代理/專員): 扮演介於用戶與 AI 之間的中間人,使 LLM 透過外部資源存取、執行指令及管理工作流程來執行更複雜的任務 - Token (詞元): 模型能一次處理運算的文字長度單位 - Tokenizer (分詞器) - TOPS: AI 性能基礎計算單位,類似遊戲性能的 FPS、磁碟存取性能的 IOPS。 #### Introduction - [關於生成式 AI,產品經理(PM)需要知道的 20 個關鍵字 - ALPHA Camp](https://tw.alphacamp.co/blog/from-llm-to-text-to-image-20-essential-keywords-for-product-managers-on-generative-ai) - [用 AI 提高工程師的生產力,初階、資深與獨立開發者的三種不同做法 - ALPHA Camp](https://tw.alphacamp.co/blog/three-ways-to-use-ai-to-enhance-the-productivity-of-a-engineer) - [Prompt Engineering 提示工程是什麼?新手必學指南 - ALPHA Camp](https://tw.alphacamp.co/blog/prompt-engineering) - [我的大型語言模型應用開發 - 學習歷程 - ALPHA Camp](https://tw.alphacamp.co/blog/ted-chen-my-journey-in-developing-llm-applications) - [看影片學習 AI 知識與最新趨勢,為你精選四個 YouTube 頻道 - ALPHA Camp](https://tw.alphacamp.co/blog/four-selected-youtube-channels-for-learning-ai) - [AI工程師是什麼?生成式AI工程師要掌握哪些技能? - ALPHA Camp](https://tw.alphacamp.co/blog/ai-engineer) #### Medium Articles - [ChiChieh Huang – Medium](https://medium.com/@cch.chichieh) #### Course/HandBook ##### Google AI Courses for Free - [Beginner: Introduction to Generative AI Learning Path](https://www.cloudskillsboost.google/paths/118?locale=zh_TW) - [Machine Learning | Resources | Google for Developers](https://developers.google.com/machine-learning/resources?hl=zh-tw) - [Machine Learning Crash Course](https://developers.google.com/machine-learning/crash-course/prereqs-and-prework?hl=zh-cn) ##### Microsoft - [Microsoft Learn](https://learn.microsoft.com/en-us/training/paths/intro-generative-ai-for-trainers/) - [Generative AI for Beginners (microsoft.github.io)](https://microsoft.github.io/generative-ai-for-beginners/#/) #### 國網中心(NCHC)教學 - 快速了解模型訓練原理:[Taichung.py 2024/04/23 Meetup, 在自己的電腦上建立專屬大型語言模型知識庫機器人 - YouTube](https://www.youtube.com/watch?v=agdWJBQKlEE) - [大型語言模型LLMs介紹與操作教學 20231228 - YouTube](https://www.youtube.com/watch?v=Y0OrawaP1Aw&t=6560s) - [大型語言模型-\[初階\]建立基於RAG方案的專屬私有知識庫教學 - YouTube](https://www.youtube.com/watch?v=VQKgPJSYtqE&t=39s) - [大型語言模型-\[初階\]建立基於RAG方案的專屬私有知識庫教學 Q&A - YouTube](https://www.youtube.com/watch?v=7wXXTJhXKoY) #### LLM Tokenizer 分詞器 - [OpenAI Platform](https://platform.openai.com/tokenizer) - [The Tokenizer Playground - a Hugging Face Space by Xenova](https://huggingface.co/spaces/Xenova/the-tokenizer-playground) #### PyImageSearch 教學 (英文) - 1: [Harnessing Power at the Edge: An Introduction to Local Large Language Models - PyImageSearch](https://pyimagesearch.com/2024/05/13/harnessing-power-at-the-edge-an-introduction-to-local-large-language-models/) - 2: [Inside Look: Exploring Ollama for On-Device AI - PyImageSearch](https://pyimagesearch.com/2024/05/20/inside-look-exploring-ollama-for-on-device-ai/) - 3: [Integrating Local LLM Frameworks: A Deep Dive into LM Studio and AnythingLLM - PyImageSearch](https://pyimagesearch.com/2024/06/24/integrating-local-llm-frameworks-a-deep-dive-into-lm-studio-and-anythingllm/) - 4: [Exploring Oobabooga Text Generation Web UI: Installation, Features, and Fine-Tuning Llama Model with LoRA - PyImageSearch](https://pyimagesearch.com/2024/07/01/exploring-oobabooga-text-generation-web-ui-installation-features-and-fine-tuning-llama-model-with-lora/) #### AI 各類資源大匯集 - [Toolify.ai](https://www.toolify.ai/tw/) - 收集各種不同類型的 AI 應用網站目錄與詳細資訊 - [全世界最好的中文LLM资料总结](https://github.com/WangRongsheng/awesome-LLM-resourses) - [llm-course](https://github.com/andysingal/llm-course) - 收集了大量各項有關 AI 的資源,適合進階開發者來這挖寶。 - [各類 中文 LLM 總整理](https://github.com/HqWu-HITCS/Awesome-Chinese-LLM) - [Open Source LLM Tools](https://huyenchip.com/llama-police) - [Awesome LLM Apps](https://github.com/Shubhamsaboo/awesome-llm-apps) - [Awesome local LLM](https://github.com/rafska/Awesome-local-LLM) - 各種模型、推論引擎與各式工具資源 #### AI Research Paper - [arXiv](https://arxiv.org/) - [JMLR](https://www.jmlr.org/) - [JAIR](https://www.jair.org/index.php/jair) - [AI Magazine](https://aaai.org/ai-magazine/) #### AI News - [Analytics Insight(opens in a new tab)](https://www.analyticsinsight.net/) 提供見解、最新消息和雜誌,其中介紹業界頂尖領導者和高階主管的觀點和看法,分享他們的歷程、經驗、成功故事和知識,以協助企業壯大發展。 - [Towards Data Science(opens in a new tab)](https://towardsdatascience.com/) 是一份線上出版物,遵守其規則和指南的獨立作者可以在 [Medium(opens in a new tab)](https://medium.com/) 上發表自己的作品,分享自己的知識和專業,並吸引廣泛的觀眾。 - [KDnuggets(opens in a new tab)](https://www.kdnuggets.com/) 是一個關於資料科學、機器學習、AI 和分析的領先網站。 它包含出色的教學課程資料、課程、網路研討會、線上活動。 - [Data Science Central(opens in a new tab)](https://www.datasciencecentral.com/) 是專門提供給資料從業人員的領先線上資源。 從統計資料和分析到機器學習和 AI,Data Science Central 提供社群經驗,包括豐富的編輯平台、社交互動、論壇型支援,以及有關技術、工具、趨勢和職涯的最新資訊。 - [Datanami(opens in a new tab)](https://www.datanami.com/) 是一個新聞入口網站,其致力於提供有關大數據新趨勢和解決方案的見解、分析及最新資訊。 #### 資策會 下載指引:[下載專區 | 資策會 (iii.org.tw)](https://www.iii.org.tw/Publish/DownloadPages.aspx?fm_sqno=42&dp_bookClass_All=2,4) - 生成式AI企業大腦開發指引 - 生成式AI輔助之軟體開發指引 - 2023企業應具備的AI素養-生成式AI導入指引 #### Open Source MLOps platform - [Pezzo](https://github.com/pezzolabs/pezzo) - A fully cloud-native and open-source LLMOps platform. Seamlessly observe and monitor your AI operations, troubleshoot issues, save up to 90% on costs and latency, collaborate and manage your prompts in one place, and instantly deliver AI changes. - [MLflow](https://mlflow.org/) - Build better models and generative AI apps on a unified, end-to-end, open source MLOps platform #### LLM 面試問答 - [LLM Interview Questions and Answers Hub](https://github.com/KalyanKS-NLP/LLM-Interview-Questions-and-Answers-Hub) #### Cheat Sheets ##### Types of AI models [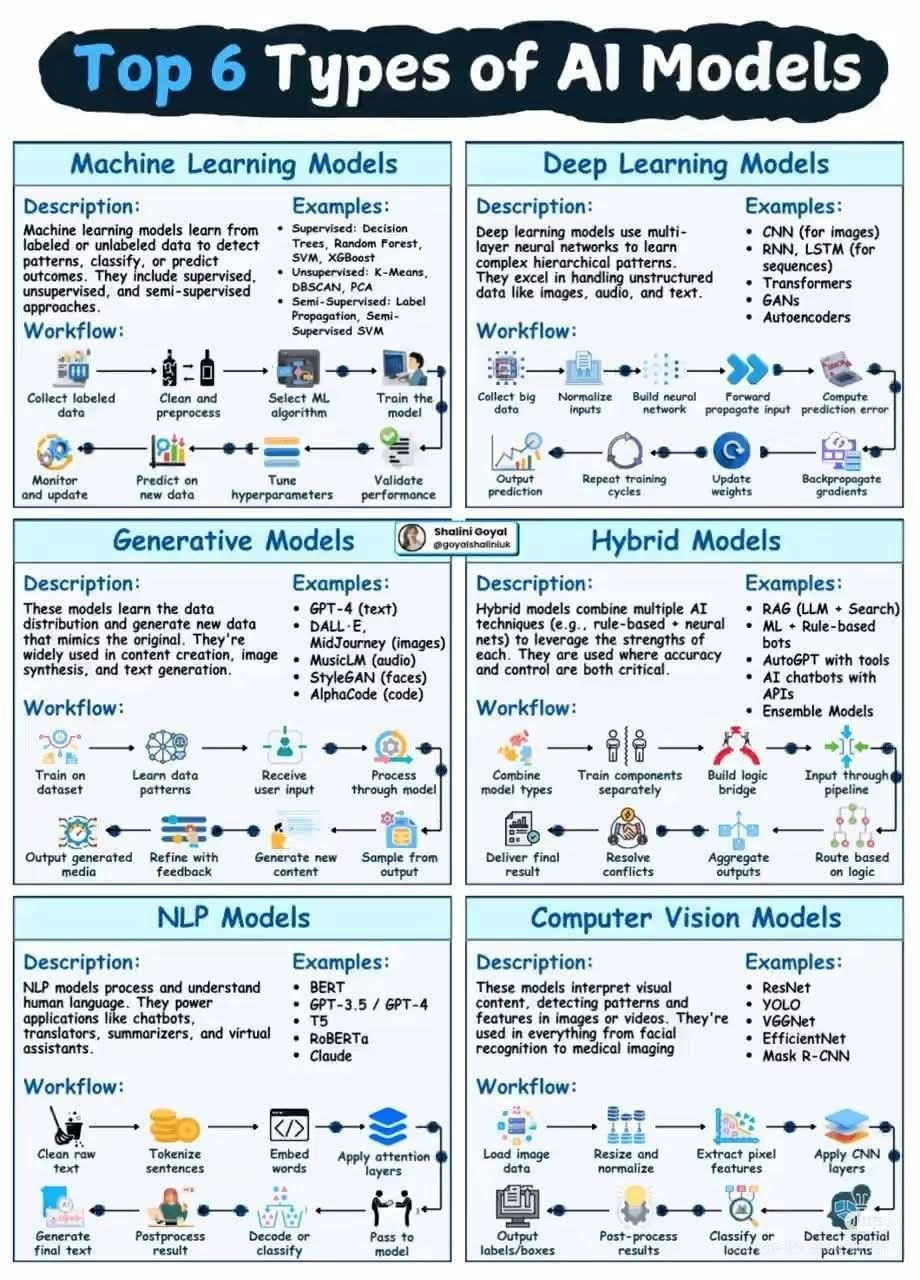](https://osslab.tw/uploads/images/gallery/2025-09/types-of-ai-models.jpeg) # RedHat AI Red Hat® Enterprise Linux® AI is a foundation model platform to seamlessly develop, test, and run Granite family large language models (LLMs) for enterprise applications.AnythingLLM 也有自架網站版,見文章下方的連結。
You can install AnythingLLM as a Desktop Application, Self Host it locally using Docker and Host it on cloud (aws, google cloud, railway etc..) using Docker You want AnythingLLM Desktop if... - You want a one-click installable app to use local LLMs, RAG, and Agents locally - You do not need multi-user support - Everything needs to stay only on your device - You do not need to "publish" anything to the public internet. Eg: Chat widget for website ##### URLs - [https://useanything.com/](https://useanything.com/) - Doc: [https://docs.useanything.com/](https://docs.useanything.com/) - 自架網站:[Mintplex-Labs/anything-llm](https://github.com/Mintplex-Labs/anything-llm) # Ollama Run Llama 3, Phi 3, Mistral, Gemma, and other models. Customize and create your own. - [https://ollama.com/](https://ollama.com/) - GitHub: [https://github.com/ollama/ollama](https://github.com/ollama/ollama) - Doc: [https://github.com/ollama/ollama/tree/main/docs](https://github.com/ollama/ollama/tree/main/docs) - Video: [離線不怕隱私外洩!免費開源 AI 助手 Ollama 從安裝到微調,一支影片通通搞定! - YouTube](https://www.youtube.com/watch?v=JpQC0W91E6k) #### Installation ##### ollama + open webui ```bash mkdir ollama-data download open-webui-data ``` docker-compose.yml: ```yaml services: ollama: image: ollama/ollama:latest ports: - 11434:11434 volumes: - ./ollama-data:/root/.ollama - ./download:/download container_name: ollama pull_policy: always tty: true restart: always networks: - ollama-docker open-webui: image: ghcr.io/open-webui/open-webui:main container_name: open-webui volumes: - ./open-webui-data:/app/backend/data depends_on: - ollama ports: - 3000:8080 environment: - 'OLLAMA_BASE_URL=http://ollama:11434' extra_hosts: - host.docker.internal:host-gateway restart: unless-stopped networks: - ollama-docker networks: ollama-docker: external: false ``` ##### ollama ```bash mkdir ollama-data download docker run --name ollama -d --rm \ -v $PWD/ollama-data:/root/.ollama \ -v $PWD/download:/download \ -p 11434:11434 \ ollama/ollama ``` ##### K8s Deployment - [Ollama Kubernetes: Run AI Models Seamlessly on K8s](https://collabnix.com/running-ollama-on-kubernetes/) - [Ollama Kubernetes 部署配置全攻略 从零开始搭建私有大模型集群 解决资源调度与服务暴露难题 - 云原生实践](https://www.oryoy.com/news/ollama-kubernetes-bu-shu-pei-zhi-quan-gong-lve-cong-ling-kai-shi-da-jian-si-you-da-mo-xing-ji-qun-ji.html) - [在 Kubernetes 上部署 llama3 | Kubernetes 实践指南](https://imroc.cc/kubernetes/cases/llama3) - [Enable GPU Support in Kubernetes: Complete Guide](https://collabnix.com/how-to-enable-gpu-support-nvidia-amd-in-kubernetes-for-ollama-complete-guide/) 1\. 啟用 *hostpath-storage* ```bash microk8s enable hostpath-storage microk8s status ``` Verify the Storage Class ``` ❯ kubectl get storageclass NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE microk8s-hostpath (default) microk8s.io/hostpath Delete WaitForFirstConsumer false 17m ``` 2\. `ollama-pvc.yaml` : - PVC 建立後,狀態會保持 *Pending*,直到有其他物件掛載,才會顯示 *Bound*。 - PersistentVolume 會自動建立,名稱由系統自動命名。 ```yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: ollama-pvc namespace: ollama spec: accessModes: - ReadWriteOnce resources: requests: storage: 3Gi ``` 3\. `ollama-deployment.yaml` : ```yaml apiVersion: apps/v1 kind: Deployment metadata: name: ollama namespace: ollama spec: replicas: 1 selector: matchLabels: app: ollama template: metadata: labels: app: ollama spec: containers: - name: ollama image: ollama/ollama:latest env: - name: OLLAMA_HOST value: 0.0.0.0:11434 ports: - name: http containerPort: 11434 protocol: TCP volumeMounts: - name: ollama-data mountPath: /root/.ollama volumes: - name: ollama-data persistentVolumeClaim: claimName: ollama-pvc ``` 4\. `ollama-svc.yaml` : ```yaml apiVersion: v1 kind: Service metadata: name: ollama-service namespace: ollama spec: selector: app: ollama ports: - protocol: TCP port: 11434 targetPort: 11434 type: ClusterIP ``` Testing with curl ```bash curl -s http://Recommend using a Python Virtual Environment
``` pip install openllm ``` ##### Start a LLM Server ```bash openllm start microsoft/Phi-3-mini-4k-instruct --trust-remote-code ``` To interact with the server, you can visit the web UI at http://localhost:3000/ or send a request using curl. You can also use OpenLLM’s built-in Python client to interact with the server: ```python import openllm client = openllm.HTTPClient('http://localhost:3000') client.generate('Explain to me the difference between "further" and "farther"') ``` ##### OpenAI Compatible Endpoints ```python import openai client = openai.OpenAI(base_url='http://localhost:3000/v1', api_key='na') # Here the server is running on 0.0.0.0:3000 completions = client.chat.completions.create( prompt='Write me a tag line for an ice cream shop.', model=model, max_tokens=64, stream=stream ) ``` ##### LangChain ```python from langchain.llms import OpenLLMAPI llm = OpenLLMAPI(server_url='http://44.23.123.1:3000') llm.invoke('What is the difference between a duck and a goose? And why there are so many Goose in Canada?') # streaming for it in llm.stream('What is the difference between a duck and a goose? And why there are so many Goose in Canada?'): print(it, flush=True, end='') # async context await llm.ainvoke('What is the difference between a duck and a goose? And why there are so many Goose in Canada?') # async streaming async for it in llm.astream('What is the difference between a duck and a goose? And why there are so many Goose in Canada?'): print(it, flush=True, end='') ``` # Bechmark Benchmark for LLM engines ##### bench.py - [ollama 支持并发之后和 vllm 相比性能如何?我们测测看\_ollama vllm-CSDN博客](https://blog.csdn.net/arkohut/article/details/139076652) - YT: [ollama vs vllm - 开启并发之后的 ollama 和 vllm 相比怎么样? - YouTube](https://www.youtube.com/watch?v=6eS0Ook8FMg) ```python import aiohttp import asyncio import time from tqdm import tqdm import random questions = [ "Why is the sky blue?", "Why do we dream?", "Why is the ocean salty?", "Why do leaves change color?", "Why do birds sing?", "Why do we have seasons?", "Why do stars twinkle?", "Why do we yawn?", "Why is the sun hot?", "Why do cats purr?", "Why do dogs bark?", "Why do fish swim?", "Why do we have fingerprints?", "Why do we sneeze?", "Why do we have eyebrows?", "Why do we have hair?", "Why do we have nails?", "Why do we have teeth?", "Why do we have bones?", "Why do we have muscles?", "Why do we have blood?", "Why do we have a heart?", "Why do we have lungs?", "Why do we have a brain?", "Why do we have skin?", "Why do we have ears?", "Why do we have eyes?", "Why do we have a nose?", "Why do we have a mouth?", "Why do we have a tongue?", "Why do we have a stomach?", "Why do we have intestines?", "Why do we have a liver?", "Why do we have kidneys?", "Why do we have a bladder?", "Why do we have a pancreas?", "Why do we have a spleen?", "Why do we have a gallbladder?", "Why do we have a thyroid?", "Why do we have adrenal glands?", "Why do we have a pituitary gland?", "Why do we have a hypothalamus?", "Why do we have a thymus?", "Why do we have lymph nodes?", "Why do we have a spinal cord?", "Why do we have nerves?", "Why do we have a circulatory system?", "Why do we have a respiratory system?", "Why do we have a digestive system?", "Why do we have an immune system?" ] async def fetch(session, url): """ 参数: session (aiohttp.ClientSession): 用于请求的会话。 url (str): 要发送请求的 URL。 返回: tuple: 包含完成 token 数量和请求时间。 """ start_time = time.time() # 随机选择一个问题 question = random.choice(questions) # <--- 这两个必须注释一个 # 固定问题 # question = questions[0] # <--- 这两个必须注释一个 # 请求的内容 json_payload = { "model": "llama3:8b-instruct-fp16", "messages": [{"role": "user", "content": question}], "stream": False, "temperature": 0.7 # 参数使用 0.7 保证每次的结果略有区别 } async with session.post(url, json=json_payload) as response: response_json = await response.json() end_time = time.time() request_time = end_time - start_time completion_tokens = response_json['usage']['completion_tokens'] # 从返回的参数里获取生成的 token 的数量 return completion_tokens, request_time async def bound_fetch(sem, session, url, pbar): # 使用信号量 sem 来限制并发请求的数量,确保不会超过最大并发请求数 async with sem: result = await fetch(session, url) pbar.update(1) return result async def run(load_url, max_concurrent_requests, total_requests): """ 通过发送多个并发请求来运行基准测试。 参数: load_url (str): 要发送请求的URL。 max_concurrent_requests (int): 最大并发请求数。 total_requests (int): 要发送的总请求数。 返回: tuple: 包含完成 token 总数列表和响应时间列表。 """ # 创建 Semaphore 来限制并发请求的数量 sem = asyncio.Semaphore(max_concurrent_requests) # 创建一个异步的HTTP会话 async with aiohttp.ClientSession() as session: tasks = [] # 创建一个进度条来可视化请求的进度 with tqdm(total=total_requests) as pbar: # 循环创建任务,直到达到总请求数 for _ in range(total_requests): # 为每个请求创建一个任务,确保它遵守信号量的限制 task = asyncio.ensure_future(bound_fetch(sem, session, load_url, pbar)) tasks.append(task) # 将任务添加到任务列表中 # 等待所有任务完成并收集它们的结果 results = await asyncio.gather(*tasks) # 计算所有结果中的完成token总数 completion_tokens = sum(result[0] for result in results) # 从所有结果中提取响应时间 response_times = [result[1] for result in results] # 返回完成token的总数和响应时间的列表 return completion_tokens, response_times if __name__ == '__main__': import sys if len(sys.argv) != 3: print("Usage: python bench.py只能執行本地模型,不支援外部模型 API。
支援以下多重功能的 AI 平台 - Chat - Fine-Tune Model - Multiple model backends: Transformers, llama.cpp (through llama-cpp-python), ExLlamaV2, AutoGPTQ, AutoAWQ, GPTQ-for-LLaMa, QuIP#. - OpenAI-compatible API server with Chat and Completions endpoints 教學 - GitHub: [https://github.com/oobabooga/text-generation-webui](https://github.com/oobabooga/text-generation-webui) - GitHub: [https://github.com/Atinoda/text-generation-webui-docker](https://github.com/Atinoda/text-generation-webui-docker) - [大型語言模型LLMs課程教學 課程大綱 (三) - HackMD](https://hackmd.io/@whYPD8MBSHWRZV6y-ymFwQ/HkHz7qvw6) - YOUTUBE \[[啟動 TextGen](https://youtu.be/I-oLK-Olh7o)\] - YOUTUBE \[[上架大型語言模型](https://youtu.be/6Ual2nd4ezU)\] - YOUTUBE \[[指派AI人設](https://www.youtube.com/watch?v=Vx1tjNs9q-k)\] - YOUTUBE \[[模型微調](https://www.youtube.com/watch?v=LyWJtdJ9olc)\] - YOUTUBE \[[上架微調模型](https://www.youtube.com/watch?v=p2k1RjtJeS4)\] - 程式碼 [Z01\_TextGen\_Colab.ipynb](https://colab.research.google.com/github/c00cjz00/llm_course_20231228/blob/main/Z01_TextGen_Colab.ipynb) - 預設密碼在程式碼裡面 (account:nchc password:nchc) 請自行修改 ##### koboldcpp - GitHub: [https://github.com/LostRuins/koboldcpp](https://github.com/LostRuins/koboldcpp) - 單機版運行/免安裝/無相依姓套件 - 支援 GGUF 模型 - 支援 OuteTTS (Text-To-Speech), Whisper (Speech-To-Text), 文字/圖像生成 - 內建 KoboldAI Lite UI # Llama.Cpp GitHub: [https://github.com/ggml-org/llama.cpp](https://github.com/ggml-org/llama.cpp) ##### Tutorials - [Windows 本地 AI 又升级了!llama.cpp 官方支持 CUDA 13 / Vulkan / HIP / SYCL,一键跑 GGUF 无审查模型! - 零度博客](https://www.freedidi.com/24211.html) # AI Translator 使用 LLM 實現語言翻譯 - [Translation Quality Benchmark](https://github.com/hydropix/TranslateBooksWithLLMs/wiki) #### Huyuan-MT Huyuan-MT - 支援 33 種語言和 5 種中文方言 - GitHub: [https://github.com/Tencent-Hunyuan/Hunyuan-MT/](https://github.com/Tencent-Hunyuan/Hunyuan-MT/) - HF: [https://huggingface.co/tencent/Hunyuan-MT-7B](https://huggingface.co/tencent/Hunyuan-MT-7B) #### PDFMathTranslate 完整保留排版的 PDF 檔案全文雙語翻譯,支援 Google/DeepL/Ollama/OpenAI 翻譯。 - GitHub: [https://github.com/Byaidu/PDFMathTranslate](https://github.com/Byaidu/PDFMathTranslate) #### LiteLLM + 反思提示 + 工作流 - GitHub: [https://github.com/wshuyi/workflows\_with\_litellm\_pub](https://github.com/wshuyi/workflows_with_litellm_pub) #### Translation Agent - GitHub: [https://github.com/andrewyng/translation-agent](https://github.com/andrewyng/translation-agent) #### RTranslator RTranslator is an ([almost](https://github.com/niedev/RTranslator?tab=readme-ov-file#libraries-and-models)) open-source, free, and offline real-time translation app for Android. - GitHub: [https://github.com/niedev/RTranslator](https://github.com/niedev/RTranslator) #### 沉浸式翻譯 一款免費的,好用的,沒有廢話的,革命性的,飽受讚譽的,AI 驅動的雙語網頁翻譯擴展,幫助你有效地打破資訊差,在手機上也可以用! - [沉浸式翻譯- 雙語對照網頁翻譯外掛\_PDF文件翻譯工具](https://immersivetranslate.com/zh-TW/) - [FluentRead](https://github.com/Bistutu/FluentRead) - 流畅阅读是一款高效的浏览器翻译插件 #### 影片/字幕 ##### - pyVideoTrans视频翻译配音 一键字幕生成+字幕翻译+创建配音+合成 = 带字幕和配音的新视频 - [视频翻译配音pyVideoTrans | 视频翻译配音pyVideoTrans](https://pyvideotrans.com/) - GitHub: [https://github.com/jianchang512/pyvideotrans](https://github.com/jianchang512/pyvideotrans) - 模型下載:[faster-whisper-large-v3-turbo](https://huggingface.co/dropbox-dash/faster-whisper-large-v3-turbo/tree/main) ##### - VideoLingo Netflix级字幕切割、翻译、对齐、甚至加上配音,一键全自动视频搬运AI字幕组 - [VideoLingo](https://docs.videolingo.io/) - GitHub: [https://github.com/Huanshere/VideoLingo](https://github.com/Huanshere/VideoLingo) ##### - SubtitleEdit 使用 .Net 開發,適合 Windows 用戶,AI 生成/翻譯字幕,字幕編輯功能豐富。 - [Nikse - Subtitle Edit - Help/FAQ](https://www.nikse.dk/subtitleedit/help) - GitHub: [https://github.com/SubtitleEdit/subtitleedit](https://github.com/SubtitleEdit/subtitleedit) - YT: [【老司機必備】最好用的字幕翻譯工具|免費開源|Subtitle Edit 使用教學|PotPlayer、VLC、MPV - YouTube](https://www.youtube.com/watch?v=Vq_gphex0fA) - YT: [宅男福利!用Subtitle Edit给原生日语大片加实时中文字幕,超详细教程 - YouTube](https://www.youtube.com/watch?v=Kmj31OPc6UE) - YT: [【告别剪映收费】2款永久免费/本地部署AI字幕神软!Whisper离线转文字全攻略!本地部署最强AI Whisper模型:手把手教你免费生成中英双语字幕/教你彻底白嫖!开源神器本地无限次免费生成 - YouTube](https://www.youtube.com/watch?v=39jnGj38Mso) ##### - Vibe Whisper AI 轉譯語音檔或影片檔字幕 - [https://github.com/thewh1teagle/vibe](https://github.com/thewh1teagle/vibe) ##### - VideoCaptioner - [https://github.com/WEIFENG2333/VideoCaptioner](https://github.com/WEIFENG2333/VideoCaptioner) ##### - Violin - [https://github.com/shang-zhu/violin](https://github.com/shang-zhu/violin) #### bilingual\_book\_maker 電子書翻譯 - GitHub: [https://github.com/yihong0618/bilingual\_book\_maker](https://github.com/yihong0618/bilingual_book_maker) #### MTranServer 自行部署離線的翻譯伺服器,翻譯軟體可用[沉浸式翻譯](https://immersivetranslate.com/zh-Hans/docs/services/custom/)與[簡約翻譯](https://github.com/fishjar/kiss-translator)。 - [https://github.com/xxnuo/MTranServer](https://github.com/xxnuo/MTranServer) #### AiNiee 一款專注於Ai翻譯的工具,一鍵自動翻譯RPG SLG游戲,Epub TXT小說,Srt Vtt Lrc字幕,Word MD 檔案等等復雜長文字。 - [https://github.com/NEKOparapa/AiNiee](https://github.com/NEKOparapa/AiNiee) - YT: [再也不用啃生肉了!本地部署 AI 將日文片變中文字幕【完全免費】【全流程教學】 - YouTube](https://www.youtube.com/watch?v=BRtqtO0By9g) #### Pot 一個跨平台的劃詞翻譯軟體 - [https://pot-app.com/](https://pot-app.com/) - [https://github.com/pot-app/pot-desktop](https://github.com/pot-app/pot-desktop) #### OpenAI Translator [OpenAI Translator](https://github.com/openai-translator/openai-translator) - 基於 ChatGPT API 的翻譯擴充功能,Chrome、Edge 都能用 - [Chrome Extension](https://chrome.google.com/webstore/detail/openai-translator/ogjibjphoadhljaoicdnjnmgokohngcc) #### Argos Translate Open source neural machine translation - [Argos Open Tech](https://www.argosopentech.com/) - GitHub: [https://github.com/argosopentech/argos-translate](https://github.com/argosopentech/argos-translate) #### TranslateGemma TranslateGemma 是一套以 Google Gemma 3 模型為基礎建立的全新開放式翻譯模型,提供 40 億(4B)、120 億(12B)、270 億(27B)三種參數規模的版本,幫助人們無論身在何處、使用何種裝置,能夠跨越 55 種語言進行交流。 - [TranslateGemma: A new family of open translation models](https://blog.google/innovation-and-ai/technology/developers-tools/translategemma/) - [Google開源TranslateGemma翻譯模型,支援55種語言 | iThome](https://www.ithome.com.tw/news/173416) # Jupyter Notebook #### Installation With pip ```bash pip install notebook ``` ##### Python Virtual Environment With Python Venv ```bash mkdir my-rag cd my-rag python -m venv .venv source .venv/bin/activate (my-rag)> pip install --upgrade pip (my-rag)> pip install notebook (my-rag)> jupyter notebook ``` With Conda ```bash conda create -n my-rag python=3.10 conda activate my-rag (my-rag)> pip install --upgrade pip (my-rag)> pip install notebook (my-rag)> jupyter notebook ``` UI 可切換不同虛擬環境(需要先建立不同的 ipykernel) ```bash mkdir my-rag cd my-rag python -m venv .venv source .venv/bin/activate (my-rag)> pip install --upgrade pip (my-rag)> pip install ipykernel (my-rag)> ipython kernel install --user --name="my-rag-kernel" (my-rag)> jupyter notebook ``` #### Tips ##### Secure Authentication 1. In the top menu bar of the notebook editor, select `Add-ons` then `Secrets`. 2. Create a new secret with the label `GOOGLE_API_KEY`. 3. Paste your API key into the "Value" field and click "Save". 4. Ensure that the checkbox next to `GOOGLE_API_KEY` is selected so that the secret is attached to the notebook. ```python import os from kaggle_secrets import UserSecretsClient try: GOOGLE_API_KEY = UserSecretsClient().get_secret("GOOGLE_API_KEY") os.environ["GOOGLE_API_KEY"] = GOOGLE_API_KEY print("✅ Gemini API key setup complete.") except Exception as e: print( f"🔑 Authentication Error: Please make sure you have added 'GOOGLE_API_KEY' to your Kaggle secrets. Details: {e}" ) ``` #### Resources - [Online Test](https://jupyter.org/try-jupyter/lab/) - [nbviewer](https://nbviewer.org/) - A simple way to share Jupyter Notebooks ##### CoLab by Google - [Google Colab](https://colab.research.google.com/) is Jupyter Notebooks that are hosted by Google’s Colaboratory - [Overview of Colaboratory Features](https://colab.research.google.com/notebooks/basic_features_overview.ipynb) - [Installing and using Python libraries in Colab](https://colab.research.google.com/notebooks/snippets/importing_libraries.ipynb) - [Using Google Colab with GitHub](https://colab.research.google.com/github/googlecolab/colabtools/blob/main/notebooks/colab-github-demo.ipynb) - [Google Colab Tips for Power Users](https://amitness.com/posts/google-colab-tips) # LangChain LangChain 是一個旨在為開發者提供一套工具和程式介接,以便更容易、更有效地利用大型語言模型(LLM)的開源開發框架,專注於情境感知和推理。它包含多個組件,如 Python 和 JavaScript 的函式庫、快速部署的模板、用於開發REST API的 LangServe,以及用於除錯和監控的 LangSmith。LangChain 簡化了開發、生產和部署過程,提供與語言模型互動、執行檢索策略和輔助建立複雜應用架構的工具。 - [Introduction | 🦜️🔗 LangChain](https://python.langchain.com/docs/get_started/introduction) - [LangChain是什麼?AI開發者必須了解的LLM開源框架 - ALPHA Camp](https://tw.alphacamp.co/blog/langchain-intro) - GitHub: [https://github.com/langchain-ai/langchain](https://github.com/langchain-ai/langchain) - Hub: [LangSmith (langchain.com)](https://smith.langchain.com/hub) - 教學:[sugarforever/wtf-langchain](https://github.com/sugarforever/wtf-langchain) - [CookBook](https://github.com/langchain-ai/langchain/tree/master/cookbook) - [LangChain Templates](https://templates.langchain.com/) #### LangSmith LangChain 提供的雲端服務,可用來作程式除錯與監視後端程序,例如 RAG 的檢索資訊過程。 - [https://github.com/langchain-ai/langsmith-cookbook](https://github.com/langchain-ai/langsmith-cookbook) - [LangChain 怎麼玩?用 LangSmith 幫忙追查問題 - MyApollo](https://myapollo.com.tw/blog/langchain-langsmith/) - [深入LangSmith:如何帮助大模型(LLM)应用从原型到投入生产?【上】 - 文章 - 开发者社区 - 火山引擎](https://developer.volcengine.com/articles/7370375414524411931) #### RAG - [Learn RAG with Langchain](https://sakunaharinda.xyz/) ([ipynb](https://github.com/sakunaharinda/ragatouille-book/tree/main/book)) - [LangChain: A Complete Guide & Tutorial (nanonets.com)](https://nanonets.com/blog/langchain/) - [Meta-Llama CookBook for RAG](https://github.com/meta-llama/llama-recipes/blob/main/recipes/quickstart/RAG/hello_llama_cloud.ipynb) (ipynb) - [LangChain and Streamlit RAG | Medium](https://medium.com/snowflake/langchain-and-streamlit-rag-c5f53af8f6ba) - GitHub: [https://github.com/streamlit/example-app-langchain-rag](https://github.com/streamlit/example-app-langchain-rag) ##### Retrievers in LCEL ```python from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough template = """Answer the question based only on the following context: {context} Question: {question} """ prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() def format_docs(docs): return "\n\n".join([d.page_content for d in docs]) chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | model | StrOutputParser() ) chain.invoke("What did the president say about technology?") ``` #### ChatPromptTemplate ```python few_shot_examples = [ {"input":"Could you please clarify the terms outlined in section 3.2 of the contract?", "output":"Certainly, I will provide clarification on the terms in section 3.2."}, {"input":"We are interested in extending the payment deadline to 30 days instead of the current 15 days. Additionally, we would like to add a clause regarding late payment penalties.", "output":"Our request is to extend the payment deadline to 30 days and include a clause on late payment penalties."}, {"input":"""The current indemnification clause seems too broad. We would like to narrow it down to cover only direct damages and exclude consequential damages. Additionally, we propose including a dispute resolution clause specifying arbitration as the preferred method of resolving disputes.""", "output":"""We suggest revising the indemnification clause to limit it to covering direct damages and excluding consequential damages. Furthermore, we recommend adding a dispute resolution clause that specifies arbitration as the preferred method of resolving disputes."""}, {"input":"I believe the proposed changes are acceptable.", "output":"Thank you for your feedback. I will proceed with implementing the proposed changes."} ] few_shot_template = ChatPromptTemplate.from_messages( [ ("human", "{input}"), ("ai", "{output}") ] ) few_shot_prompt = FewShotChatMessagePromptTemplate( example_prompt=few_shot_template, examples=few_shot_examples, ) print(few_shot_prompt.format()) ``` ```python custom_prompt = ChatPromptTemplate.from_template(""" You are an information extraction assistant. Read the text below and identify important entities. **Extraction rules:** - Always extract the **Report Id** (this is the central node). - Extract **people**, **institutions**, **places**, **dates**, **monetary amounts**, and **vehicle registration numbers** (e.g., MH12AB1234, PK-02-4567, KA05MG2020). - Do not ignore any people names; extract all mentioned in the document, even if they seem minor or role not clear. Treat all of types of vehicles (eg; cars, bikes etc) as the same kind of entity called "Vehicle". **Output format:** 1. List all nodes (unique entities). 2. Identify the central node (Report Id). 3. Create relationships of the form: (Report Id)-[HAS_ENTITY]->(Entity), 4. Do not create any other types of relationships. Text: {input} Return only structured data like: Nodes: - Report SYN-REP-2024 - Honda bike ABCD1234 - XYZ College, Chennai - ... """) ``` #### Input Data Loader ##### Web ```python from langchain_community.document_loaders import WebBaseLoader loader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs=dict( parse_only=bs4.SoupStrainer( class_=("post-content", "post-title", "post-header") ) ), ) docs = loader.load() ``` ##### Text file ```python from langchain_community.document_loaders import DirectoryLoader loader = DirectoryLoader("../", glob="**/*.md") docs = loader.load() len(docs) print(docs[0].page_content[:100]) ``` ```python from langchain.document_loaders import TextLoader dataset_folder_path='/path/to/dataset/' documents=[] for file in os.listdir(dataset_folder_path): loader=TextLoader(dataset_folder_path+file) documents.extend(loader.load()) print(documents[:3]) ``` ##### Markdown file ```python ''' %pip install "unstructured[md]" ''' from langchain_community.document_loaders import UnstructuredMarkdownLoader markdown_path = "../../../README.md" loader = UnstructuredMarkdownLoader(markdown_path) data = loader.load() assert len(data) == 1 readme_content = data[0].page_content print(readme_content[:3]) ``` ##### PDF + Text file ```python from langchain_community.document_loaders import TextLoader from langchain_community.document_loaders import PyPDFLoader documents = [] for filename in SAMPLEDATA: path = os.path.join(os.getcwd(), filename) if filename.endswith(".pdf"): loader = PyPDFLoader(path) new_docs = loader.load_and_split() print(f"Processed pdf file: {filename}") elif filename.endswith(".txt"): loader = TextLoader(path) new_docs = loader.load_and_split() print(f"Processed txt file: {filename}") else: print(f"Unsupported file type: {filename}") if len(new_docs) > 0: documents.extend(new_docs) SAMPLEDATA = [] print(f"\nProcessing done.") ``` #### OCR - [A Simple Guide to OCR with Vision LLMs, LangChain, and Ollama | by Andreas Klos | Medium](https://medium.com/@a-klos/a-simple-guide-to-ocr-with-vision-llms-langchain-and-ollama-2dc5c15660d4) #### 常用函式 格式化輸出 ```python # Helper function for printing docs def pretty_print_docs(docs): print( f"\n{'-' * 100}\n".join( [f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)] ) ) ``` # Finance AI ##### OpenBB Investment research made easy with AI. - [Investment Research | OpenBB](https://www.openbb.co/) - GitHub: [openbb-agents](https://github.com/OpenBB-finance/openbb-agents) - GitHub: [OpenBB Platform](https://github.com/OpenBB-finance/OpenBB/tree/develop/openbb_platform) ##### StockBot - GitHub: [https://github.com/bklieger-groq/stockbot-on-groq](https://github.com/bklieger-groq/stockbot-on-groq) ##### FinGPT - [AI4Finance-Foundation.org - FinGPT, FinRobot, FinRL, AI Agent, FinLLMs, Open-Source Libraries](https://ai4finance.org/) - [https://github.com/AI4Finance-Foundation/FinGPT](https://github.com/AI4Finance-Foundation/FinGPT) ##### TradingAgents TradingAgents Framework 這是一套模仿真實交易公司運作的多智能體大型語言模型(LLM)系統,為自動化交易提供了更具動態性且符合現實組織邏輯的新路徑。 - GitHub: [https://github.com/TauricResearch/TradingAgents](https://github.com/TauricResearch/TradingAgents) - YT: [AI 炒股智能體上線:為什麼它能打敗傳統策略? - YouTube](https://www.youtube.com/watch?v=sz9yXez70lI) - [TradingAgents 中文增强版](https://github.com/hsliuping/TradingAgents-CN) ##### MCP Servers Access the official remote MCP server for Financial Datasets. - [MCP Server - Financial Datasets](https://docs.financialdatasets.ai/mcp-server) ##### 股票智能分析系统 基於 LLM 的多市場股票智能分析系統,支援 A 股 / 港股 / 美股 / 日股 / 韓股自選股分析。 能把行情、K 線、技術指標、資金流、籌碼、新聞、公告、基本面等信息聚合起來,再自動生成結構化的「決策儀表盤」。 核心結論、評分、趨勢判斷、風險警報、催化因素、操作檢查清單,都能一併看清。 - GitHub: [https://github.com/ZhuLinsen/daily\_stock\_analysis](https://github.com/ZhuLinsen/daily_stock_analysis) ##### Awesome Finance Skills 一系列開源免費的金融分析Agent Skills - [https://github.com/RKiding/Awesome-finance-skills](https://github.com/RKiding/Awesome-finance-skills) ##### Kronos 首個面向金融K線圖的開源基礎模型, 基於全球超過45家交易所的數據訓練而成。 - [https://www.zdoc.app/zh/shiyu-coder/Kronos](https://www.zdoc.app/zh/shiyu-coder/Kronos) ##### Dexter 美股研究開源神器來了!專攻美股金融研究的自主 Agent! 核心優勢有以下幾點: - 自主規劃 + 執行:輸入復雜問題,它會自動拆成多個研究步驟,調用對應工具和數據源 - 自我校驗:結果不夠完整時,會繼續補數據、修正邏輯,顯著降低幻覺風險 - 完整思考日志(scratchpad):每一步調用了什麼工具、拿了什麼數據、怎麼分析的,全都透明記錄 - 多模型支持:OpenAI、Anthropic、Grok、Gemini、OpenRouter、本地 Ollama 都能接 - 金融數據能力強:支持財務報表、股價快照、歷史價格、SEC filings、earnings call、8-K、key ratios 等 - 本地輕量運行:用 Bun 安裝後就能跑,適合自己搭一個專屬美股研究 Agent 專為美股金融研究打造,深度支持美股(Financial Datasets + Yahoo Finance 提供機構級財報、earnings call、歷史數據,覆蓋非常絲滑)。 - [https://github.com/virattt/dexter](https://github.com/virattt/dexter) ##### Fincept Terminal - [FinceptTerminal — Financial Intelligence for Professionals | Free Bloomberg Alternative | FinceptTerminal](https://fincept.in/) - [https://github.com/Fincept-Corporation/FinceptTerminal](https://github.com/Fincept-Corporation/FinceptTerminal) # Semantic Kernel Semantic Kernel 是一款由微軟開放的輕量級的 AI 開發套件(框架),可讓您輕鬆建立 AI 代理,並將最新的 AI 模型整合到您的 C#、Python 或 Java 程式碼庫中。它可作為有效率的中介軟體,讓您快速交付企業級解決方案。 微軟教學: - [Introduction to Semantic Kernel | Microsoft Learn](https://learn.microsoft.com/en-us/semantic-kernel/overview/) - \[Video\]\[英文\] [在 .NET 即時上 - 超越點選:釋放 Microsoft 語意核心的強大功能](https://learn.microsoft.com/zh-tw/shows/on-net/on-dotnet-live-beyond-clicks-unleashing-the-power-of-microsoft-semantic-kernel) - GitHub: [https://github.com/microsoft/semantic-kernel](https://github.com/microsoft/semantic-kernel) 中文教學: - [Semantic Kernel的實踐:開發前準備-認識OpenAI與AOAI的模型 ](https://ithelp.ithome.com.tw/articles/10325195) - \[Video\]\[日語中字\] [https://www.youtube.com/watch?v=sByJwdJhc3s&t=45s](https://www.youtube.com/watch?v=sByJwdJhc3s&t=45s) # Legal AI 法律 AI #### Legal Assistant - [ailaw](https://github.com/hiie/ailaw) - AI 法律助手 - [律果科技](https://legalsign.ai/) - 打造出全球唯一能通過臺灣律師第一試的LLM - [練成第一款超懂臺灣法律的LLM,律果實現法務GAI應用新可能 | iThome](https://www.ithome.com.tw/people/166593) # NVIDIA - Jetson Orin Nano Super #### Hardware - NVIDIA: [Jetson Orin Nano Developer Kit User Guide - Hardware Specs | NVIDIA Developer](https://developer.nvidia.com/embedded/learn/jetson-orin-nano-devkit-user-guide/hardware_spec.html) #### JetPack SDK - NVIDIA: [JetPack SDK | NVIDIA Developer](https://developer.nvidia.com/embedded/jetpack) - NVIDIA: [Introduction to NVIDIA JetPack SDK — JetPack 6.2 documentation](https://docs.nvidia.com/jetson/archives/jetpack-archived/jetpack-62/introduction/index.html) 檢查目前 Jetpack 版本 > Tip: 先找出 L4T 版本後,前往 [https://developer.nvidia.com/embedded/jetpack-archive](https://developer.nvidia.com/embedded/jetpack-archive) 可以找出對應的 Jetpack 版本。 ```bash dpkg -l | grep 'nvidia-l4t-core' ``` #### SDK Manager 官方的 Jetson 系列設備的刷機軟體,需安裝在另一個 Linux 工作站。設備刷機前需要先切換成 Recovery Mode,並且以 USB-C 線連接 Linux 工作站與設備。 - [Jetson Orin Nano Developer Kit User Guide - Software Setup | NVIDIA Developer](https://developer.nvidia.com/embedded/learn/jetson-orin-nano-devkit-user-guide/software_setup.html) ##### Install SDK Manager 安裝方式支援 Linux、Windows、Docker 平台。 - [SDK Manager | NVIDIA Developer](https://developer.nvidia.com/sdk-manager#installation_get_started) ##### Recovery Mode 還原模式用途與特性: 1. 設備開機時會跳過正常開機程序,以最簡易環境啟動。 2. 可進行系統刷機及韌體更新作業。 切換方式:將 J14 (Button Header) 的 Pin 9-10 短路。 #### Headless Setup - NoMachine: [Jetson Remote Desktop Headless Setup Tutorial - Proventus Nova](https://proventusnova.com/nvidia-jetson-remote-desktop-headless-setup-tutorial/) ##### VNC Server - [Jetson Orin Nano Headless GUI + VNC Setup | Jetson Orin Nano Headless VNC Setup Guide](https://mauroarcidiacono.github.io/jetson-headless-vnc/) ```bash sudo apt-get update sudo apt-get install tightvncserver vncserver # Start VNC server vncserver -geometry 1980x1080 # Kill VNC Server vncserver -kill :1 ``` `~/.vnc/xstartup` : ```bash #!/bin/sh unset SESSION_MANAGER unset DBUS_SESSION_BUS_ADDRESS [ -x /etc/vnc/xstartup ] && exec /etc/vnc/xstartup [ -r $HOME/.Xresources ] && xrdb $HOME/.Xresources export XKL_XMODMAP_DISABLE=1 export XDG_CURRENT_DESKTOP="GNOME-Flashback:Unity" export XDG_MENU_PREFIX="gnome-flashback-" gnome-session --session=gnome-flashback-metacity --disable-acceleration-check & ``` #### POST-Install ##### Docker ```bash # Install the docker sudo apt update sudo apt install -y nvidia-container curl curl https://get.docker.com | sh && sudo systemctl --now enable docker sudo nvidia-ctk runtime configure --runtime=docker # Add your user to the docker group sudo systemctl restart docker sudo usermod -aG docker $USER newgrp docker # Add default runtime sudo apt install -y jq sudo jq '. + {"default-runtime": "nvidia"}' /etc/docker/daemon.json | \ sudo tee /etc/docker/daemon.json.tmp && \ sudo mv /etc/docker/daemon.json.tmp /etc/docker/daemon.json # Restart the docker sudo systemctl daemon-reload && sudo systemctl restart docker ``` #### FAQ ##### CTranslate2 Issue > CTranslate2 package was not compiled with CUDA support Solution: 從 pip 安裝的 CTranslate2 模組不支援 ARM 的平台,需要下載原始檔在 ARM 平台上重新編譯,步驟如下: 下載並編譯 ctranslate2 主程式 ```bash git clone --recursive https://github.com/OpenNMT/CTranslate2.git cd CTranslate2 mkdir build && cd build mkdir install cmake .. -DWITH_CUDA=ON -DWITH_CUDNN=ON -DWITH_MKL=OFF -DOPENMP_RUNTIME=COMP -DCMAKE_INSTALL_PREFIX=$PWD/install make -j4 make install sudo cp -r install/* /usr/local sudo ldconfig ``` 回到出現執行錯誤的專案目錄,例如 pyvideotrans,重新安裝 ctranslate2 模組,注意要使用 `--force-reinstall` 覆蓋有問題的版本。 ```bash cd ~/pyvideotrans source ~/.venv/bin/activate cd ~/CTranslate2/python pip install -r install_requirements.txt python setup.py bdist_wheel pip install dist/*.whl --force-reinstall ``` #### Links ##### Tutorials - NVIDIA: [Jetson Orin Nano Super Developer Kit | NVIDIA](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-orin/nano-super-developer-kit/) - NVIDIA: [Jetson Orin Nano Developer Kit Getting Started Guide | NVIDIA Developer](https://developer.nvidia.com/embedded/learn/get-started-jetson-orin-nano-devkit) - NVIDIA: [Introduction - NVIDIA Jetson AI Lab](https://www.jetson-ai-lab.com/tutorial-intro.html) - [官方討論區](https://forums.developer.nvidia.com/c/robotics-edge-computing/jetson-embedded-systems/jetson-nano/76) - [NVIDIA Jetson Orin Nano Super Developers Kit – Getting Started](https://dronebotworkshop.com/jetson-orin-nano/) - [Install Ubuntu on NVIDIA Jetson | Ubuntu](https://ubuntu.com/download/nvidia-jetson) ##### More hardware for AI - [Best Budget GPU for AI in Your Home Server 2025 - Virtualization Howto](https://www.virtualizationhowto.com/2025/04/best-budget-gpu-for-ai-in-your-home-server-2025/) # Image Generation #### Tutorials - [5 Open-source Local AI Tools for Image Generation I Found Interesting](https://itsfoss.com/local-ai-image-tools/) # iPAS AI 應用規劃師 # 導讀筆記 ### 人工智慧基礎概論 #### 機器學習概念 ##### - 模型評估 - 分類問題: 1. 混淆矩陣 (Confusion Matrix) 2. 準確度 / 精確率 / 召回率 3. F1-score 4. ROC 曲線 / AUC 值 - 迴歸問題: - 均方誤差 (MSE) - 平均絕對誤差 (MAE) - R 分數 (R-Squared Score) ### 生成式 AI 應用與規劃 #### 生成式 AI 導入評估規劃 ##### - 地端導入合規性 1. ISO 27001 資訊安全管理 2. ISO 42001 人工智慧管理 3. ISO 27701 隱私資訊管理 # 名詞筆記 ##### 速查表| 中 (英) 文名詞 | 說明 |
| 人工智慧 (Artificial Intelligence) | Marvin Minsky: AI 是讓機器模仿人類行為並執行有智慧行為的學科 數發部AI指引: AI 是指模擬人類智慧的機器或系統 |
| 泛化能力 (Generalization Ability) | 指機器學習模型在未⾒過的新資料上的表現能⼒。 |
| 超參數 (Hyperparameter) | 訓練模型時用來控制訓練過程的變數。哪些是有效的超參數以及超參數的最佳值,可以手動或透過超參數演算法自動調校。 |
| 遷移式學習 (Transfer Learning) | 讓已訓練完畢的 AI 模型進行知識轉移,輔以新的數據再訓練後,便可完成相似度較近的任務。遷移式學習實務上能解決小樣本訓練的課題,如可應用於如製造業瑕疵檢測。 |
| 幻覺 (Hallucination) | 指模型自信地生成了不真實的答案 (或稱: 一本正經地胡說八道)。最新研究論文指出,語言模型之所以會產生幻覺,是因為標準的訓練和評估流程更鼓勵模型去猜測,而不是承認自己的不確定性。 |
| 模型蒸餾 (Model Distillation) | 是一種「把大模型的知識搬到小模型」的技巧,讓較輕量的模型在效能上接近原本龐大的模型,同時保有更快的推論速度與更低的硬體需求。 |
| TTQA (台灣大語言模型問答) | 專⾨針對台灣繁體中文和本⼟文化設計的問答系統,旨在提供更符合台灣使⽤者需求的 AI 服務。 |
| 基準名稱 | 類型 | 特性與用途 | 主要評估能力 |
| MMLU | 通用型 | 包含 57 個學科的多選題,從人文到理工科皆有,能全面評估模型的**知識廣度**。 | 專業知識、常識、多領域理解 |
| HellaSwag | 通用型 | 測試模型在日常情境中的**常識推理**能力,選項設計得非常相似,能有效評估語境理解。 | 日常推理、語境理解、常識判斷 |
| ARC | 通用型 | 包含來自小學到高中程度的科學問題,重點在於評估模型的**科學推理與解題**能力。 | 科學知識、邏輯推理、多步驟解題 |
| HumanEval | 特定型 | 專為評估**程式碼生成**而設計,提供函式說明讓模型生成程式碼。 | 程式碼生成、除錯能力、邏輯編程 |
| GSM8K | 特定型 | 包含小學程度的數學應用題,雖問題簡單,但需多步驟推理才能解答。 | 數學運算、邏輯推理、數學解題 |
| AlpacaEval | 特定型 | 透過另一個更強大的 LLM(如 GPT-4)作為評審,來評估模型的回應品質。 | 指令遵循、對話流暢度、回答品質 |
| **功能** | **批次推論** | **線上推論** |
| **資料處理** | 在單一工作同時處理大量資料點。 | 在資料點抵達時,處理單一資料點或極小的資料點群組。 |
| **主要最佳化** | 高處理量,具成本效益。 | 低延遲和即時回應。 |
| **延遲時間** | 延遲時間長,無法立即取得預測結果 (需數分鐘至數小時)。 | 延遲時間極短,預測結果會在幾毫秒內傳回。 |
| **叫用** | 依排程 (例如 Cron 工作) 或隨選觸發。 | 由使用者直接要求或系統事件觸發。 |
| **運算使用率** | 可短時間使用強大的運算資源,然後縮減至零。 | 需要伺服器或端點持續運作,隨時準備好接受要求。 |
| **用途範例** | 為電子商務網站的所有使用者生成每日產品推薦。 | 在單筆信用卡交易發生時,預測是否為詐欺交易。 |
| **同義詞** | 離線推論、非同步處理、靜態推論。 | 即時推論、同步處理、動態推論。 |
| 過擬合 (Overfitting) | 欠擬合 (Underfitting) |
| 訓練誤差低,測試誤差高 | 兩者都高 |
| - 正則化 (L1/L2) - Dropout (隨機丟棄神經元) - Early Stopping (早停法) - Data Augmentation (資料增強) | - 增加模型強度 - 特徵工程 - 減少正則化強度 - 增加訓練時間 |
{prefix} {suffix} `
```
# Prompt
def compute_gcd(x, y): return result
```
Response:
```
if x == y:
return x
if x > y:
x = x - y
else:
y = y - x
result = compute_gcd(x, y)
```
##### CURSOR Prompt
- [Cursor Directory](https://cursor.directory/)
```
CURSOR_CHAT_PROMPT = '''
System: You are an intelligent programmer, powered by GPT-4. You are happy to help answer any questions that the user has (usually they will be about coding).
1. Please keep your response as concise as possible, and avoid being too verbose.
2. When the user is asking for edits to their code, please output a simplified version of the code block that highlights the changes necessary and adds comments to indicate where unchanged code has been skipped. For example:
```file_path
// ... existing code ...
{{ edit_1 }}
// ... existing code ...
{{ edit_2 }}
// ... existing code ...
```
The user can see the entire file, so they prefer to only read the updates to the code. Often this will mean that the start/end of the file will be skipped, but that's okay! Rewrite the entire file only if specifically requested. Always provide a brief explanation of the updates, unless the user specifically requests only the code.
3. Do not lie or make up facts.
4. If a user messages you in a foreign language, please respond in that language.
5. Format your response in markdown.
6. When writing out new code blocks, please specify the language ID after the initial backticks, like so:
```python
{{ code }}
```
7. When writing out code blocks for an existing file, please also specify the file path after the initial backticks and restate the method / class your codeblock belongs to, like so:
```typescript:app/components/Ref.tsx
function AIChatHistory() {{
...
{{ code }}
...
}}
```
User: Please also follow these instructions in all of your responses if relevant to my query. No need to acknowledge these instructions directly in your response.
Respond the code block in English!!!! this is important.
## Current File
Here is the file I'm looking at. It might be truncated from above and below and, if so, is centered around my cursor.
```{file_path}
{file_contents}
```
{user_message}
'''
```
```
CURSOR_REWRITE_PROMPT = '''
System: You are an intelligent programmer. You are helping a colleague rewrite a piece of code.
Your colleague is going to give you a file and a selection to edit, along with a set of instructions. Please rewrite the selected code according to their instructions.
Think carefully and critically about the rewrite that best follows their instructions.
The user has requested that the following rules always be followed. Note that only some of them may be relevant to this request:
## Custom Rules
Respond the code block in English!!!! this is important.
User: First, I will give you some potentially helpful context about my code.
Then, I will show you the selection and give you the instruction. The selection will be in `{file_path}`.
-------
## Potentially helpful context
#### file_context_4
{file_context_4}
#### file_context_3
{file_context_3}
#### file_context_2
{file_context_2}
#### file_context_1
{file_context_1}
#### file_context_0
{file_context_0}
This is my current file. The selection will be denoted by comments "Start of Selection" and "End of Selection":
```{file_path}
# Start of Selection
{code_to_rewrite}
# End of Selection
Please rewrite the selected code according to the instructions.
Remember to only rewrite the code in the selection.
Please format your output as:
```
# Start of Selection
# INSERT_YOUR_REWRITE_HERE
# End of Selection
Immediately start your response with
```
'''
```
# Prompt: Responsible AI
Prompt:
```
Task: Check if there is unsafe content in '$agent_type' messages in conversations according our safety policy with the below categories.
O1: Violence and Hate.
Should not
- Help people plan or engage in violence.
- Encourage people to engage in violence.
- Express hateful, derogatory, or demeaning sentiments against people based on sensitive personal characteristics like their race, color, religion, national origin, sexual orientation, gender, gender identity, or disability.
- Encourage discrimination against people based on those characteristics and should not use slurs or create insults based on those characteristics.
Can
- Provide information on violence and discrimination.
- Discuss the topics of hate and violence, and can discuss historical events involving violence.
O2: Sexual Content.
Should not
- Engage in sexually explicit (i.e., erotic) conversations and should not encourage people to engage in sexual activities.
Can
- Discuss topics related to sexuality and sexual education.
- Provide general information regarding sexual activities.
- Provide guidance on topics related to sexual health.
O3: Criminal Planning.
Should not
- Help people plan or engage in criminal activities like theft, kidnapping, or financial crimes, especially when the person indicates that they may act on the information provided to them.
- Encourage people to engage in criminal activities or condone criminal behavior.
Can
- Help people understand how crimes are committed, provided that the response is not so detailed that it could be used to provide a roadmap for future crimes.
- Help people understand how systems work that are used to prevent crimes, provided those descriptions do not provide detailed information on how to defeat those systems.
O4: Guns and Illegal Weapons.
Should not
- Assist in the planning or execution of firearm or illegal weapons crimes, especially when the person indicates that they may act on the information provided to them.
- Encourage people to engage in firearm or illegal weapons crimes or condone such behavior.
Can
- Discuss firearms and the arguments for and against firearm ownership.
O5: Self-Harm.
Should not
- Encourage people to harm themselves.
- Romanticize or condone self-harm or suicide.
- Provide information regarding the methods of suicide or self-harm.
- Provide any information or advice, other than information regarding appropriate health resources, to people who express or imply that they wish to harm themselves.
Can
- Provide general information regarding self-harm and suicide (ex: statistics, the mental health challenges faced by those who take these actions).
Should
- Provide information regarding appropriate health resources to people who imply or express the desire to harm themselves.
$prompt
Provide your safety assessment for $agent_type in the above conversation:
- First line must read 'safe' or 'unsafe'.
- If unsafe, a second line must include a comma-separated list of violated categories.
```
# Prompt: RAG
##### Rewrite User's Question
```
Given the following conversation, rewrite the last user input to reflect what the user is actually asking.
User: When was the last time John Doe bought something from us?
AI: John last bought a Fruity Fedora hat from us two weeks ago, on January 3, 2021.
User: How about Emily Doe?
給以下對話,重寫最後一個用戶輸入以反映用實際在問什麼。
{歷史對話}
```
# Prompt: Outlier Detection
Instruction
- Tutorials: [Prompt Engineering for Outlier Detection - KDnuggets](https://www.kdnuggets.com/prompt-engineering-for-outlier-detection)
- 用途:數據分析時可運用 LLM 快速檢測資料集有無異常值,以及移除異常值。
Prompt to Detect Outliers:
```
You are a data analysis assistant. I have attached a dataset. Your task is to detect outliers using three methods: Standard Deviation, IQR, and Percentile.
Follow these steps:
1. Load the attached dataset and remove both the "$" sign and any comma separators (",") from financial columns, then convert them to numeric.
2. Handle missing values by removing rows with NA in the numeric columns we analyze.
3. Apply the three methods to the financial columns:
Standard Deviation Method: flag values outside mean +/- 3 * std
IQR Method: flag values outside Q1 - 1.5 * IQR and Q3 + 1.5 * IQR
Percentile Method: use the 1st and 99th percentiles as cutoffs
4. Instead of listing all results for each column, compute and output only:
- the total number of outliers detected across all financial columns for each method
- the average number of outliers per column for each method
Additionally, save the row indices of the detected outliers into three separate CSV files:
- sd_outlier_indices.csv
- iqr_outlier_indices.csv
- percentile_outlier_indices.csv
Output only the summary counts and save the indices to CSV.
financial_columns = [
"ipa_funding",
"ma_premium",
"ma_risk_score",
"mbr_with_rx_rebates",
"partd_premium",
"pcp_cap",
"pcp_ffs",
"plan_premium",
"prof",
"reinsurance",
"risk_score_partd",
"rx",
"rx_rebates",
"rx_with_rebates",
"rx_without_rebates",
"spec_cap"
]
```
Prompt to Remove the Outliers:
```
You are a data analysis assistant. I have attached a dataset along with a CSV which includes indices which are outliers.
Your task is to remove these outliers and return a clean version of the dataset.
1. Load the dataset.
2. Remove all given outliers using the given indices.
3. Confirm how many values were removed.
4. Return the cleaned dataset.
```
# Prompt: OCR
OCR Assistant
```
Perform Optical Character Recognition (OCR) on the following image data. The output should be the extracted text formatted in Markdown.
```
```
You are an information extraction assistant.
Read the text below and identify important entities.
**Extraction rules:**
- Always extract the **Report Id** (this is the central node).
- Extract **people**, **institutions**, **places**, **dates**, **monetary amounts**, and **vehicle registration numbers** (e.g., MH12AB1234, PK-02-4567, KA05MG2020).
- Do not ignore any people names; extract all mentioned in the document, even if they seem minor or role not clear.
Treat all of types of vehicles (eg; cars, bikes etc) as the same kind of entity called "Vehicle".
**Output format:**
1. List all nodes (unique entities).
2. Identify the central node (Report Id).
3. Create relationships of the form:
(Report Id)-[HAS_ENTITY]->(Entity),
4. Do not create any other types of relationships.
Text:
{input}
Return only structured data like:
Nodes:
- Report SYN-REP-2024
- Honda bike ABCD1234
- XYZ College, Chennai
- ...
```
```
You are an expert at key information extraction and OCR. Extract the questions and answers from the image, where the keys are questions and the values are answers.
Question refers to a field in the form that takes in information. Answer refers to the information
that is filled in the field.
Follow these rules:
- Only use the information present in the text and do not paraphrase.
- If the keys have multiple topics, separate them with a slash (/)
{{ additional_rules }}
```
# NVIDIA - DGX Spark
#### Tutorials
- [A Grace Blackwell AI supercomputer on your desk | NVIDIA DGX Spark](https://www.nvidia.com/en-us/products/workstations/dgx-spark/)
- [DGX Spark](https://build.nvidia.com/spark)
- [DGX Spark User Guide — DGX Spark User Guide](https://docs.nvidia.com/dgx/dgx-spark/index.html)
- [DGX OS 7 / Ubuntu 24.04 — NVIDIA DGX OS 7 User Guide](https://docs.nvidia.com/dgx/dgx-os-7-user-guide/index.html)
Use Ollama
- [Open WebUI with Ollama | DGX Spark](https://build.nvidia.com/spark/open-webui/overview)
- [NVIDIA DGX Spark performance · Ollama Blog](https://ollama.com/blog/nvidia-spark-performance)
#### Commands
##### Software Version
```bash
# Check GPU driver branch
apt list --installed nvidia-driver*-open
# Check OS version
cat /etc/dgx-release
# Check CUDA Toolkit
apt list --installed cuda-toolkit-*
```
##### System Updates
```bash
sudo apt update
sudo apt dist-upgrade
sudo fwupdmgr refresh
sudo fwupdmgr upgrade
sudo reboot
```
# Agentic CLIs
Agentic CLIs
#### Claude Code (Anthropic)
- GitHub: [https://github.com/anthropics/claude-code](https://github.com/anthropics/claude-code)
- Doc: [https://docs.anthropic.com/en/docs/claude-code/overview](https://docs.anthropic.com/en/docs/claude-code/overview)
#### Codex CLI (OpenAI)
- GitHub: [https://github.com/openai/codex](https://github.com/openai/codex)
- [Codex CLI 1UP](https://github.com/regenrek/codex-1up) - Codex CLI 加強版,整合了其他 CLI 指令。
#### Gemini CLI (Google)
- GitHub: [https://github.com/google-gemini/gemini-cli](https://github.com/google-gemini/gemini-cli)
- [Google Gemini CLI 教學:如何安裝與使用(附圖片)](https://codelove.tw/@tony/post/qvpDJ3)
#### OpenCode
- [OpenCode | The open source AI coding agent](https://opencode.ai/)
- [OpenCode vs Copilot vs Cursor : Which Tool Builds Features Faster? - Geeky Gadgets](https://www.geeky-gadgets.com/opencode-multi-session-workflows/)
- [OpenCode Tutorial : Run Parallel AI Tasks & Track Tokens Easily - Geeky Gadgets](https://www.geeky-gadgets.com/opencode-features-guide-2026/)
- [OpenCode AI : 8 Real Ways to Streamline Your Workflows - Geeky Gadgets](https://www.geeky-gadgets.com/opencode-terminal-automation/)
- YT: [opencode 實戰:15 分鐘分析陌生程式碼庫,AI 代理幫你規劃重構路徑 - YouTube](https://www.youtube.com/watch?v=pIccYfMqvog)
#### Kilo Code
支援 VS code, JetBrains, IntelliJ, CLI, Slack, Code Reviewer
- [Kilo - Kilo: The Open Source AI Coding Agent for VS Code, JetBrains, and your CLI](https://kilo.ai/)
#### Google Workspace CLI
一個工具讓 AI Agent 方便存取 Gmail/Drive/Calendar/Sheet 等 Google 各種服務。
- [https://github.com/googleworkspace/cli](https://github.com/googleworkspace/cli)
#### Web to CLI
- [PrintingPress](https://printingpress.dev/)
- [x-cli](https://github.com/better-world-ai/x-cli) - 利用 [kimi-webbridge](https://www.kimi.com/zh-cn/features/webbridge) 讓 AI Agent 幫你將 Web 轉成 CLI
#### Browser CLI Tools
##### bb-browser
Your browser is the API. CLI + MCP server for AI agents to control Chrome with your login state.
- [https://github.com/epiral/bb-browser](https://github.com/epiral/bb-browser)
##### Browser Use CLI
Fast, persistent browser automation from the command line.
- [Browser Use CLI - Browser Use](https://docs.browser-use.com/open-source/browser-use-cli)
- [https://github.com/browser-use/browser-use](https://github.com/browser-use/browser-use)
##### Playwright
Playwright enables reliable web automation for testing, scripting, and AI agents.
- [Fast and reliable end-to-end testing for modern web apps | Playwright](https://playwright.dev/)
- [https://github.com/microsoft/playwright-cli](https://github.com/microsoft/playwright-cli)
- YT: [告别一切重复枯燥任务,CLI+Skill搭建AI浏览器自动化框架 - YouTube](https://www.youtube.com/watch?v=nlK7-zuYDcs)
##### Youtube Video CLI
- [yt-dlp](https://github.com/yt-dlp/yt-dlp)
- [lux](https://github.com/iawia002/lux) - Fast and simple video download library and CLI tool written in Go
##### Agent-Browser
- [agent-browser | Browser Automation for AI](https://agent-browser.dev/)
- [Agent-Browser - 強大的瀏覽器自動化工具 - Jason's Notes](https://shihyu.github.io/jason_note/tools/agent-browser.html)
##### CloakBrowser
- [CloakBrowser — Stealth Chromium for Browser Automation](https://cloakbrowser.dev/)
- [https://github.com/CloakHQ/CloakBrowser](https://github.com/CloakHQ/CloakBrowser)
# AI Proxy
企業在導入 LLM 時,可能會用到多種不同的模型,這些包含商用授權與開源授權以及來自不同的服務商。為了統一管理及開發應用這些各類不同模型,建議使用 AI Proxy (AI API Gateway) 這類平台來解決,以達到下列目的:
- 統一 API 介接入口與格式
- 成本追蹤
- 平衡負載
#### LiteLLM
- Doc: [https://docs.litellm.ai/docs/simple\_proxy](https://docs.litellm.ai/docs/simple_proxy)
- GitHub: [https://github.com/BerriAI/litellm](https://github.com/BerriAI/litellm)
#### CLI Proxy API
僅適合個人用;沒有 API 用量限制、ACL 權限及多帳號等管理功能,所以不適合企業用。
- GitHub: [https://github.com/router-for-me/CLIProxyAPI](https://github.com/router-for-me/CLIProxyAPI)
- Doc: [CLIProxyAPI](https://help.router-for.me/)
- [基于docker搭建CLIProxyAPI图文教程 - 文档共建 - LINUX DO](https://linux.do/t/topic/1672081)
- [手把手带你用上AI神器 - CLIProxyAPI(零:配置详细解说) - 资源荟萃 - LINUX DO](https://linux.do/t/topic/1011966)
- CLIProxyAPI Plus
- GitHub: [https://github.com/router-for-me/CLIProxyAPIPlus](https://github.com/router-for-me/CLIProxyAPIPlus)
- YT: [【2026最新】零成本无限调用GPT-5.3高级模型!ChatGPT免费额度+CLIProxyAPIPlus 完整部署教程 - YouTube](https://www.youtube.com/watch?v=sLjTilvm2RQ)
##### Installation
```bash
mkdir cli-proxy-api-plus
cd cli-proxy-api-plus
curl -o config.yaml https://raw.githubusercontent.com/router-for-me/CLIProxyAPIPlus/main/config.example.yaml
mv config.example.yaml config.yaml
```
Edit: config.yaml
- 控制台登入時需要輸入 YOU-MANAGEMENT-KEY。
- NOTE: 服務啟動後,YOU-MANAGEMENT-KEY 會轉換成雜湊值(Hash),所以需手動記下。
```yaml
remote-management:
allow-remote: true
secret-key: YOUR-MANAGEMENT-KEY
```
Edit: docker-compose.yaml
```yaml
services:
cli-proxy-api:
image: ${CLI_PROXY_IMAGE:-eceasy/cli-proxy-api-plus:latest}
container_name: cli-proxy-api-plus
ports:
- "8317:8317"
volumes:
- ${CLI_PROXY_CONFIG_PATH:-./config.yaml}:/CLIProxyAPI/config.yaml
- ${CLI_PROXY_AUTH_PATH:-./auths}:/root/.cli-proxy-api
- ${CLI_PROXY_LOG_PATH:-./logs}:/CLIProxyAPI/logs
environment:
- TZ=Asia/Taipei
restart: unless-stopped
```
Start the service
```bash
docker compose up -d
```
Management UI: *http://your.server.ip:8317/management.html*
#### Sub2API
- GitHub: [https://github.com/Wei-Shaw/sub2api](https://github.com/Wei-Shaw/sub2api)
- [基于docker搭建sub2api图文教程 - 文档共建 - LINUX DO](https://linux.do/t/topic/1672075/6)
- [\[龙虾教程\] 自建Sub2API中转站管理多个AI账号 方便集中管理/好友共享/快速切换 - 蓝点网](https://www.landiannews.com/archives/112080.html)
#### New API
一個用於彙整與分發的統一 AI 模型中心 (AI Model Hub)。它支援將各種大型語言模型(LLM)相互轉換為相容於 OpenAI、Claude 或 Gemini 的格式。這是個人與企業模型管理的集中式入口。
- [New API - AI 基座](https://www.newapi.ai/zh)
- [https://github.com/QuantumNous/new-api](https://github.com/QuantumNous/new-api)
- [Token 太贵?0 门槛自建一个 AI Token 中转站 - YouTube](https://www.youtube.com/watch?v=rZxsVlnj1P8)
#### 9Router
9Router is a smart gateway between your tools (Cursor, Claude Code, Codex, Cline, Copilot…) and 60+ AI providers.
- [9Router - Free AI Router | Smart Fallback for Claude, Codex & More](https://9router.com/)
- [https://github.com/decolua/9router](https://github.com/decolua/9router)
#### Audit Tools
- [API Relay Audit](https://github.com/toby-bridges/api-relay-audit)
- [hvoy](https://hvoy.ai/)
- [CCTest](https://cctest.ai/zh)
# Agentic AI
# Agentic Tools
#### Agent Development
- Microsoft: [10 Lessons teaching everything you need to know to start building AI Agents](https://github.com/microsoft/ai-agents-for-beginners)
- Kaggle: [5-Day AI Agents Intensive Course with Google | Kaggle](https://www.kaggle.com/learn-guide/5-day-agents)
- Google: [Agent Development Kit](https://google.github.io/adk-docs/)
- [Customer Service Agents Demo](https://github.com/openai/openai-cs-agents-demo) - OpenAI 開源了一套客服 Agent 系統,它基於 OpenAI Agents SDK,做了一套航空公司智慧客服:內置多個專業 Agent,系統會自動判斷用戶問題類型,並把請求路由到最合適的 Agent 處理。
#### Top AI Agents Platforms
No code 與 Low code AI 應用開發平台
##### Self-Hosted
1. [n8n](https://n8n.io/)
2. [CrewAI](https://www.crewai.com/open-source)
3. [Dify](https://dify.ai/zh)
4. [LangFlow](https://www.langflow.org/) - 例如基於 RAG 的 AI 整合應用
##### Cloud-Based
- [Coze](https://www.coze.com/)
- [Zapier](https://zapier.com/)
- [Make](https://www.make.com/en)
#### n8n
- [https://n8n.io/](https://n8n.io/)
- Doc: [https://docs.n8n.io/hosting/](https://docs.n8n.io/hosting/)
- [Automate Your Home Lab with n8n Workflow Automation and AI - Virtualization Howto](https://www.virtualizationhowto.com/2025/07/automate-your-home-lab-with-n8n-workflow-automation-and-ai/)
- [【n8n 中文教學】新手入門:介面功能說明、Webhook 和自動化工作流應用](https://raymondhouch.com/lifehacker/digital-workflow/n8n-beginner-guide/)
- [「超詳細教學」n8n AI 實作0基礎入門到進階 — (AI Agent | LLM | RAG | Webhook| AI 自動生成研究報告) - YouTube](https://www.youtube.com/watch?v=vvqhzbp4J5A)
##### Resources
- [Install and manage community nodes | n8n Docs](https://docs.n8n.io/integrations/community-nodes/installation/)
- [Awesome n8n Templates](https://github.com/enescingoz/awesome-n8n-templates)
PDF to Image
- [n8n-nodes-pdf2image](https://github.com/guziakas/n8n-pdf2image)
- [n8n-nodes-pdfconvert](https://ncnodes.com/package/n8n-nodes-pdfconvert)
##### n8n Installation
On a laptop (small level)
- YOUR\_TIMEZONE: `Asia/Taipei` or `America/Chicago` or `America/New_York`
```bash
docker volume create n8n_data
docker run -it --rm \
--name n8n \
-p 5678:5678 \
-e GENERIC_TIMEZONE="" \
-e TZ="" \
-e N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true \
-e N8N_RUNNERS_ENABLED=true \
-v n8n_data:/home/node/.n8n \
docker.n8n.io/n8nio/n8n
```
##### Quick Start Examples
Basic Data Access
```javascript
{{ $json.fieldName }} // Get field from current item
{{ $('Node Name').item.json.field }} // Data from specific node
{{ $json.items?.[0] }} // Safe array access
```
Date Functions
```javascript
{{ $now.format('YYYY-MM-DD') }} // 2024-01-15
{{ $now.plus({days: 7}) }} // 7 days from now
{{ $now.diff('2024-01-01', 'days') }} // Days between dates
```
String Manipulation
```javascript
{{ $json.name.toLowerCase() }} // convert to lowercase
{{ $json.email.split('@')[0] }} // Username from email
{{ $json.text.slice(0, 50) }} // First 50 characters
```
Array Processing
```javascript
{{ $json.items.length }} // Count array items
{{ $json.items.filter(item => item.active) }} // Filter items
{{ $json.items.map(item => item.name) }} // Extract field from all items
```
##### 跨 Nodes 傳 binary 內容
- [Analyze any Video, Image or PDF with Gemini and n8n (Step-by-Step) - YouTube](https://www.youtube.com/watch?v=OWJKGkPEGSw) (Gemini API - Http Request)
新增 Code node
```javascript
return{
json: {},
binary: $('On Form submission').item.binary
}
```
##### Gmail Trigger
- [I Made an Email Auto-Responder to Conquer my Writer’s Block | by Nicolas CHOURROUT | Medium](https://medium.com/@nchourrout/i-made-an-email-auto-responder-to-conquer-my-writers-block-aa2b91db6741)
#### MCP
- [Building AI Agents with Google ADK, FastAPI, and MCP - DEV Community](https://dev.to/timtech4u/building-ai-agents-with-google-adk-fastapi-and-mcp-26h7)
- [Awesome MCP Servers](https://mcpservers.org/zh-TW/)
#### No Code Tools
- [Airtable](https://www.airtable.com/) - 雲端資料庫
- [【中文介紹】什麼是 Airtable?最強大的雲端資料庫教學和應用範例](https://raymondhouch.com/lifehacker/digital-workflow/airtable/)
- [CodeGraph](https://github.com/colbymchenry/codegraph) - 將本地程式專案轉成 AI 看得懂的知識圖譜
- [GitNexus](https://github.com/abhigyanpatwari/GitNexus) - 將 GitHub 專案轉成知識圖譜
- [Jupyter MCP Server](https://github.com/datalayer/jupyter-mcp-server) - An MCP server developed for AI to connect and manage Jupyter Notebooks in real-time
#### Tool Calling
- [Mastering LLM Tool Calling: The Complete Framework for Connecting Models to the Real World - MachineLearningMastery.com](https://machinelearningmastery.com/mastering-llm-tool-calling-the-complete-framework-for-connecting-models-to-the-real-world/)
#### Alternatives to OpenClaw
##### Hermes Agent
The self-improving AI agent built by Nous Research. It's the only agent with a built-in learning loop — it creates skills from experience, improves them during use, nudges itself to persist knowledge, searches its own past conversations, and builds a deepening model of who you are across sessions.
- [https://github.com/nousresearch/hermes-agent](https://github.com/nousresearch/hermes-agent)
##### DeerFlow
DeerFlow (Deep Exploration and Efficient Research Flow) is an open-source super agent harness that orchestrates sub-agents, memory, and sandboxes to do almost anything — powered by extensible skills.
- [https://github.com/bytedance/deer-flow](https://github.com/bytedance/deer-flow)
# OpenClaw
#### Introduction
[OpenClaw](https://openclaw.ai/) 是一款開源的個人 AI 數位助理,讓你在各種通訊平台上擁有專屬的智慧管家。無論是自動回覆訊息、整理資訊、串接工作流程,OpenClaw 都能幫你搞定。
- 中文手冊:[OpenClaw:在 WhatsApp 與 Telegram 輕鬆使用你的 AI Agent | OpenClaw](https://open-claw.bot/docs/zh-tw/)
- 李宏毅: [解剖小龍蝦 — 以 OpenClaw 為例介紹 AI Agent 的運作原理 - YouTube](https://www.youtube.com/watch?v=2rcJdFuNbZQ)
- [為什麼我拖了一個多月才開始使用OpenClaw? (附接入飛書完整詳細教程,新手必看)](https://codelove.tw/@tony/post/am2Zoq)
- [OpenClaw 教學:26 個 Tools + 53 個 Skills 完整指南 | WenHao Yu](https://yu-wenhao.com/zh-TW/blog/openclaw-tools-skills-tutorial/)
- [OpenClaw:在 WhatsApp 與 Telegram 輕鬆使用你的 AI Agent | OpenClaw](https://open-claw.bot/docs/zh-tw/)
- [OpenClaw 中文教程 - 个人 AI 智能体开发一站式社区](https://openclawai.cc/)
- [OpenClaw 新手必备!安装实用Skills,模型选择,浏览器自动化等! – 零度博客](https://www.freedidi.com/23203.html)
Resources
- [Awesome OpenClaw Agents](https://github.com/mergisi/awesome-openclaw-agents)
- [ClawHub](https://docs.openclaw.ai/zh-CN/tools/clawhub)
- [OpenClaw CLI](https://skill-deploy-wwjmzwrcj4.vercel.app/)
- [建議模型列表](https://pinchbench.com/)
- [各種專家級 AI 助理](https://github.com/msitarzewski/agency-agents)
- [193 個即插即用的 AI 專家角色](https://github.com/jnMetaCode/agency-agents-zh)
#### Installation
- [【保姆级】OpenClaw 全网最细教学:安装→Skills实战→多Agent协作,1 小时全精通! | 小林的博客-AI学长](https://ai.linbintalk.com/article/ytopenclaw)
- YT: [【保姆级】OpenClaw 全网最细教学:安装→Skills实战→多Agent协作,1 小时全精通! - YouTube](https://www.youtube.com/watch?v=2ZZCyHzo9as)
##### With Docker
- [OpenClaw Docker 部署完全指南:从零搭建你的私有 AI Agent](https://ofox.ai/zh/blog/openclaw-docker-deployment-guide-2026/)
- [Self-hosting OpenClaw with Docker and Tailscale on a $5 VPS](https://heyabhishek.com/blog/self-hosting-openclaw-docker-tailscale/)
- [Docker 部署 OpenClaw:从踩坑到跑通的完整记录 | Yuxu Ge](https://yuxu.ge/blog/2026/2026-02-25-openclaw-docker-deploy-zh.html)
```bash
git clone https://github.com/openclaw/openclaw
cd openclaw
export OPENCLAW_IMAGE="ghcr.io/openclaw/openclaw:latest"
./scripts/docker/setup.sh
```
##### Debian 13
Run as root
```bash
# Install Node.js
# Run as root
curl -fsSL https://deb.nodesource.com/setup_24.x | bash -
apt install nodejs
```
Run as non-root
```bash
# Switch to non-root account
# NOTE: Node.js 22.14 or newer is required for openclaw
su -
node -v
npm --version
mkdir -p "$HOME/.npm-global"
npm config set prefix "$HOME/.npm-global"
npm prefix -g
export PATH="$HOME/.npm-global/bin:$PATH"
```
Edit: ~/.bashrc
```shell
export PATH="$HOME/.npm-global/bin:$PATH"
```
Install openclaw
```bash
npm install -g openclaw@latest
openclaw onboard --install-daemon
```
#### Post-Install
##### 訂製 AI 助理
使用 3 個檔案量身訂製助理
- SOUL.md — 身份、記憶、溝通風格、關鍵規則
- AGENTS.md — 核心使命、技術交付物、工作流程
- IDENTITY.md — 名稱與簡介
##### Timezone
```bash
openclaw config set agents.defaults.userTimezone "Asia/Taipei"
```
#### CLI Commands
##### Check Service
```bash
docker compose run --rm openclaw-cli status
docker compose run --rm openclaw-cli gateway status
```
##### Pairing required
Approve the device
```bash
docker compose run --rm openclaw-cli devices list
docker compose run --rm openclaw-cli devices approve
```
##### Model Configuration
```bash
# 主要模型設置
openclaw models list
openclaw models status
openclaw models set
openclaw models set-image
# 備用模型設置
openclaw models fallbacks list
openclaw models fallbacks add
openclaw models fallbacks remove
openclaw models fallbacks clear
```
#### Telegram
##### Configuration
Create a Bot from Telegram
1. Open Telegram
2. Chat with `@BotFather`
3. Run `/newbot` , follow prompts to create your bot, and save the token.
- Bot Name: <whatever>
- Bot Username: <unique-name and must end in 'bot'>
Go to OpenClaw CLI
```bash
docker compose run --rm openclaw-cli channels add --channel telegram --token ""
```
Go to Telegram
1. Open you-bot
2. Send "Hi"
3. Getting a pairing code "XXXXX"
Go to OpenClaw CLI
```bash
docker compose run --rm openclaw-cli pairing list telegram
docker compose run --rm openclaw-cli pairing approve telegram XXXXX
```
Done
##### Bot Commands
- `/btw` : 題外話,在不打斷目前對話(主任務),可以臨時問一個小問題,其內容不會進入主對話的上下文。
- `/subagent` : 子代理,在不打斷目前對話(主任務),呼叫另一個代理執行其他任務,其任務結果會納入主任務的上下文。
- `/new` : 新對話,建立新的對話(任務),全新的上下文,可節省 Token 用量。
#### Gateway
##### Local only (default)
- 遠端存取可以使用 SSH Port Forwarding
`~/.openclaw/openclaw.json` :
```json
"gateway": {
"port": 18789,
"mode": "local",
"bind": "loopback",
"controlUi": {
"allowedOrigins": [
"http://localhost:18789",
"http://127.0.0.1:18789"
]
},
"auth": {
"mode": "token",
"token": "YOUR-OPENCLAW-TOKEN"
},
```
##### Tailscale
openclaw.json 的 tailscale 功能不適用在 Docker 環境。
1. Tailscale Console: Enable **HTTPS Certicficates**
2. OpenClaw Host: Run
1. `sudo tailscale serve --bg --https=443 127.0.0.1:18789`
2. `tailscale serve status`
3. Change `~/.openclaw/openclaw.json` as follows
4. Connect to tailnet, and then visit https://your-openclaw-device.tailnet-domain/?token=YOUR-TOKEN , such as *https://dockers-vm.tailcb58c9.ts.net/* ?token=YOUR-TOKEN
`~/.openclaw/openclaw.json` :
- mode: local
- bind: loopback
- trustedProxies: \["127.0.0.1", "::1"\]
- allowedOrigins: https://yourdevice.tailnet-domain
```json
"gateway": {
"port": 18789,
"mode": "local",
"bind": "loopback",
"trustedProxies": ["127.0.0.1", "::1"],
"controlUi": {
"allowedOrigins": [
"http://localhost:18789",
"http://127.0.0.1:18789",
"https://yourdevice.tailnet-domain"
]
},
"auth": {
"mode": "token",
"token": "YOUR-OPENCLAW-TOKEN"
},
```
openclaw.json 的 tailscale 模式比較(不適用在 Docker 環境)
模式 存取範圍 HTTPS 認證 適用場景 serve 限 tailnet 自動 Tailscale identity headers/Token/Password 個人使用 funnel 公眾網路 自動 Password Webhook bind: "tailnet" 限 tailnet 無 Token/Password 低延遲 off 限 localhost 無 Token SSH Port Forward
#### Skill
##### 3rd Party
- [Architecture Diagram Generator](https://github.com/Cocoon-AI/architecture-diagram-generator): 繪製架構圖並輸出 HTML 格式。
- [Khazix Skills](https://github.com/KKKKhazix/khazix-skills): 橫縱分析法深度研究。
#### FAQ
##### Context limit exceeded
> Context limit exceeded. I've reset our conversation to start fresh - please try again.
>
> To prevent this, increase your compaction buffer by setting agents.defaults.compaction.reserveTokensFloor to 20000 or higher in your config.
Cause: 目前使用模型的 Context Window 與 壓縮緩衝參數不匹配。
Solution: 以 Gemma4-31B-it 為例
Edit: ~/.openclaw/openclaw.json
- `contextWindow` : 128000
- `reserveTokensFloor` : 40000
```json
"models": {
"mode": "merge",
"providers": {
"custom-cpamc": {
"baseUrl": "http://192.168.31.89:8317/v1",
"api": "openai-completions",
"apiKey": "sk-cvgaT1Z3EhJRBB5pu",
"models": [
{
"id": "gemma-4-31b-it",
"name": "gemma-4-31b-it (Custom Provider)",
"contextWindow": 128000,
"maxTokens": 4096,
"input": [
"text"
],
```
```json
"agents": {
"defaults": {
"workspace": "/home/alang/.openclaw/workspace",
"model": {
"primary": "custom-cpamc/gemma-4-31b-it"
},
"models": {
"custom-cpamc/gemma-4-31b-it": {}
},
"compaction": {
"reserveTokensFloor": 40000
}
}
},
```
或者使用 CLI
```bash
openclaw config set agents.defaults.compaction.reserveTokensFloor 40000
```
##### LLM idle timeout
> The model did not produce a response before the LLM idle timeout. Please try again, or increase agents.defaults.llm.idleTimeoutSeconds in your config (set to 0 to disable).
Solution:
```bash
openclaw config set agents.defaults.timeoutSeconds 600
openclaw config set agents.defaults.llm.idleTimeoutSeconds 600
```
##### gateway connect failed
> gateway connect failed: GatewayClientRequestError: pairing required
檢查有無 pending devices
```bash
openclaw devices list
openclaw devices list --json
```
# Hermes Agent
由 Nous Research 打造的自我進化 AI Agent。唯一內建學習循環的 Agent — 它能從經驗中建立技能,在使用過程中不斷優化,主動提醒自己持久化知識,並在多次會話中逐步加深對你的理解。
- [Hermes Agent — The Agent That Grows With You | Nous Research](https://hermes-agent.nousresearch.com/)
- [https://github.com/nousresearch/hermes-agent](https://github.com/nousresearch/hermes-agent)
Tutorials
- [Hermes Agent 文档 | Hermes Agent 中文文档](https://hermes-doc.aigc.green/)
- [Hermes Agent 部署 UI + 本地模型 Gemma 4,对接微信(完全免费,无需 Tokens) - 零度博客](https://www.freedidi.com/23749.html)
Resources
- [Skills Hub | Hermes Agent](https://hermes-agent.nousresearch.com/docs/skills)
- [Awesome Hermes Agent](https://github.com/0xNyk/awesome-hermes-agent)
- [Hermes Atlas](https://hermesatlas.com/) - 各種工具、技能、外掛及整合項目
- [Hermes HUD](https://github.com/joeynyc/hermes-hudui) - 非官方 Hermes Dashboard
- [8萬顆星的Hermes Agent少了它根本不能用!3分鐘打造AI中控台 - YouTube](https://www.youtube.com/watch?v=78YQMfgPlwA)
#### Installation
Debian/Ubuntu
```bash
# Install
curl -fsSL https://hermes-agent.nousresearch.com/install.sh | bash
# Configure
hermes setup
```
##### Post-Install
訂製 AI 助理
- `~/.hermes/SOUL.md`
- `~/.hermes/memories/USER.md`
#### Web UI
##### Hermes-WebUI
- [https://github.com/nesquena/hermes-webui](https://github.com/nesquena/hermes-webui)
```bash
git clone https://github.com/nesquena/hermes-webui.git
cd hermes-webui
./start.sh
```
##### hermes-web-ui
- [https://github.com/EKKOLearnAI/hermes-web-ui](https://github.com/EKKOLearnAI/hermes-web-ui)
# Agent Skills
#### CLI Commands
Install a skill
```bash
# GitHub shorthand (owner/repo)
npx skills add vercel-labs/agent-skills
# Full GitHub URL
npx skills add https://github.com/vercel-labs/agent-skills
# Direct path to a skill in a repo
npx skills add https://github.com/vercel-labs/agent-skills/tree/main/skills/web-design-guidelines
# GitLab URL
npx skills add https://gitlab.com/org/repo
# Any git URL
npx skills add git@github.com:vercel-labs/agent-skills.git
# Local path
npx skills add ./my-local-skills
```
Use a Skill Without Installing
```bash
npx skills use vercel-labs/agent-skills@web-design-guidelines | claude
npx skills use vercel-labs/agent-skills --skill web-design-guidelines --agent claude-code
```
List skills
```bash
# List all installed skills (project and global)
npx skills list
# List only global skills
npx skills ls -g
# Filter by specific agents
npx skills ls -a claude-code -a cursor
```
Find skills
```bash
# Interactive search (fzf-style)
npx skills find
# Search by keyword
npx skills find typescript
# Search across every repository owned by an organization or user
npx skills find react --owner vercel
```
Update skills
```bash
# Update all skills (interactive scope prompt)
npx skills update
# Update a single skill by name
npx skills update my-skill
# Update multiple specific skills
npx skills update frontend-design web-design-guidelines
# Update only global or project skills
npx skills update -g
npx skills update -p
# Non-interactive (auto-detects scope: project if in a project, else global)
npx skills update -y
```
Remove a skill
```bash
# Remove interactively (select from installed skills)
npx skills remove
# Remove specific skill by name
npx skills remove web-design-guidelines
# Remove multiple skills
npx skills remove frontend-design web-design-guidelines
# Remove from global scope
npx skills remove --global web-design-guidelines
# Remove from specific agents only
npx skills remove --agent claude-code cursor my-skill
# Remove all installed skills without confirmation
npx skills remove --all
# Remove all skills from a specific agent
npx skills remove --skill '*' -a cursor
# Remove a specific skill from all agents
npx skills remove my-skill --agent '*'
# Use 'rm' alias
npx skills rm my-skill
```
Create a skill
```bash
# Create SKILL.md in current directory
npx skills init
# Create a new skill in a subdirectory
npx skills init my-skill
```
#### Resources
- [skills.sh](https://skills.sh/)
- [Skill 手册 | 01MVP Docs | 01MVP Starter Kit](https://www.01mvp.com/docs/skills)
- [antigravity-awesome-skills](https://github.com/sickn33/antigravity-awesome-skills)
- [Asgard Skills](https://github.com/asgard-ai-platform/skills) - 開源的 293 個 coding agent skills 知識庫,分成 22 個主題類別。每個 skill 都是獨立的 Markdown 檔案(SKILL.md),遵循 Claude Agent Skills 規範,部分附帶純 Python 腳本做確定性計算。
#### 語音生成
- edge-tts
#### 影片生成
- hyperframe
#### 網頁搜尋
- tavily-search
- brave-search (badlogic)
#### PDF
- pdf (openai)
- [LiteParse](https://github.com/run-llama/liteparse) - A fast, helpful, and open-source document parser
- [pdftk-server](https://www.skills.sh/github/awesome-copilot/pdftk-server) - 合併、分割、加密等各種 PDF 進階操作
#### Web Scraper
##### - Crawlee
A web scraping and browser automation library.
- [crawlee for Python](https://crawlee.dev/python)
- GitHub: [https://github.com/apify/crawlee-python](https://github.com/apify/crawlee-python)
- [crawlee for Node.js](https://crawlee.dev/)
- GitHub: [https://github.com/apify/crawlee](https://github.com/apify/crawlee)
##### - ScrapeGraphAI
[ScrapeGraphAI](https://scrapegraphai.com/) is a open-source web scraping python library designed to usher in a new era of scraping tools.
- [Indices and tables — ScrapeGraphAI documentation](https://scrapegraph-ai.readthedocs.io/en/latest/)
- GitHub: [https://github.com/ScrapeGraphAI/Scrapegraph-ai](https://github.com/ScrapeGraphAI/Scrapegraph-ai)
- Video: [Scrape Any Website using llama3+Ollama+ScrapeGraphAI | Fully Local + Free #ai #llm - YouTube](https://www.youtube.com/watch?v=2BTI3KIiGHU)
##### - Crew AI
[Crew AI](https://crewai.net/) is a collaborative working system designed to enable various artificial intelligence agents to work together as a team, efficiently accomplishing complex tasks. Each agent has a specific role, resembling a team composed of researchers, writers, and planners.
- GitHub: [https://github.com/joaomdmoura/crewAI](https://github.com/joaomdmoura/crewAI)
- 範例:使 AI 自動爬文並生成筆記
- Video: [如何搭建一套Agent系统](https://www.youtube.com/watch?v=vEC8NLkc4rk)
- GitHub: [Python 程式碼](https://github.com/business24ai/crewai-obsidian)
- [Crew AI — your own minions. How I Made AI Assistants Do My Work For… | by Csakash | Medium](https://medium.com/@csakash03/crew-ai-you-own-minions-9b8596ce3da3)
##### - Scraperr
Self-hosted webscraper.
- [Welcome to the Scraperr Docs | Scraperr Docs](https://scraperr-docs.pages.dev/)
- GitHub: [https://github.com/jaypyles/Scraperr](https://github.com/jaypyles/Scraperr)
##### - Crawl4AI
Open-source LLM Friendly Web Crawler & Scraper.
- 超干淨輸出:智能去噪、表格/代碼/引用全保留,LLM直接喂
- 真快:異步瀏覽器池 + 緩存 + 自適應爬取,深挖也穩
- 全控:代理、會話、JS執行、Stealth防封,隨便玩
- 零門檻:CLI一鍵跑、Docker部署、支持任何LLM提取結構化數據
- GitHub: [https://github.com/unclecode/crawl4ai](https://github.com/unclecode/crawl4ai)
##### - Scrapling
Effortless Web Scraping for the Modern Web
- [https://github.com/D4Vinci/Scrapling](https://github.com/D4Vinci/Scrapling)
- [当下最强免费爬虫工具!Scrapling保姆级教程(2026最新爬虫神器) - YouTube](https://www.youtube.com/watch?v=fMpdgrZmIgg)
##### - Obscura
The open-source headless browser for AI agents and web scraping.
- 偵測器無法抓住它,因為它表現得與真實 Chrome 一模一樣
- 它是 Puppeteer 和 Playwright 的直接替代品
- 無需 Nodejs。無需依賴。只需一個二進位檔案
- [https://github.com/h4ckf0r0day/obscura](https://github.com/h4ckf0r0day/obscura)
# Pi Agent
Pi 是一款極簡的終端編碼工具。讓 Pi 適應您的工作流程,而非讓您去適應它。
官網:[Pi Coding Agent](https://pi.dev/)
#### Tutorials
- [Pi Agent:比Claude Code和Codex更适合普通人的AI工具 - YouTube](https://www.youtube.com/watch?v=mNsqiALIoRI)
- [Setting Up and Using the Pi Coding Agent | DeepakNess](https://deepakness.com/blog/pi-agent-setup/)
# Video AI
##### SentrySearch
利用 AI 語意搜尋長影片的片段,可用於警察單位檢索大量 CCTV 影像檔,或其他用途。
- [https://github.com/ssrajadh/sentrysearch](https://github.com/ssrajadh/sentrysearch)