Python
Python是一種廣泛使用的直譯式、進階程式、通用型程式語言,由吉多·范羅蘇姆創造,第一版釋出於1991年。Python是ABC語言的後繼者,也可以視之為一種使用傳統中綴表達式的LISP方言。Python的設計哲學強調代碼的可讀性和簡潔的語法。相比於C++或Java,Python讓開發者能夠用更少的代碼表達想法。
- Learning
- pip
- Example: IP Geolocation Tool
- Tips
- Functions
- THSRC API
- JSON
- Datetime
- One-Liners
- List 串列
- String 字串
- Installation
- Unit Test
- Regular Expression
- Tuple 元組
- Dictionary 字典
- Google Python Course
- Python Cheat Sheet
- Set 集合
- CSV
- Error Handling
- Binary Search
- Debug
- Python Virtual Environment
- Custom Setup.py
- FastAPI
- Example: Internet Speed Tacker
- Flask API
Learning
Online Interpreter
- https://www.onlinegdb.com/online_python_interpreter
- https://repl.it/languages/python3
- https://www.tutorialspoint.com/execute_python3_online.php
- https://rextester.com/l/python3_online_compiler
- https://trinket.io/python3
Online Handbooks
Online Tutorials
- The Python Tutorial
- The Hitchhiker’s Guide to Python
- How to make an awesome command line tool like MyCLI, PgCLI
- A Beginner's Guide to Programming
- Beyond the Basic Stuff with Python
- 100 Page Python Intro
- Understanding Python re(gex)
- Everything You Need to Learn Python Programming (應用總整理)
- Python Tutorial (進階應用分享)
- Learn Python Programming – Everything You Need to Know (基礎)
- Python Cookbook 3rd Edition Documentation (簡中)
- PEP 8 – Style Guide for Python Code | peps.python.org
- Python 工匠: 案例、技巧 (部分免費閱讀)
- Python 基礎50課
Python examples
Web scraping (網頁爬取)
- A guide to web scraping in Python using Beautiful Soup
- python爬虫教程从0到1
- AutoScraper: A Smart, Automatic, Fast and Lightweight Web Scraper for Python
Binance Public API Connector Python
- GitHub - binance/binance-connector-python: a simple connector to Binance Public API
- Binance Public API Connector Python — binance-connector documentation
- 使用 Python 在 Binance 上進行實時加密硬幣爆漲行情檢測|方格子 vocus
Developers Forum
GUI Frameworks
- NiceGUI is an easy-to-use, Python-based UI framework, which shows up in your web browser. You can create buttons, dialogs, Markdown, 3D scenes, plots and much more.
Python 開發工具
- auto-py-to-exe - Converts .py to .exe using a simple graphical interface
- FastScheduler - Python 定時任務排程,Simple, lightweight task scheduler for Python with async support, timezone handling, cron expressions, and a beautiful real-time dashboard.
pip
Installation
Tutorials
NOTE: The following commands still require internet connection.
get-pip.py
# Latest version of python
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
# For python 2.7.x
curl https://bootstrap.pypa.io/2.7/get-pip.py -o get-pip.py
# Offline Install the pip
sudo pyhon get-pip.py
# Install pip
python3 -m pip install pipUpdate the pip
pip install --upgrade pip
python3 -m pip install --upgrade pipModule install
# Downloading the source files required for the module mkdocs, which requires an internet.
pip download -d <output-dir> mkdocs
# Offline install the module mkdocs
pip install <output-dir>/*.whl
Proxy server
pip install --proxy http://<usr_name>:<password>@<proxyserver_name>:<port#> <pkg_name> pip config set global.proxy http://account:password@xxx.com.tw:8080
pip config set global.trusted-host pypi.python.org\npypi.org\nfiles.pythonhosted.orgCommand
List installed modules
sudo pip listUpgrade module
sudo pip install --upgrade <MODULENAME>Export the list of installed modules
pip freeze > requirements.txtInstall modules in requirements.txt
pip install -r requirements.txtCheck if the specified module was already installed
python3 -c "import tensorrt_llm"
Q & A
ERROR: Could not find a version that satisfies the requirement XXXX (from versions: none)
執行 pip install XXXX 時發生上述錯誤。
Solution:
改成這個指令:python -m pip install XXXX
Example: IP Geolocation Tool
maxmind_db_ip_geolocator.py
Original Post: Python Basics for Hackers, Part 4: How to Find the Exact Location of any IP Address
#! /usr/bin/python
#Hello fellow hackers! My name is Defalt
#I built a very basic version of this tool a long time ago and recently did a re-write
#The first re-write had some awkward usage of the argparse module, so this update is going to fix it
#Original version: http://pastebin.com/J5NLnThL
#This will query the MaxMind database to get an approximate geolocation of an IP address
#Happy hacking! -Defalt
import sys
import socket
import urllib
import gzip
import os
try:
import pygeoip
except ImportError:
print '[!] Failed to Import pygeoip'
try:
choice = raw_input('[*] Attempt to Auto-install pygeoip? [y/N] ')
except KeyboardInterrupt:
print '\n[!] User Interrupted Choice'
sys.exit(1)
if choice.strip().lower()[0] == 'y':
print '[*] Attempting to Install pygeoip... ',
sys.stdout.flush()
try:
import pip
pip.main(['install', '-q', 'pygeoip'])
import pygeoip
print '[DONE]'
except Exception:
print '[FAIL]'
sys.exit(1)
elif choice.strip().lower()[0] == 'n':
print '[*] User Denied Auto-install'
sys.exit(1)
else:
print '[!] Invalid Decision'
sys.exit(1)
class Locator(object):
def __init__(self, url=False, ip=False, datfile=False):
self.url = url
self.ip = ip
self.datfile = datfile
self.target = ''
def check_database(self):
if not self.datfile:
self.datfile = '/usr/share/GeoIP/GeoLiteCity.dat'
else:
if not os.path.isfile(self.datfile):
print '[!] Failed to Detect Specified Database'
sys.exit(1)
else:
return
if not os.path.isfile(self.datfile):
print '[!] Default Database Detection Failed'
try:
choice = raw_input('[*] Attempt to Auto-install Database? [y/N] ')
except KeyboardInterrupt:
print '\n[!] User Interrupted Choice'
sys.exit(1)
if choice.strip().lower()[0] == 'y':
print '[*] Attempting to Auto-install Database... ',
sys.stdout.flush()
if not os.path.isdir('/usr/share/GeoIP'):
os.makedirs('/usr/share/GeoIP')
try:
urllib.urlretrieve('http://geolite.maxmind.com/download/geoip/database/GeoLiteCity.dat.gz', '/usr/share/GeoIP/GeoLiteCity.dat.gz')
except Exception:
print '[FAIL]'
print '[!] Failed to Download Database'
sys.exit(1)
try:
with gzip.open('/usr/share/GeoIP/GeoLiteCity.dat.gz', 'rb') as compressed_dat:
with open('/usr/share/GeoIP/GeoLiteCity.dat', 'wb') as new_dat:
new_dat.write(compressed_dat.read())
except IOError:
print '[FAIL]'
print '[!] Failed to Decompress Database'
sys.exit(1)
os.remove('/usr/share/GeoIP/GeoLiteCity.dat.gz')
print '[DONE]\n'
elif choice.strip().lower()[0] == 'n':
print '[!] User Denied Auto-Install'
sys.exit(1)
else:
print '[!] Invalid Choice'
sys.exit(1)
def query(self):
if not not self.url:
print '[*] Translating %s: ' %(self.url),
sys.stdout.flush()
try:
self.target += socket.gethostbyname(self.url)
print self.target
except Exception:
print '\n[!] Failed to Resolve URL'
return
else:
self.target += self.ip
try:
print '[*] Querying for Records of %s...\n' %(self.target)
query_obj = pygeoip.GeoIP(self.datfile)
for key, val in query_obj.record_by_addr(self.target).items():
print '%s: %s' %(key, val)
print '\n[*] Query Complete!'
except Exception:
print '\n[!] Failed to Retrieve Records'
return
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser(description='IP Geolocation Tool')
parser.add_argument('--url', help='Locate an IP based on a URL', action='store', default=False, dest='url')
parser.add_argument('-t', '--target', help='Locate the specified IP', action='store', default=False, dest='ip')
parser.add_argument('--dat', help='Custom database filepath', action='store', default=False, dest='datfile')
args = parser.parse_args()
if ((not not args.url) and (not not args.ip)) or ((not args.url) and (not args.ip)):
parser.error('invalid target specification')
try:
locate = Locator(url=args.url, ip=args.ip, datfile=args.datfile)
locate.check_database()
locate.query()
except Exception:
print '\n[!] An Unknown Error Occured'Tips
編碼 UTF-8 宣告
#!/usr/bin/python
# -*- coding: utf-8 -*-Find all installed modules
help("modules");目前環境的模組安裝路徑
import powerline
powerline.__path__
# Return ['/home/alang/.local/lib/python3.10/site-packages/powerline']print( ... , end=" ")輸出結尾以空白代替換行print("[" + str(left) + "|")不同型態資料不可串接,必須用str()轉換print()只換行但沒有內容輸出print(, file=sys.stderr): 輸出的方式,預設是sys.stdout(標準輸出)
for left in range(7):
for right in range(left, 7):
print("[" + str(left) + "|" + str(right) + "]", end=" ")
print()Print the List with join()
greetings = ["Hello", "world"]
print(" ".join(greetings)) # Prints "Hello world"Timestamp
timestamp = datetime.datetime.now()
print("It is {}".format(timestamp.strftime("%A %d %B %Y %I:%M:%S%p")))Math
total += 1If-else
# Boolean, none
if motion is not None:
if not flag:
# Number
if delay > 0:
if delay == 0:
if total > frameCount:
# String
if "blue" in style:
if authors.startswith('['):
authors = authors.lstrip('[').rstrip(']')
# One-liner
def doi_url(d): return f'http://{d}' if d.startswith('doi.org') else f'http://doi.org/{d}'
# Multiple conditions
temperature = 25
if temperature > 30:
print('Hot')
elif temperature > 20 and temperature <= 30:
print('Warm')
else:
print('Cool')
# Reverse the True
temperature = 15
if not temperature > 20:
print('Cool')
#
temperature = 25
humidity = 55
rain = 0
if temperature > 30 or humidity < 70 and not rain > 0:
print('Dry conditions')
# Logical operators, AND, OR, NOT
if status >= 200 and status <= 226:
if status == 100 or status == 102:
if not(status >= 200 and status <= 226):operator
|
operator |
use |
|---|---|
|
> |
greater than |
|
< |
less than |
|
>= |
greater than or equal to |
|
<= |
less than or equal to |
|
== |
equal to |
|
!= |
not equal to |
sys.argv
- 簡易版 Script 參數傳遞
import sys
logfile = sys.argv[1]
with open(logfile) as f:
for line in f:
if "CRON" not in line:
continue
print(line.strip())argparse
- 進階版 Script 參數傳遞
- Manual: https://docs.python.org/3/library/argparse.html
import argparse
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--interval", required=False,
help="Seconds to Interval (Default:30)", default="30", type=int)
ap.add_argument("-o", "--output", required=False,
help="Path to Output Logs (Default:std-out)")
ap.add_argument("mac",
help="MAC address of LYWSD02 device", nargs="+")
args = vars(ap.parse_args())
# Usage
intv = args["interval"]
logfile = args["output"]from argparse import ArgumentParser
def _get_args():
parser = ArgumentParser()
parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH,
help="Checkpoint name or path, default to %(default)r")
parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only")
parser.add_argument("--share", action="store_true", default=False,
help="Create a publicly shareable link for the interface.")
parser.add_argument("--inbrowser", action="store_true", default=False,
help="Automatically launch the interface in a new tab on the default browser.")
parser.add_argument("--server-port", type=int, default=8000,
help="Demo server port.")
parser.add_argument("--server-name", type=str, default="127.0.0.1",
help="Demo server name.")
args = parser.parse_args()
return args
def _test_args(args);
if args.cpu_only:
device_map = "cpu"
else:
device_map = "auto"
ckp_path = args.checkpoint_path
return device_map, ckp_path
def main():
args = _get_args()
device_map, ckp_path = _test_args(args)
if __name__ == '__main__':
main()#
# Nagios2 HTTP proxy test
#
# usage: check_http_proxy --proxy=proxy:port --auth=user:pass --url=url --timeout=10 --warntime=5 --expect=content
import sys
import getopt
def get_cmdline_cfg():
try:
opts, args = getopt.getopt(
sys.argv[1:],
"p:a:t:w:e:u:",
["proxy=", "auth=", "timeout=", "warntime=", "expect=", "url="]
)
except getopt.GetoptError, err:
print("SCRIPT CALLING ERROR: {0}".format(str(err)))
### Build cfg dictionary
cfg = {}
for o, a in opts:
if o in ("-p", "--proxy"):
cfg["proxy"] = a
elif o in ("-a","--auth"):
cfg["auth"] = a
elif o in ("-t","--timeout"):
cfg["timeout"] = float(a)
elif o in ("-w","--warntime"):
cfg["warntime"] = float(a)
elif o in ("-e","--expect"):
cfg["expect"] = a
elif o in ("-u","--url"):
cfg["url"] = a
# These are required
for req_param in ("url", "proxy"):
if req_param not in cfg:
print("Missing parameter: {0}".format(req_param))
return cfg
# Usage
if __name__ == '__main__':
cfg = get_cmdline_cfg()
if "auth" in cfg:
proxy_url = "http://{auth}@{proxy}/".format(**cfg)
else:
proxy_url = "http://{proxy}/".format(**cfg)
Reading and Writing files
Open mode
- r : Read only (default)
- w : Write only
- a : Append
- r+ : Read-Write
- t : Text mode (default)
- b : Binary mode
- x : open for exclusive creation, failing if the file already exists
Read file: 一次讀取一行,內容輸出為 String 格式
Tip: 用 with 開檔時,不需要另外做關閉檔案動作。
with open("spider.txt") as file:
for line in file:
print(line.strip().upper())Read file: 一次讀取整個檔案,內容輸出為 List 格式
file = open("spider.txt")
lines = file.readlines()
file.close()
lines.sort()
print(lines)Write a file: 內容輸入為 String 格式,如果寫檔成功,回傳 string 的字元長度
with open("novel.txt", "w") as file:
file.write("It was a dark and stormy night")
# Return 30
# when successful, return the length of the stringguests = open("guests.txt", "w")
initial_guests = ["Bob", "Andrea", "Manuel", "Polly", "Khalid"]
for i in initial_guests:
guests.write(i + "\n")
guests.close()Read and Write file
# Read a txt file
with open("update_log.txt", "r") as file:
updates = file.read()
print(updates)
# Write a txt file
# With both "w" and "a", you can use the .write() method
# "a" if you want to append to a file
line = "jrafael,192.168.243.140,4:56:27,True"
with open("access_log.txt", "w") as file:
file.write(line)
# Write a CSV or multi-lines file
login_file = """username,ip_address,time,date
tshah,192.168.92.147,15:26:08,2022-05-10
dtanaka,192.168.98.221,9:45:18,2022-05-09
tmitchel,192.168.110.131,14:13:41,2022-05-11
daquino,192.168.168.144,7:02:35,2022-05-08
eraab,192.168.170.243,1:45:14,2022-05-11
jlansky,192.168.238.42,1:07:11,2022-05-11
acook,192.168.52.90,9:56:48,2022-05-10
"""
with open("login.txt", "w") as file:
file.write(login_file)Encoding: 如果沒有指定,就以作業系統設定為主
f = open('workfile', 'w', encoding="utf-8")
with open('log_file', mode='r',encoding='UTF-8') as file:
for log in file.readlines():File and Directory
Managing files
import os
os.remove("novel.txt")
os.rename("first_draft.txt", "finished_masterpiece.txt")
os.path.exists("finished_masterpiece.txt")
# Return True or False
os.path.getsize("spider.txt")
#This code will provide the file size
import datetime
timestamp = os.path.getmtime("spider.txt")
datetime.datetime.fromtimestamp(timestamp)
#This code will provide the date and time for the file in an
#easy-to-understand format
os.path.abspath("spider.txt")
#This code takes the file name and turns it into an absolute pathManaging directories
os.mkdir("new_dir")
#The os.mkdir("new_dir") function creates a new directory called new_dir
os.chdir("new_dir")
os.getcwd()
#This code snippet changes the current working directory to new_dir.
#The second line prints the current working directory.
os.mkdir("newer_dir")
os.rmdir("newer_dir")
#This code snippet creates a new directory called newer_dir.
#The second line deletes the newer_dir directory.
import os
os.listdir("website")
#This code snippet returns a list of all the files and
#sub-directories in the website directory.
dir = "website"
for name in os.listdir(dir):
fullname = os.path.join(dir, name)
if os.path.isdir(fullname):
print("{} is a directory".format(fullname))
else:
print("{} is a file".format(fullname))Using os module
# Create a directory and move a file from one directory to another
# using low-level OS functions.
import os
# Check to see if a directory named "test1" exists under the current
# directory. If not, create it:
dest_dir = os.path.join(os.getcwd(), "test1")
if not os.path.exists(dest_dir):
os.mkdir(dest_dir)
# Construct source and destination paths:
src_file = os.path.join(os.getcwd(), "sample_data", "README.md")
dest_file = os.path.join(os.getcwd(), "test1", "README.md")
# Move the file from its original location to the destination:
os.rename(src_file, dest_file)Using pathlib module
# Create a directory and move a file from one directory to another
# using Pathlib.
from pathlib import Path
# Check to see if the "test1" subdirectory exists. If not, create it:
dest_dir = Path("./test1/")
if not dest_dir.exists():
dest_dir.mkdir()
# Construct source and destination paths:
src_file = Path("./sample_data/README.md")
dest_file = dest_dir / "README.md"
# Move the file from its original location to the destination:
src_file.rename(dest_file)os.environ
.copy(): 複製目前環境變數成新的 dictiorary- .get(NAME, "") : 取得 NAME 變數內容
my_env["PATH"]: 修改 PATH 的內容
import os
import subprocess
my_env = os.environ.copy()
my_env["PATH"] = os.pathsep.join(["/opt/myapp/", my_env["PATH"]])
result = subprocess.run(["myapp"], env=my_env)import os
print("HOME: " + os.environ.get("HOME", ""))
print("SHELL: " + os.environ.get("SHELL", ""))
print("FRUIT: " + os.environ.get("FRUIT", ""))input
- input() : 輸出 string 資料格式
def to_seconds(hours, minutes, seconds):
return hours*3600+minutes*60+seconds
print("Welcome to this time converter")
cont = "y"
while(cont.lower() == "y"):
hours = int(input("Enter the number of hours: "))
minutes = int(input("Enter the number of minutes: "))
seconds = int(input("Enter the number of seconds: "))
print("That's {} seconds".format(to_seconds(hours, minutes, seconds)))
print()
cont = input("Do you want to do another conversion? [y to continue] ")
print("Goodbye!")subprocess
Run system commands in Python
- subprocess 子程序執行時,主 script (父程序) 會暫時阻斷,直到子程序結束
- 無特定參數時,只適用於子程序執行成功與否
- 子程序的執行參數以 List 格式傳入,例如 ["command", "opt1", "opt2"]
.returncode: 結束狀態碼,0 是成功;1 是失敗.stderr: 錯誤訊息,資料類型是位元陣列(An array of bytes),可用decode()轉換成 string 格式
import subprocess
subprocess.run(["date"])
subprocess.run(["sleep", "2"])
result = subprocess.run(["ls", "this_file_does_not_exist"])
print(result.returncode)
print(result.stderr)run( , capture_output=True): 可以擷取指令的輸出內容 (python 3.7+ 支援).stdout: 標準輸出,資料類型是位元陣列(An array of bytes),可用decode()轉換成 string 格式
result = subprocess.run(["host", "8.8.8.8"], capture_output=True)
print(result.stdout)
# Output: b'8.8.8.8.in-addr.arpa domain name pointer dns.google.\n'
result = subprocess.run(["host", "8.8.8.8"], capture_output=True)
print(result.stdout.decode().split())run(, env=my_env): 結合環境變數
import os
import subprocess
my_env = os.environ.copy()
my_env["PATH"] = os.pathsep.join(["/opt/myapp/", my_env["PATH"]])
result = subprocess.run(["myapp"], env=my_env)run(, capture_output=True, text=True): 輸出字串不需要做 decode
result_run = subprocess.run(['echo', 'Hello, World!'], capture_output=True, text=True)
result_run.stdout.strip() # Extracting the stdout and stripping any extra whitespace
# Output: 'Hello, World!'check_call(): 傳回外部指令的狀態碼
return_code_check_call = subprocess.check_call(['echo', 'Hello from check_call!'])
print(return_code_check_call)
# Output 0check_output(): 傳回外部指令的輸出結果
output_check_output = subprocess.check_output(['echo', 'Hello from check_output!'], text=True)
output_check_output.strip() # Extracting the stdout and stripping any extra whitespace
# Output 'Hello from check_output!'Popen(): 進階版的執行方式,可連接 input/output/error 導管,背景執行.poll(): 如果是 NONE,表示指令仍執行中
process_popen = subprocess.Popen(['echo', 'Hello from popen!'], stdout=subprocess.PIPE, text=True)
output_popen, _ = process_popen.communicate()
output_popen.strip() # Extracting the stdout and stripping any extra whitespace
# Output: 'Hello from popen!'process = subprocess.Popen(['sleep', '5'])
message_1 = "The process is running in the background..."
# Give it a couple of seconds to demonstrate the asynchronous behavior
import time
time.sleep(2)
# Check if the process has finished
if process.poll() is None:
message_2 = "The process is still running."
else:
message_2 = "The process has finished."
print(message_1, message_2)- 模組 os , Pathlib 提供某些相同的系統操作,應該優先使用
# subprocess
subprocess.run(['mkdir', 'test_dir_subprocess2'])
# OS
os.mkdir('test_dir_os2')
# Pathlib
test_dir_pathlib2 = Path('test_dir_pathlib2')
test_dir_pathlib2.mkdir(exist_ok=True) #Ensures the directory is created only if it doesn't already existlogging
Level: DEBUG, INFO, WARNING, ERROR, CRITICAL
import logging
logging.warning('This is a warning message')
logging.error('This is an error message')
logging.basicConfig(level=logging.DEBUG)
logging.debug('This is a debug message')
logging.basicConfig(filename='app.log', level=logging.DEBUG)
logging.info('This message will be written to app.log')
logging.basicConfig(format='%(asctime)s - %(levelname)s - %(message)s', level=logging.DEBUG)
logging.error('This is an error with a custom format')Functions
參數類型定義範例
def _gpt_parse_images(
image_infos: List[Tuple[str, List[str]]],
prompt_dict: Optional[Dict] = None,
output_dir: str = './',
api_key: Optional[str] = None,
base_url: Optional[str] = None,
model: str = 'gpt-4o',
verbose: bool = False,
gpt_worker: int = 1,
**args
) -> str:
"""
Parse images to markdown content.
"""Print and Log
def print_f(*msg):
'''print and log!'''
# import datetime for timestamps
import datetime as dt
# convert input arguments to strings for concatenation
message = []
for m in msg:
message.append(str(m))
message = ' '.join(message)
# append to the log file
with open('/tmp/test.log','a') as log:
log.write(f'{dt.datetime.now()} | {message}\n')
# print the message using the copy of the original print function to stdout
print(message)
print_f('Test Message')Sendmail via SMTP
def send_message(body, subject, to_addr):
import smtplib
from email.message import EmailMessage
smtp_user = "your-smtp-user"
smtp_pass = "your-smtp-pass"
smtp_server = "smtp-relay.your.server"
smtp_port = "587"
msg = EmailMessage()
msg['Subject'] = subject
msg['From'] = smtp_user
msg['To'] = to_addr
msg.set_content(body)
with smtplib.SMTP(smtp_server, smtp_port) as smtp:
smtp.login(smtp_user, smtp_pass)
smtp.send_message(msg)
debug = send_message("This is plain TEXT email", "Test from SMTP", "alang.hsu@gmail.com")
print(debug)Check Disk Usage
import shutil
import sys
def check_disk_usage(disk, min_absolute, min_percent):
"""Returns True if there is enough free disk space, false otherwise."""
du = shutil.disk_usage(disk)
# Calculate the percentage of free space
percent_free = 100 * du.free / du.total
# Calculate how many free gigabytes
gigabytes_free = du.free / 2**30
if percent_free < min_percent or gigabytes_free < min_absolute:
return False
return True
# Check for at least 2 GB and 10% free
if not check_disk_usage("/", 2, 10):
print("ERROR: Not enough disk space")
sys.exit(1)
print("Everything ok")
sys.exit(0)Check Internet
import socket
def check_no_network():
"""Returns True if it fails to resolve Google's URL, False otherwise."""
try:
socket.gethostbyname("www.google.com")
return False
except:
return True
THSRC API
Links
- TDX 運輸資料通服務
- TDX 會員註冊
- TDX運輸資料流通服務API介接範例程式碼說明
- TDX - 高鐵 API 說明
- 雙鐵API資料使用注意事項
- API 虛擬點數機制
- MOTC Transport API V2 (臺鐵、高鐵、捷運)
API 連線認證
- Client Id: 透過官網取得
- Client Secret: 透過官網取得
- Access Token: 使用 HTTP POST 帶入Client Id 和 Client Secret 進行驗證以取得 Access Token。
Get Access Token
curl --request POST \
--url 'https://tdx.transportdata.tw/auth/realms/TDXConnect/protocol/openid-connect/token' \
--header 'content-type: application/x-www-form-urlencoded' \
--data grant_type=client_credentials \
--data client_id=YOUR_CLIENT_ID \
--data client_secret=YOUR_CLIENT_SECRET \回傳內容格式:
- access_token: 用於存取API服務的token,格式為JWT
- expires_in:token的有效期限,單位為秒,預設為86400秒(1天)
- token_type:token類型,固定為"Bearer"
Case: 指定日期、時間區間與起訖站,列出對號座即時剩餘座位資訊
API:
/v2/Rail/THSR/DailyTimetable/Station/{StationID}/{TrainDate}
- 取得指定日期,車站的站別時刻表
- 依時間區間過濾,篩選出車次號碼
/v2/Rail/THSR/AvailableSeatStatus/Train/OD/{OriginStationID}/to/{DestinationStationID}/TrainDate/{TrainDate}- 取得指定[日期], [起迄站]對號座即時剩餘位資料
- 依車次號碼查詢剩餘座位
NOTE: 剩餘座位資料更新間隔,如果是今天,頻率為每十分鐘;如果不是今天,頻率為每日的 10, 16, 22 時。
MCP Server
- MCP Server THSRC - 台灣高鐵資訊查詢服務
JSON
Tutorials
JSON to dict
json.loads 用來轉換資料; json.load 用來讀檔。
import json
person = '{"name": "Bob", "languages": ["English", "French"]}'
person_dict = json.loads(person)
# Output: {'name': 'Bob', 'languages': ['English', 'French']}
print( person_dict)
# Output: ['English', 'French']
print(person_dict['languages'])Dict to JSON
import json
person_dict = {'name': 'Bob',
'age': 12,
'children': None
}
person_json = json.dumps(person_dict)
# Output: {"name": "Bob", "age": 12, "children": null}
print(person_json)Read JSON file
import json
with open('path_to_file/person.json', 'r') as f:
data = json.load(f)
# Output: {'name': 'Bob', 'languages': ['English', 'French']}
print(data)Write JSON file
json.dump 用來寫檔案; json.dumps 用來轉換資料。
import json
person_dict = {"name": "Bob",
"languages": ["English", "French"],
"married": True,
"age": 32
}
with open('person.txt', 'w') as json_file:
json.dump(person_dict, json_file)Print JSON
import json
person_string = '{"name": "Bob", "languages": "English", "numbers": [2, 1.6, null]}'
# Getting dictionary
person_dict = json.loads(person_string)
# Pretty Printing JSON string back
print(json.dumps(person_dict, indent = 4, sort_keys=True))Access JSON
import json
json_data = '''
{
"students": [
{
"name": "David",
"age": 19,
"grades": {
"math": 90,
"english": 87
}
},
{
"name": "Harry",
"age": 21,
"grades": {
"math": 85,
"english": 95
}
}
]
}
'''
# Parse JSON Data
data = json.loads(json_data)
# To access a large dataset we can use `for loop`
for student in data["students"]:
name = student["name"]
math_mark = student["grades"]["math"]
english_mark = student["grades"]["english"]
average_mark = (math_mark + english_mark) / 2
print(f"{name}, Avarage Marks: {average_mark:.2f}")
# Output:
# David, Average Marks: 88.50
# Harry, Average Marks: 90.00import json
original_data_file="students_data.json"
updated_data_file="students_data_updated.json"
# reading `JSON file`
with open(original_data_file,"r") as file:
students_result = json.load(file)
# Updating JSON Data
for student in students_result['students']:
print(student['name'])
if student['name'] == "Kabir":
student['name'] = "John"
grades = student['grades']
avarage_mark= sum(grades.values()) / len(grades)
student['avarage_mark'] = avarage_mark
# Saving updated data into a new file
with open(updated_data_file,"w") as file:
json.dump(students_result,file,indent=4)Get JSON from URL
import requests, json
# Response will be saved here
weather_data="weather_data.json"
# Request to `openweathermap` API
api_key = "6423af6e554f98cf1e6b8c6a7700986b" #REPLACE_WITH_YOUR_API_KEY
location = "Dhaka"
url = f"https://api.openweathermap.org/data/2.5/weather?q={location}&appid={api_key}&units=metric"
# Response
response = requests.get(url)
# Get `Place` and `Temperature` from the Response
if response.status_code == 200:
json_data = response.json()
print(f"Place: {json_data['name']}, Temperature: {json_data['main']['temp']} celsius")
else:
print(f"Request failed with status code {response.status_code}")
# Save the Response to a file
with open(weather_data,"w") as file:
json.dump(json_data,file,indent=4)
# Output:
# Place: Dhaka, Temperature: 27.99 celsius# Handling a JSONDecodeError in Python
from json import JSONDecodeError
import requests
resp = requests.get('https://reqres.in/api/users/page4')
try:
resp_dict = resp.json()
except JSONDecodeError:
print('Response could not be serialized')Data Type
使用 json.loads 轉換資料型別時,要注意輸出的類型可能是 dict 或者 array,這要看原始JSON 的資料格式。
| JSON |
Python |
| object |
dict |
| array |
list |
| string |
str |
| number (integer) |
int |
| number (real) |
float |
| true |
True |
| false |
False |
| null |
N |
Library
{
"employees": [
{
"id": 1,
"name": "Pankaj",
"salary": "10000"
},
{
"name": "David",
"salary": "5000",
"id": 2
}
]
}import json
from jsonpath_ng import jsonpath, parse
with open("db.json", 'r') as json_file:
json_data = json.load(json_file)
print(json_data)
jsonpath_expression = parse('employees[*].id')
for match in jsonpath_expression.find(json_data):
print(f'Employee id: {match.value}'){'employees': [{'id': 1, 'name': 'Pankaj', 'salary': '10000'}, {'name': 'David', 'salary': '5000', 'id': 2}]}
Employee id: 1
Employee id: 2Datetime
時間格式代碼
%d:以十進製表示的月份中的第幾天,填充零。%m:十進製表示的月份,零填充。%y:以零填充的十進製表示法的年份的最後兩位數字。%Y:以十進製表示的四位年份數字,零填充。%H:當以十進製表示並填充零時(24 小時制)%I:當以十進製表示並填充零時(12 小時制)%M:用於填充零的十進製表示法。%S:以十進製表示的秒數,填充零。%f:十進製表示法中的微秒(6 位),填充 0。%A:區域設置的星期幾的名稱%a:區域設置的日期名稱(縮寫形式)%B:語言環境月份名稱%b:語言環境月份名稱(縮寫形式)%j:以十進制記數法表示的年份中的第幾天,零填充。%U:以十進製表示的年份中的周數,零填充(該週從星期日開始)%W:以十進製表示的年份週數,零填充(每週從星期一開始)
Today, Now
import datetime
dt_now = datetime.datetime.now()
print(dt_now)
# 2018-02-02 18:31:13.271231
print(type(dt_now))
# <class 'datetime.datetime'>
print(dt_now.year)
# 2018
print(dt_now.hour)
# 18String to Datetime
strptime(): 從字符串到日期和時間的轉換
from datetime import datetime
date_str = '09-19-2022'
date_object = datetime.strptime(date_str, '%m-%d-%Y').date()
print(type(date_object))
print(date_object) # printed in default format
# Output:
# <class 'datetime.date'>
# 2022-09-19from datetime import datetime
time_str = '13::55::26'
time_object = datetime.strptime(time_str, '%H::%M::%S').time()
print(type(time_object))
print(time_object)
# Output:
# <class 'datetime.time'>
# 13:55:26from datetime import datetime
import locale
locale.setlocale(locale.LC_ALL, 'de_DE')
date_str_de_DE = '16-Dezember-2022 Freitag' # de_DE locale
datetime_object = datetime.strptime(date_str_de_DE, '%d-%B-%Y %A')
print(type(datetime_object))
print(datetime_object)
# Output:
# <class 'datetime.datetime'>
# 2022-12-16 00:00:00date
- strftime() : 從日期和時間到字符串的轉換
import datetime
d = datetime.date(2020,1,1) # 2020-01-01import datetime
today = datetime.date.today()
print(today) # 2021-10-19
print(today.year) # 2021
print(today.month) # 10
print(today.day) # 19
print(today.weekday()) # 1 ( 因為是星期二,所以是 1 )
print(today.isoweekday()) # 2 ( 因為是星期二,所以是 2 )
print(today.isocalendar()) # (2021, 42, 2) ( 第三個數字是星期二,所以是 2 )
print(today.isoformat()) # 2021-10-19
print(today.ctime()) # Tue Oct 19 00:00:00 2021
print(today.strftime('%Y.%m.%d')) # 2021.10.19
newDay = today.replace(year=2020)
print(newDay) # 2020-10-19import datetime
d1 = datetime.date(2020, 6, 24)
d2 = datetime.date(2021, 11, 24)
print(abs(d1-d2).days) # 518time
import datetime
thisTime = datetime.time(12,0,0,1)
print(thisTime) # 12:00:00.000001import datetime
thisTime = datetime.time(14,0,0,1,tzinfo=datetime.timezone(datetime.timedelta(hours=8)))
print(thisTime) # 14:00:00.000001+08:00
print(thisTime.isoformat()) # 14:00:00.000001+08:00
print(thisTime.tzname()) # UTC+08:00
print( thisTime.strftime('%H:%M:%S')) # 14:00:00
newTime = today.replace(hour=20)
print(newTime) # 20:00:00.000001+08:00datetime
datetime.datetime:日期和時間(日期和時間)datetime.date:日期datetime.time:時間datetime.timedelta:時差和經過時間
import datetime
thisTime = datetime.datetime(2020,1,1,20,20,20,20)
print(thisTime) # 2020-01-01 20:20:20.000020import datetime
print(datetime.datetime.today()) # 2021-10-19 06:15:46.022925
print(datetime.datetime.now(tz=datetime.timezone(datetime.timedelta(hours=8))))
# 2021-10-19 14:15:46.027982+08:00
print(datetime.datetime.utcnow()) # 2021-10-19 06:15:46.028630import datetime
now = datetime.datetime.now(tz=datetime.timezone(datetime.timedelta(hours=8)))
print(now) # 2021-10-19 14:25:46.962975+08:00
print(now.date()) # 2021-10-19
print(now.time()) # 14:25:46.962975
print(now.tzname()) # UTC+08:00
print(now.weekday()) # 1
print(now.isoweekday()) # 2
print(now.isocalendar()) # (2021, 42, 2)
print(now.isoformat()) # 2021-10-19 14:25:46.962975+08:00
print(now.ctime()) # Tue Oct 19 14:48:38 2021
print(now.strftime('%Y/%m/%d %H:%M:%S')) # 2021/10/19 14:48:38
print(now.timetuple()) # time.struct_time(tm_year=2021, tm_mon=10, tm_mday=19, tm_hour=16, tm_min=8, tm_sec=6, tm_wday=1, tm_yday=292, tm_isdst=-1)timedelta
日期/時間計算
import datetime
today = datetime.datetime.now()
yesterday = today - datetime.timedelta(days=1)
tomorrow = today + datetime.timedelta(days=1)
nextweek = today + datetime.timedelta(weeks=1)
print(today) # 2021-10-19 07:01:22.669886
print(yesterday) # 2021-10-18 07:01:22.669886
print(tomorrow) # 2021-10-20 07:01:22.669886
print(nextweek) # 2021-10-26 07:01:22.669886Timezone
import datetime
tzone = datetime.timezone(datetime.timedelta(hours=8))
now = datetime.datetime.now(tz=tzone)
print(now) # 2021-10-19 15:07:51.128092+08:00from datetime import datetime, timezone
# Get the current time in UTC
utc_time = datetime.now(timezone.utc)
print(utc_time)from datetime import datetime
import pytz
timezone = pytz.timezone("America/New_York")
current_time_in_timezone = datetime.now(timezone)
print(current_time_in_timezone)Sleep
import time
time.sleep(5) # Pauses the code for 5 secondsTimestamp
Get Current Time in Milliseconds
milliseconds_since_epoch = time.time() * 1000Get Current Timestamp
current_timestamp = time.time()
print(current_timestamp)Timestamp to a human-readable date
timestamp = time.time()
readable_date = datetime.fromtimestamp(timestamp)
print(readable_date)Time Diff.
time1 = datetime.now()
# ... some operations ...
time2 = datetime.now()
difference = time2 - time1
print(difference)start_time = time.time()
# ... some operations ...
end_time = time.time()
elapsed_time = end_time - start_time
print(f"Time elapsed: {elapsed_time} seconds")函式:日期轉換週
import datetime
def dow(date):
dateobj = datetime.datetime.strptime(date, r"%Y-%m-%d")
return dateobj.strftime("%A")
date_str = "2024-12-11"
print(dow(date_str)) # Output: Wednesday函式:隔年日期
import datetime
from datetime import date
def add_year(date_obj):
try:
new_date_obj = date_obj.replace(year = date_obj.year + 1)
except ValueError:
# This gets executed when the above method fails,
# which means that we're making a Leap Year calculation
new_date_obj = date_obj.replace(year = date_obj.year + 4)
return new_date_obj
def next_date(date_string):
# Convert the argument from string to date object
date_obj = datetime.datetime.strptime(date_string, r"%Y-%m-%d")
next_date_obj = add_year(date_obj)
#print("DEBUG", next_date_obj)
# Convert the datetime object to string,
# in the format of "yyyy-mm-dd"
next_date_string = next_date_obj.strftime("%Y-%m-%d")
return next_date_string
today = date.today() # Get today's date
#print("DEBUG Today: ", today)
print(next_date(str(today)))
# Should return a year from today, unless today is Leap Day
print(next_date("2021-01-01")) # Should return 2022-01-01
print(next_date("2020-02-29")) # Should return 2024-02-29
Resources
One-Liners
1) Multiple Variable Assignment
# Traditional way
a = 1
b = "ok"
c = False
# Pythonic way
a, b, c = 1, "ok", False
# Result
print(a, b, c)
# Show: 1 ok False2) Variable Swap
# Traditional way
a = 1
b = "ok"
c = a
a = b
b = c
# Pythonic way
a, b = 1, "ok"
a, b = b, a
# Result
print(a, b)
# Shows: ok 1# Pythonic way
a, b, c, d = 1, "ok", True, ["i", "j"]
a, b, c, d = c, a, d, b
# Result
print(a, b, c, d)
# Shows: True 1 ["i", "j"] ok3) Variable Conditional Assignment
x = 3
# Traditional way
if x % 2 == 1:
result = f"{x} is odd"
else:
result = f"{x} is even"
# Pythonic way
result = f"{x} " + ("is odd" if x % 2 == 1 else "is even")
# Result
print(result)
# Shows: 3 is odd4) Presence of a Value in a List
pet_list = ["cat", "dog", "parrot"]
# Traditional way
found = False
for item in my_list:
if item == "cat":
found = True
break
# Pythonic way
found = "cat" in pet_list
# Result
print(found)
# Shows: Truepet_dict = {"cat": "Mitchi", "dog": "Max", "parrot": "Pepe"}
found = "cat" in pet_dict
print(found)
# Shows: True5) Operations on Lists
my_list = [1, 2, 3, 4, 5]
# Traditional way
max_value = 0
for value in my_list:
if value > max_value:
max_value = value
# Pythonic way
max_value = max(my_list)
# Result
print(max_value)
# Shows: 56) List Creation with Duplicate Values
size = 10
# Traditional way
my_list = []
for i in range(size):
my_list.append(0)
# Pythonic way
my_list = [0] * size
# Result
print(my_list)
# Shows: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]my_list = [1, 2] * 5
# Result: [1, 2, 1, 2, 1, 2, 1, 2, 1, 2]my_tuple = (1, 2) * 5
print(my_tuple)
# Shows: (1, 2, 1, 2, 1, 2, 1, 2, 1, 2)7) List Creation with Sequential Values
count = 10
# Traditional way
my_list = []
for i in range(count):
my_list.append(i)
# Pythonic way
my_list = list(range(count))
# Result
print(my_list)
# Shows: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]# List with odd values
my_list = list(range(1, 10, 2))
print(my_list)
# Shows: [1, 3, 5, 7, 9]# List with descending values and negative values
my_list = list(range(5, -5, -1))
print(my_list)
# Shows: [5, 4, 3, 2, 1, 0, -1, -2, -3, -4]my_set = set(range(count))
my_tuple = tuple(range(count))
# Result
print(my_set)
# Shows: {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
print(my_tuple)
# Shows: (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)8) List Creation with a Loop
count = 4
# Traditional way
my_list = []
for i in range(count):
my_list.append(count**i)
# Pythonic way
my_list = [count**x for x in range(count)]
# Result
print(my_list)
# Shows: [1, 4, 16, 64]
my_set = set(count**x for x in range(count))
print(my_set)
# Shows: {1, 4, 16, 64}squares = [i * i for i in range(5)]
# [0, 1, 4, 9, 16]
squares = [i * i for i in range(5) if i % 2 == 0]
# [0, 4, 16]9) List Creation with Conditions if-else
users = [("Megan", 56),
("Karen", 32),
("Chad", 28),
("Brent", 44)]
# Traditional way
young_users = []
for user in users:
if (user[1] < 35):
young_users.append(user[0])
# Pythonic way
young_users = [x for x, y in users if y < 35]
# Result
print(young_users)
# ["Karen", "Chad"]var = 42 if 3 > 2 else 999
# 4210) Reading a File Line by Line
# Traditional way
lines = []
with open(filename) as file:
for count, line in enumerate(file):
lines.append(f"Line {count + 1}: " + line.strip())
# Pythonic way
with open(filename) as file:
lines = [f"Line {count + 1}: " + line.strip() for count, line in enumerate(file)]my_list = [line.strip() for line in open('filename.txt', 'r')]11) Print without new lines
# No need to do this:
data = [0, 1, 2, 3, 4, 5]
for i in data:
print(i, end=" ")
print()
# One-liner
print(*data)
# 0 1 2 3 4 512) Days left in year
import datetime;print((datetime.date(2023,1,1)-datetime.date.today()).days)
# 36>> python -c "import datetime;print((datetime.date(2023,1,1)-datetime.date.today()).days)"
36
>> alias daysleft='python -c "import datetime;print((datetime.date(2023,1,1)-datetime.date.today()).days)"'
>> daysleft
3613) Reversing a List
a = [1, 2, 3, 4, 5, 6]
a = a[::-1]
# [6, 5, 4, 3, 2, 1]14) 以空白做區隔的數字字串,轉換成整數 List
user_input = "1 2 3 4 5 6"
my_list = list(map(int, user_input.split()))
# [1, 2, 3, 4, 5, 6]
List 串列
串列是任何類型元素的序列,並且是可變的。用於儲存項目集合,它們可以包含任何型別的資料,並以方(中)括號表示。
a = [1, 2, 3, 4, 5]
b = ['mango', 'pineapple', 'orange']在 Python 中,List 和 String 非常相似。它們都是資料序列的範例。序列有類似的屬性,例如:
- 可以使用
for迴圈迭代序列 - 支援索引 indexing
- 使用
len()函數找出序列的長度 - 使用加號運算符
+來串連 - 使用
in關鍵字來檢查序列是否包含一個值
List 與 String 的差異是,String 內容是不可變的 (immutable);List 內容可以變動 (mutable)。
List methods
list[index] = x變更指定 index 的元素
list.append()
numbers = [1, 2, 3, 4]
numbers.append(5)
print(numbers)
# output: [1, 2, 3, 4, 5]list.insert()
animals = ["cat", "dog", "fish"]
animals.insert(1, "monkey")
print(animals)
# output: ["cat", "monkey", "dog", "fish"]
animals = ["cat", "dog", "fish"]
animals.insert(200, "monkey")
print(animals)
# output: ["cat", "dog", "fish", "monkey"]list.extend()
合併兩個 Lists
things = ["John", 42, True]
other_things = [0.0, False]
things.append(other_things)
print(things)
# output: ["John", 42, True, [0.0, False]]
things = ["John", 42, True]
other_things = [0.0, False]
things.extend(other_things)
print(things)
# output: ["John", 42, True, 0.0, False]# This function accepts two variables, each containing a list of years.
# A current "recent_first" list contains [2022, 2018, 2011, 2006].
# An older "recent_last" list contains [1989, 1992, 1997, 2001].
# The lists need to be combined with the years in chronological order.
def record_profit_years(recent_first, recent_last):
# Reverse the order of the "recent_first" list so that it is in
# chronological order.
recent_first.reverse()
# Extend the "recent_last" list by appending the newly reversed
# "recent_first" list.
recent_last.extend(recent_first)
# Return the "recent_last", which now contains the two lists
# combined in chronological order.
return recent_last
# Assign the two lists to the two variables to be passed to the
# record_profit_years() function.
recent_first = [2022, 2018, 2011, 2006]
recent_last = [1989, 1992, 1997, 2001]
# Call the record_profit_years() function and pass the two lists as
# parameters.
print(record_profit_years(recent_first, recent_last))
# Should print [1989, 1992, 1997, 2001, 2006, 2011, 2018, 2022]list.remove()
Note: If there are two of the same element in a list, the .remove() method only removes the first instance of that element and not all occurrences.
booleans = [True, False, True, True, False]
booleans.remove(False) # Removes the first False value
print(booleans)
# output: [True, True, True, False]
booleans.remove(False) # Removes the other False value
print(booleans)
# output: [True, True, True]
booleans.remove(False) # ValueError! No more False values to removelist.pop()
fruits = ["apple", "orange", "banana", "peach"]
last_fruit = fruits.pop() # takes the last element
print(last_fruit)
# output: "peach"
second_fruit = fruits.pop(1) # takes the second element ( = index 1)
print(second_fruit)
# output: "orange"
print(fruits) # only fruits that have not been "popped"
# are still in the list
# output: ["apple", "banana"]list.clear()
decimals = [0.1, 0.2, 0.3, 0.4, 0.5]
decimals.clear() # remove all values!
print(decimals)
# output: []list.count()
grades = [7.8, 10.0, 7.9, 9.5, 10.0, 6.5, 9.8, 10.0]
n = grades.count(10.0)
print(n)
# output: 3list.index()
Note: it only returns the index of the first occurrence of a list item.
friends = ["John", "James", "Jessica", "Jack"]
position = friends.index("Jessica")
print(position)
# output: 2list.sort() and list.reverse()
values = [10, 4, -2, 1, 5]
values.reverse()
print(values) # list is reversed
# output: [5, 1, -2, 4, 10]
values.sort()
print(values) # list is sorted
# output: [-2, 1, 4, 5, 10]values = [10, 4, -2, 1, 5]
values.sort(reverse=True)
print(values) # list is sorted in reverse order
# output: [10, 5, 4, 1, -2]list.copy()
values_01 = [1, 2, 3, 4]
values_02 = values_01 # not an actual copy: same list object!
values_02.append(5) # we modify the "values_02" list...
print(values_01) # ... but changes appear also in "values_01"
# because they reference the same list!
# output: [1, 2, 3, 4, 5]
values_01 = [1, 2, 3, 4]
values_02 = values_01.copy() # create an independent copy!
values_02.append(5) # we modify the "values_02" list...
print(values_01) # ... and changes DO NOT appear in "values_01"
# because it is a copy!
# output: [1, 2, 3, 4]List functions
sorted()串列的元素排序,無法用在不同 data type,不會更動變數原始內容,排序的 Key 可自訂函式min()串列裡最小值max()串列裡最大值map(function, iterable)Python - map() functionzip(*iterables)將多個不同 List 整併成一個 Tuple 資料格式
sorted()/min()/max()
time_list = [12, 2, 32, 19, 57, 22, 14]
print(sorted(time_list))
print(time_list)
names = ["Carlos", "Ray", "Alex", "Kelly"]
print(sorted(names)) # Output ['Alex', 'Carlos', 'Kelly', 'Ray']
print(names) # Output ['Carlos', 'Ray', 'Alex', 'Kelly']
print(sorted(names, key=len)) # Output ['Ray', 'Alex', 'Kelly', 'Carlos']
time_list = [12, 2, 32, 19, 57, 22, 14]
print(min(time_list))
print(max(time_list))map()
Use map() and convert the map object to a list so we can print all the results at once.
# A simple function to add 1 to a given number
def add_one(number):
return number + 1
# A list of numbers
numbers = [1, 2, 3, 4, 5]
# Use map to apply the function to each element in the list
result = map(add_one, numbers)
# Convert the map object to a list to print the result
print(list(result))
# Outputs: [2, 3, 4, 5, 6]zip()
Use zip() to combine a list of names and ages into a list of tuples, and print all the tuples at once.
# 基本 zip() 教學範例
>>> x = ['a', 'b', 'c']
>>> y = [1, 2, 3]
>>> zipped = zip(x, y)
>>> type(zipped) # 回傳的是一個 'zip' 物件,它是可迭代的
<class 'zip'>
>>> zipped
<zip object at 0x108e8bc80>
## 用 loop 遍歷 zip 物件內容
>>> for i in zip(x, y):
... print(i)
('a', 1)
('b', 2)
('c', 3)
# 也可用 list() 或 set() 將迭代器轉換成其他資料型態
>>> list(zip(x, y))
[('a', 1), ('b', 2), ('c', 3)]
>>> set(zip(x, y))
{('c', 3), ('b', 2), ('a', 1)}# Two lists
names = ["Alice", "Bob", "Charlie"]
ages = [25, 30, 35]
# Use zip to combine the lists
combined = zip(names, ages)
# Convert the zip object to a list to print the result
print(list(combined))
# Outputs: [('Alice', 25), ('Bob', 30), ('Charlie', 35)]Extracting from a list
# A element from a list
username_list = ["elarson", "fgarcia", "tshah", "sgilmore"]
print(username_list[2])
# one-liner
print(["elarson", "fgarcia", "tshah", "sgilmore"][2])
# A slice from a list
username_list = ["elarson", "fgarcia", "tshah", "sgilmore"]
print(username_list[0:2])List with Loop
animals = ["Lion", "Zebra", "Dolphin", "Monkey"]
chars = 0
for animal in animals:
chars += len(animal)
print("Total characters: {}, Average length: {}".format(chars, chars/len(animals)))
# Output: Total characters: 22, Average length: 5.5enumerate() 函式會為串列中的每個元素回傳一個 tuple(元組)。元組中的第一個值是該元素在序列中的索引。元組中的第二個值是序列中的元素
winners = ["Ashley", "Dylan", "Reese"]
for index, person in enumerate(winners):
print("{} - {}".format(index + 1, person))
# Output:
#1 - Ashley
#2 - Dylan
#3 - ReeseOutput by line + 2 "\n"
IDs = ["001","002","003","004"]
print("\n\n".join([id for id in IDs]))For + If
mylist = [1, 4, 7, 8, 20]
newlist = [x for x in mylist if x % 2 == 0]
print(newlist)Range()
mylist = ["a", "b", "c", "d", "e", "f", "g"]
for x in range(2, len(mylist) - 1):
print(mylist[x])List comprehensions
串列綜合運算。一個 list comprehension 的組成,是在一對方括號內,放入一個 expression(運算式)、一個 for 子句、再接著零個或多個 for 或 if 子句。結果會是一個新的 list,內容是在後面的 for 和 if 子句情境下,對前面運算式求值的結果
for loop vs. list comprehensions
# For Loop
multiples = []
for x in range(1,11):
multiples.append(x*7)
print(multiples)
# List comprehensions
multiples = [x*7 for x in range(1,11)]
print(multiples)
# Output [7, 14, 21, 28, 35, 42, 49, 56, 63, 70]Examples: Basic
languages = ["Python", "Perl", "Ruby", "Go", "Java", "C"]
lengths = [len(language) for language in languages]
print(lengths)
# Output [6, 4, 4, 2, 4, 1]z = [x for x in range(0,101) if x % 3 == 0]
print(z)
# Output [0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45, 48, 51, 54, 57, 60, 63, 66, 69, 72, 75, 78, 81, 84, 87, 90, 93, 96, 99]NOTE: 條件式的位置不同,List 結果也會不同
years = ["January 2023", "May 2025", "April 2023", "August 2024", "September 2025", "December 2023"]
updated_years = [year.replace("2023","2024") if year[-4:] == "2023" else year for year in years]
print(updated_years)
# Should print ["January 2024", "May 2025", "April 2024", "August 2024", "September 2025", "December 2024"]years = ["January 2023", "May 2025", "April 2023", "August 2024", "September 2025", "December 2023"]
updated_years = [year.replace("2023","2024") for year in years if year[-4:] == "2023"]
print(updated_years)
# Should print ['January 2024', 'April 2024', 'December 2024']Examples: 建立多組 Tuple 的 List
# Create a list of tuples where each tuple contains the numbers 1, 2, and 3.
numbers = [(1, 2, 3) for _ in range(5)]
# numbers: [(1, 2, 3), (1, 2, 3), (1, 2, 3), (1, 2, 3), (1, 2, 3)]Examples: 函式回傳 List
def squares(start, end):
return [ n * n for n in range(start, end+1) ]
print(squares(2, 3)) # Should print [4, 9]
print(squares(1, 5)) # Should print [1, 4, 9, 16, 25]
print(squares(0, 10)) # Should print [0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100]Examples: 函式奇數列表
def odd_numbers(x, y):
return [n for n in range(x, y) if n % 2 != 0]
# Call the odd_numbers() function with two parameters.
print(odd_numbers(5, 15))
# Should print [5, 7, 9, 11, 13]String 字串
字串是字元序列且是不可變的。以單引號或雙引號括起來的多個字元的集合,可以包含字母、數字和特殊字元。
Concatenate
secret_password = 'jhk7GSH8ds'
print('Password hint: the third letter of your password is ' + secret_password[2])# Escaping characters
introduction = 'Hello, I\'m John!'
print(introduction)
# Joining strings
user_age = 28
user_name = 'John'
greeting = user_name + ', you are ' + str(user_age) + '!'
print(greeting)s = 'String'
s += ' Concatenation'
print(s)# Using % NOTE: 舊版本適用
s1, s2, s3 = 'Python', 'String', 'Concatenation'
s = '%s %s %s' % (s1, s2, s3)
print(s)
# Using format()
s1, s2, s3 = 'Python', 'String', 'Concatenation'
s = '{} {} {}'.format(s1, s2, s3)
print(s)
# Using f-string
s1, s2, s3 = 'Python', 'String', 'Concatenation'
s = f'{s1} {s2} {s3}'
print(s)Parsing
split()
.split(): convert a string into a list or multiple variables.split(delimiter): convert a string into a list by specified delimeter, default is space.
"This is another example".split()
# Return ['This', 'is', 'another', 'example']test = "How-much-wood-would-a-woodchuck-chuck"
print(test.split("-")) # prints ['How', 'much', 'wood', 'would', 'a', 'woodchuck', 'chuck']removed_users = "wjaffrey jsoto abernard jhill awilliam"
print("before .split():", removed_users)
removed_users = removed_users.split()
print("after .split():", removed_users)with open("update_log.txt", "r") as file:
updates = file.read()
updates = updates.split()msg = "2024/12/11|Hello World|aaa@bb.com"
date, title, emails = msg.split("|")
print(date)join()
.join() : convert a list into a string
approved_users = ["elarson", "bmoreno", "tshah", "sgilmore", "eraab"]
print("before .join():", approved_users)
approved_users = ",".join(approved_users)
print("after .join():", approved_users)
with open("update_log.txt", "r") as file:
updates = file.read()
updates = updates.split()
updates = " ".join(updates)
with open("update_log.txt", "w") as file:
file.write(updates)# 以空白串接 List 的所有內容,輸出為字串
strings = ' '.join(my_list)
# 以空白行串接 List 的所有內容,輸出為字串
strings = '\n\n'.join(my_list)def list_elements(list_name, elements):
return "The " + list_name + " list includes: " + ", ".join(elements)
print(list_elements("Printers", ["Color Printer", "Black and White Printer", "3-D Printer"]))
# Should print "The Printers list includes: Color Printer, Black and White Printer, 3-D Printer"index()
.index() : get the index of specified character
string = "Hello, World"
print(string.index('w'))def replace_domain(email, old_domain, new_domain):
if "@" + old_domain in email:
index = email.index("@" + old_domain)
new_email = email[:index] + "@" + new_domain
return new_email
return emailreplace()
.replace(old,new) : Returns a new string where all occurrences of old have been replaced by new
test = "How much wood would a woodchuck chuck"
print(test.replace("wood", "plastic")) # prints "How much plastic would a plasticchuck chuck"Slicing
- Format: string [includ-index : exclude-index]
- Character Index: beginning with zero
- string[-2]: the last two characters
string1 = "Greetings, Earthlings"
print(string1[0]) # Prints “G”
print(string1[4:8]) # Prints “ting”
print(string1[11:]) # Prints “Earthlings”
print(string1[:5]) # Prints “Greet”
print(string1[-10:]) # Prints “Earthlings” againphonenum = "2025551212"
# The first 3 digits are the area code:
area_code = "(" + phonenum[:3] + ")"
# area_code is (202)
# the numbers 4–6 from the list:
exchange = phonenum[3:6]
# exchange is 555
# the last four numbers:
line = phonenum[-4:]
# line is 1212Formating
name = "Manny"
number = len(name) * 3
print("Hello {}, your lucky number is {}".format(name, number))name = "Manny"
print("Your lucky number is {number}, {name}.".format(name=name, number=len(name)*3))price = 7.5
with_tax = price * 1.09
print(price, with_tax)
print("Base price: ${:.2f}. With Tax: ${:.2f}".format(price, with_tax)){:>3}向右對齊,3 個字元{:>6.2f}向右對齊,6 個字元,小數點 2 位{:10,.2f}10 字元,千位符號,小數點 2 位{:.2s}2 個字元字串
def to_celsius(x):
return (x-32)*5/9
for x in range(0,101,10):
print("{:>3} F | {:>6.2f} C".format(x, to_celsius(x))) 0 F | -17.78 C
10 F | -12.22 C
20 F | -6.67 C
30 F | -1.11 C
40 F | 4.44 C
50 F | 10.00 C
60 F | 15.56 C
70 F | 21.11 C
80 F | 26.67 C
90 F | 32.22 C
100 F | 37.78 Cf-strings
name = "Micah"
print(f'Hello {name}')item = "Purple Cup"
amount = 5
price = amount * 3.25
print(f'Item: {item} - Amount: {amount} - Price: {price:.2f}')More methods
- 可以一次使用多個不同的 methods
.capitalize(): 字首大寫
strip()
.strip() , .lstrip() , .rstrip()
" yes ".strip() # Return 'yes'
" yes ".lstrip() # Return 'yes '
" yes ".rstrip() # Return ' yes'
# Multiple methods
' yes '.upper().strip() # Reyurn 'YES'count()
.count()
"The number of times e occurs in this string is 4".count("e")
# Return 4endswith()
.endswith()
"Forest".endswith("rest")
# Return Trueisnumeric(), isalpha()
.isnumeric() , .isalpha()
"Forest".isnumeric() # Return False
"12345".isnumeric() # Return True
"xyzzy".isalpha() # Return TrueInstallation
Alternatives
變更 python 指令的預設路徑
alternatives --set python /usr/bin/python3
# Or
alternatives --config python
# Check the list
alternatives --listPoetry
Poetry 應該要安裝在 Python 虛擬環境,與主要系統間做隔離。
curl -sSL https://install.python-poetry.org | python3 -Unit Test
單元測試
- 目的:以隔離主程式的方式,對自訂的函式(function)與方法(method),提供指定的輸入參數與期待的輸出結果,以驗證相關程式碼是否有瑕疵或錯誤。
- 方法:撰寫額外的測試用程式碼,並使用任一個單元測試模組,例如 unittest, Pytest 或類似用途的其他模組。
- 自動化:整合 CI/CD 做到全自動化程式碼單元測試
Pytest
test_example.py
import pytest
def test_addition():
assert 1 + 1 == 3
class TestMathOperations:
def test_addition(self):
assert 1 + 1 == 2Functio-based: pytest test_example.py::test_addition
Class-based:
pytest test_example.py::TestMathOperationspytest test_example.py::TestMathOperations::test_addition
pytest Raises
程式碼異常/錯誤訊息的測試
Checking for ValueError (不正確數值)
import pytest
import math
def calculate_square_root(value):
if value < 0:
raise ValueError("Cannot calculate the square root of a negative number")
return math.sqrt(value)
def test_calculate_square_root():
with pytest.raises(ValueError):
calculate_square_root(-1)Checking for ZeroDivisionError (零除誤差)
import pytest
def divide_numbers(numerator, denominator):
return numerator / denominator
def test_divide_numbers():
with pytest.raises(ZeroDivisionError):
divide_numbers(10, 0)Checking for TypeError (資料類型錯誤)
import pytest
def add_numbers(a, b):
return a + b
def test_add_numbers():
with pytest.raises(TypeError):
add_numbers("10", 5)Checking for KeyError (字典的鍵值錯誤)
import pytest
def get_value(dictionary, key):
return dictionary[key]
def test_get_value():
with pytest.raises(KeyError):
get_value({"name": "Alice"}, "age")pytest Markers
無條件忽略
@pytest.mark.skip(reason="Feature not yet implemented")
def test_feature():
pass有條件忽略
import sys
@pytest.mark.skipif(sys.platform == "win32", reason="does not run on windows")
class TestClass:
def test_function(self):
"This test will not run under 'win32' platform"pytest Fixtures
可重複使用的預設資料
import pytest
@pytest.fixture
def user_data():
return [
{"name": "Alice", "age": 30},
{"name": "Bob", "age": 25},
{"name": "Charlie", "age": 35}
]
# Test function to check for a specific user by name and age
def test_user_exists(user_data):
user = {"name": "Alice", "age": 30}
# Check if the target user is in the list
assert user in user_data
# Test average age of users
def test_average_age(user_data):
ages = [user["age"] for user in user_data]
avg_age = sum(ages) / len(ages)
assert avg_age == 30pytest Parametrization
可同時使用不同資料集執行測試函式。
import pytest
# Function to calculate the square of a number
def square_numbers(num):
return num * num
#Parametrize decorator to test the square function with different inputs
@pytest.mark.parametrize("input_value, expected_output", [
(2, 4),
(-3, 9),
(0, 0)
])
def test_square(input_value, expected_output):
assert square_numbers(input_value) == expected_outputunittest
Methods
.assertEqual(a, b): checks that a == b.assertNotEqual(a, b): checks that a != b.assertTrue('FOO'.isupper()): checks that bool(x) is True.assertFalse('Foo'.isupper()): checks that bool(x) is False
Example 1: rearrange.py
#!/usr/bin/env python3
import re
def rearrange_name(name):
result = re.search(r"^([\w .]*), ([\w .]*)$", name)
if result is None:
return name
return "{} {}".format(result[2], result[1])rearrange_test.py :
#!/usr/bin/env python3
import unittest
from rearrange import rearrange_name
class TestRearrange(unittest.TestCase):
def test_basic(self): # Basic test case
testcase = "Lovelace, Ada"
expected = "Ada Lovelace"
self.assertEqual(rearrange_name(testcase), expected)
def test_empty(self): # Edge case, such as zero, blank, negative numbers, or extremely large numbers
testcase = ""
expected = ""
self.assertEqual(rearrange_name(testcase), expected)
def test_double_name(self): # Additional test case
testcase = "Hopper, Grace M."
expected = "Grace M. Hopper"
self.assertEqual(rearrange_name(testcase), expected)
def test_one_name(self): # Additional test case
testcase = "Voltaire"
expected = "Voltaire"
self.assertEqual(rearrange_name(testcase), expected)
# Run the tests
unittest.main()Tip: 在 Jupyter 環境執行
unittest.main()時可能會出現錯誤,修正方法是改成unittest.main(argv = ['first-arg-is-ignored'], exit = False))。
The output of the result:
.
----------------------------------------------------------------------
Ran 4 test in 0.000s
OKExample 2: cakefactory.py
#!/usr/bin/env python3
from typing import List
class CakeFactory:
def __init__(self, cake_type: str, size: str):
self.cake_type = cake_type
self.size = size
self.toppings = []
# Price based on cake type and size
self.price = 10 if self.cake_type == "chocolate" else 8
self.price += 2 if self.size == "medium" else 4 if self.size == "large" else 0
def add_topping(self, topping: str):
self.toppings.append(topping)
# Adding 1 to the price for each topping
self.price += 1
def check_ingredients(self) -> List[str]:
ingredients = ['flour', 'sugar', 'eggs']
ingredients.append('cocoa') if self.cake_type == "chocolate" else ingredients.append('vanilla extract')
ingredients += self.toppings
return ingredients
def check_price(self) -> float:
return self.price
# Example of creating a cake and adding toppings
cake = CakeFactory("chocolate", "medium")
cake.add_topping("sprinkles")
cake.add_topping("cherries")
cake_ingredients = cake.check_ingredients()
cake_price = cake.check_price()
cake_ingredients, cake_pricecakefactory_test.py
#!/usr/bin/env python3
import unittest
from cakefactory import CakeFactory
class TestCakeFactory(unittest.TestCase):
def test_create_cake(self):
cake = CakeFactory("vanilla", "small")
self.assertEqual(cake.cake_type, "vanilla")
self.assertEqual(cake.size, "small")
self.assertEqual(cake.price, 8) # Vanilla cake, small size
def test_add_topping(self):
cake = CakeFactory("chocolate", "large")
cake.add_topping("sprinkles")
self.assertIn("sprinkles", cake.toppings)
def test_check_ingredients(self):
cake = CakeFactory("chocolate", "medium")
cake.add_topping("cherries")
ingredients = cake.check_ingredients()
self.assertIn("cocoa", ingredients)
self.assertIn("cherries", ingredients)
self.assertNotIn("vanilla extract", ingredients)
def test_check_price(self):
cake = CakeFactory("vanilla", "large")
cake.add_topping("sprinkles")
cake.add_topping("cherries")
price = cake.check_price()
self.assertEqual(price, 13) # Vanilla cake, large size + 2 toppings
# Running the unittests
unittest.TextTestRunner().run(unittest.TestLoader().loadTestsFromTestCase(TestCakeFactory))This results in the output:
..F.
======================================================================
FAIL: test_check_price (__main__.TestCakeFactory)
----------------------------------------------------------------------
Traceback (most recent call last):
File "<ipython-input-9-32dbf74b3655>", line 33, in test_check_price
self.assertEqual(price, 13) # Vanilla cake, large size + 2 toppings
AssertionError: 14 != 13
----------------------------------------------------------------------
Ran 4 tests in 0.007s
FAILED (failures=1)
<unittest.runner.TextTestResult run=4 errors=0 failures=1>The program calls the TextTestRunner() method, which returns a runner (TextTestResult). It says one failure occurred: the statement self.assertEqual(price, 13) was incorrect, as it should have been 14. How can we correct that part of the test? Update that part of the code to the following:
import unittest
# Fixing the test_check_price method
class TestCakeFactory(unittest.TestCase):
# ... Other tests remain the same
def test_check_price(self):
cake = CakeFactory("vanilla", "large")
cake.add_topping("sprinkles")
cake.add_topping("cherries")
price = cake.check_price()
self.assertEqual(price, 14) # Vanilla cake, large size + 2 toppings
# Re-running the unittests
unittest.TextTestRunner().run(unittest.TestLoader().loadTestsFromTestCase(TestCakeFactory))And now the program works as expected, as the results provide no failures and are:
.
----------------------------------------------------------------------
Ran 4 test in 0.002s
OKRegular Expression
Basic Regex
Character types
\wmatches with any alphanumeric character, including underline-
.matches to all characters, including symbols (Wildcard) -
\dmatches to all single digits, 同[0-9] \D非數字的字元,同[^0-9]-
\smatches to all single space, tab and new line -
\.matches to the dot(period) character [a-z]小寫英文字母 a-z[A-Z]大寫英文字母 A-Z[^a-z]非小寫英文字母 a-z[0-9]數字 0-9[^0-9]反向列舉,任意非數字|左邊字元或右邊字元p?each字元 each 前方包含 0 個或 1 個 p 字元,each 或 peach
import re
re.findall("\w", "h32rb17")
import re
re.findall("\d", "h32rb17")邊界符號
^行首$行尾\b必須是單詞 (文字、數字、底線) 的開頭或結尾\B不能是單詞 (文字、數字、底線) 的開頭或結尾
Quantify occurrences
次數符號,限定符號
+: 重複 1 次以上,同{1,}*: 重複 0 次以上,同{0,}?: 重複 0 或 1 次,範例p?each字元 each 前方包含 0 個或 1 個 p 字元,例如 each 或 peach{n}: 重複 n 次{n,}: 重複 n 次以上{0,n}: 重複 0 - n 次{n,m}: 重複 n - m 次\d{2}2 位數的數字\d{1,3}數字 1 - 3 位數\d+不限位數的任何數字
Functions
.findall()
.findall(<regex>, <string>)
- 搜尋符合的所有字元
- 輸出格式 List
- 沒有符合時回傳
None
import re
re.findall("\d+", "h32rb17")
import re
re.findall("\d*", "h32rb17")
import re
re.findall("\d{2}", "h32rb17 k825t0m c2994eh")
import re
re.findall("\d{1,3}", "h32rb17 k825t0m c2994eh")import re
pattern = "\w+:\s\d+"
employee_logins_string = "1001 bmoreno: 12 Marketing 1002 tshah: 7 Human Resources 1003 sgilmore: 5 Finance"
print(re.findall(pattern, employee_logins_string))['bmoreno: 12', 'tshah: 7', 'sgilmore: 5'].search()
.search(<regex>, <string>, re.IGNORECASE)
- r"regex" :
r表示 raw string,Python 直譯器不會解譯該字串,而是直接傳給函式 - 只搜尋符合的第一個字元
- 輸出格式 Match Class
- 沒有符合時回傳
None
import re
log = "July 31 07:51:48 mycomputer bad_process[12345]: ERROR Performing package upgrade"
regex = r"\[(\d+)\]"
result = re.search(regex, log)
print(result) # Output: <_sre.SRE_Match object; span=(39, 46), match='[12345]'>
print(result[1]) # Output: 12345import re
print(re.search(r"[Pp]ython", "Python"))
# Output: <_sre.SRE_Match object; span=(0, 6), match='Python'>import re
print(re.search(r"Py.*n", "Pygmalion"))
print(re.search(r"Py.*n", "Python Programming"))
print(re.search(r"Py[a-z]*n", "Python Programming"))
print(re.search(r"Py[a-z]*n", "Pyn"))
# Output:
# <_sre.SRE_Match object; span=(0, 9), match='Pygmalion'>
# <_sre.SRE_Match object; span=(0, 17), match='Python Programmin'>
# <_sre.SRE_Match object; span=(0, 6), match='Python'>
# <_sre.SRE_Match object; span=(0, 3), match='Pyn'>import re
print(re.search(r"o+l+", "goldfish"))
print(re.search(r"o+l+", "woolly"))
print(re.search(r"o+l+", "boil"))
# Output:
# <_sre.SRE_Match object; span=(1, 3), match='ol'>
# <_sre.SRE_Match object; span=(1, 5), match='ooll'>
# None.split()
- 用途:用 Regex 分割長字串
.split(<regex>, <string>): 輸出 List 資料格式r"[.?!]"多個不同單一字元做區隔符號可用中括號,且特殊符號不需要使用跳脫字元
import re
re.split(r"[.?!]", "One sentence. Another one? And the last one!")
# Output: ['One sentence', ' Another one', ' And the last one', '']r"the|a": 多個不同單字做區隔符號可用導管
re.split(r"the|a", "One sentence. Another one? And the last one!")
# Output: ['One sentence. Ano', 'r one? And ', ' l', 'st one!']r"([.?!])"區隔符號用中括號,不需要使用跳脫符號,外圍加上括號時,輸出會包含區隔符號
import re
re.split(r"([.?!])", "One sentence. Another one? And the last one!")
# Output: ['One sentence', '.', ' Another one', '?', ' And the last one', '!', ''].sub()
- 用途:搜尋並取代字串
.sub(<regex>, <new-string>, <strings>): 符合 <regex> 的字串會被 <new-string>取代
import re
re.sub(r"[\w.%+-]+@[\w.-]+", "[REDACTED]", "Received an email for go_nuts95@my.example.com")
# Output: Received an email for [REDACTED]re.sub(r"([A-Z])\.\s+(\w+)", r"Ms. \2", "A. Weber and B. Bellmas have joined the team.")
# Output: Ms. Weber and Ms. Bellmas have joined the team- 搜尋與取代都能使用 Regex
- 搜尋 regex :
r"^([\w .-]*), ([\w .-]*)$",(群組1), (群組2) - 取代 regex:
r"\2 \1",\2 群組2,\1 群組1
import re
re.sub(r"^([\w .-]*), ([\w .-]*)$", r"\2 \1", "Lovelace, Ada")
# Output: Ada LovelaceAdvanced Regex
多個選項
Alteration: RegEx that matches any one of the alternatives separated by the pipe symbol
r"location.*(London|Berlin|Madrid)": location is London, location is Berlin, or location is Madrid.
字元範圍
r"[0-9$-,.]": This will match any of the digits zero through nine, or the dollar sign, hyphen, comma, or period
常用驗證
r"\d{3}-\d{3}-\d{4}"This line of code matches U.S. phone numbers in the format 111-222-3333.r"^-?\d*(\.\d+)?$"任何正數或負數,不論是否有小數位數r"^(.+)\/([^\/]+)\/"任何檔案路徑
IP addr.
# Assign `log_file` to a string containing username, date, login time, and IP address for a series of login attempts
log_file = "eraab 2022-05-10 6:03:41 192.168.152.148 \niuduike 2022-05-09 6:46:40 192.168.22.115 \nsmartell 2022-05-09 19:30:32 192.168.190.178 \narutley 2022-05-12 17:00:59 1923.1689.3.24 \nrjensen 2022-05-11 0:59:26 192.168.213.128 \naestrada 2022-05-09 19:28:12 1924.1680.27.57 \nasundara 2022-05-11 18:38:07 192.168.96.200 \ndkot 2022-05-12 10:52:00 1921.168.1283.75 \nabernard 2022-05-12 23:38:46 19245.168.2345.49 \ncjackson 2022-05-12 19:36:42 192.168.247.153 \njclark 2022-05-10 10:48:02 192.168.174.117 \nalevitsk 2022-05-08 12:09:10 192.16874.1390.176 \njrafael 2022-05-10 22:40:01 192.168.148.115 \nyappiah 2022-05-12 10:37:22 192.168.103.10654 \ndaquino 2022-05-08 7:02:35 192.168.168.144"
# Assign `pattern` to a regular expression that matches with all valid IP addresses and only those
pattern = "\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}"
# Use `re.findall()` on `pattern` and `log_file` and assign `valid_ip_addresses` to the output
valid_ip_addresses = re.findall(pattern, log_file)
# Assign `flagged_addresses` to a list of IP addresses that have been previously flagged for unusual activity
flagged_addresses = ["192.168.190.178", "192.168.96.200", "192.168.174.117", "192.168.168.144"]
# Iterative statement begins here
# Loop through `valid_ip_addresses` with `address` as the loop variable
for address in valid_ip_addresses:
# Conditional begins here
# If `address` belongs to `flagged_addresses`, display "The IP address ______ has been flagged for further analysis."
if address in flagged_addresses:
print("The IP address", address, "has been flagged for further analysis.")
# Otherwise, display "The IP address ______ does not require further analysis."
else:
print("The IP address", address, "does not require further analysis.")檢查字串函式
回傳結果 True 或 False
import re
def check_aei (text):
result = re.search(r".*a.+e.+i.*", text)
return result != None
print(check_aei("academia")) # True
print(check_aei("aerial")) # False
print(check_aei("paramedic")) # True函式: 檢查字串是否有包含任何標點符號
import re
def check_punctuation (text):
result = re.search(r"[^a-zA-Z ]", text)
return result != None
print(check_punctuation("This is a sentence that ends with a period.")) # True
print(check_punctuation("This is a sentence fragment without a period")) # False
print(check_punctuation("Aren't regular expressions awesome?")) # Trueimport re
def compare_strings(string1, string2):
# Convert both strings to lowercase
# and remove leading and trailing blanks
string1 = string1.lower().strip()
string2 = string2.lower().strip()
# Removed punctuation
punctuation = r"[.?!,;:\-']"
string1 = re.sub(punctuation, r"", string1)
string2 = re.sub(punctuation, r"", string2)
# DEBUG CODE GOES HERE
#print(string1 == string2)
return string1 == string2
print(compare_strings("Have a Great Day!", "Have a great day?")) # True
print(compare_strings("It's raining again.", "its raining, again")) # True
print(compare_strings("Learn to count: 1, 2, 3.", "Learn to count: one, two, three.")) # False
print(compare_strings("They found some body.", "They found somebody.")) # False函式:check web address
import re
def check_web_address(text):
pattern = r"[\w-]*\.[a-zA-Z]*$"
result = re.search(pattern, text)
return result != None
print(check_web_address("gmail.com")) # True
print(check_web_address("www@google")) # False
print(check_web_address("www.Coursera.org")) # True
print(check_web_address("web-address.com/homepage")) # False
print(check_web_address("My_Favorite-Blog.US")) # True函式:check time
import re
def check_time(text):
pattern = r"[1-9|10|11|12]:[0-5][0-9] *[AaPp][mM]$"
result = re.search(pattern, text)
return result != None
print(check_time("12:45pm")) # True
print(check_time("9:59 AM")) # True
print(check_time("6:60am")) # False
print(check_time("five o'clock")) # False
print(check_time("6:02 am")) # True
print(check_time("6:02km")) # False函式:括號內的字首需大寫字母或數字
import re
def contains_acronym(text):
pattern = r"\([0-9A-Z][a-zA-z]*\)"
result = re.search(pattern, text)
return result != None
print(contains_acronym("Instant messaging (IM) is a set of communication technologies used for text-based communication")) # True
print(contains_acronym("American Standard Code for Information Interchange (ASCII) is a character encoding standard for electronic communication")) # True
print(contains_acronym("Please do NOT enter without permission!")) # False
print(contains_acronym("PostScript is a fourth-generation programming language (4GL)")) # True
print(contains_acronym("Have fun using a self-contained underwater breathing apparatus (Scuba)!")) # True函式:Log 提取 PID 與 Message
import re
def extract_pid(log_line):
regex = r"\[(\d+)\]: ([A-Z]*) "
result = re.search(regex, log_line)
if result is None:
return None
return "{} ({})".format(result[1], result[2])
print(extract_pid("July 31 07:51:48 mycomputer bad_process[12345]: ERROR Performing package upgrade")) # 12345 (ERROR)
print(extract_pid("99 elephants in a [cage]")) # None
print(extract_pid("A string that also has numbers [34567] but no uppercase message")) # None
print(extract_pid("July 31 08:08:08 mycomputer new_process[67890]: RUNNING Performing backup")) # 67890 (RUNNING)函式:轉換電話號碼
import re
def transform_record(record):
new_record = re.sub(r"(.*,)(\d{3}-[\d-]+)(,.*)", r"\1+1-\2\3", record)
return new_record
print(transform_record("Sabrina Green,802-867-5309,System Administrator"))
# Sabrina Green,+1-802-867-5309,System Administrator
print(transform_record("Eli Jones,684-3481127,IT specialist"))
# Eli Jones,+1-684-3481127,IT specialist
print(transform_record("Melody Daniels,846-687-7436,Programmer"))
# Melody Daniels,+1-846-687-7436,Programmer
print(transform_record("Charlie Rivera,698-746-3357,Web Developer"))
# Charlie Rivera,+1-698-746-3357,Web Developerimport re
def convert_phone_number(phone):
result = re.sub(r"([\w ]+)(\d{3})-(\d{3}-\d{4}.*)$", r"\1(\2) \3", phone)
return result
print(convert_phone_number("My number is 212-345-9999.")) # My number is (212) 345-9999.
print(convert_phone_number("Please call 888-555-1234")) # Please call (888) 555-1234
print(convert_phone_number("123-123-12345")) # 123-123-12345
print(convert_phone_number("Phone number of Buckingham Palace is +44 303 123 7300")) # Phone number of Buckingham Palace is +44 303 123 7300# phone.csv:
#123-456-7890
#(123) 456-7890
#1234567890
#
import re
with open("data/phones.csv", "r") as phones:
for phone in phones:
new_phone = re.sub(r"^\D*(\d{3})\D*(\d{3})\D*(\d{4})$", r"(\1) \2-\3", phone)
print(new_phone)
# Output
#(123) 456-7890
#(123) 456-7890
#(123) 456-7890函式:包含 a, e, i, o, u 任一字元 3 個以上的單字
import re
def multi_vowel_words(text):
pattern = r"\w+[aeiou]{3,}\w+"
result = re.findall(pattern, text)
return result
print(multi_vowel_words("Life is beautiful"))
# ['beautiful']
print(multi_vowel_words("Obviously, the queen is courageous and gracious."))
# ['Obviously', 'queen', 'courageous', 'gracious']
print(multi_vowel_words("The rambunctious children had to sit quietly and await their delicious dinner."))
# ['rambunctious', 'quietly', 'delicious']
print(multi_vowel_words("The order of a data queue is First In First Out (FIFO)"))
# ['queue']
print(multi_vowel_words("Hello world!"))
# []\b 的用法
\b 必須是單詞 (文字、數字、底線) 的開頭或結尾
import re
print(re.findall(r"[a-zA-Z]{5}", "a scary ghost appeared"))
# Output: ['scary', 'ghost', 'appea']
import re
re.findall(r"\b[a-zA-Z]{5}\b", "A scary ghost appeared")
# Output: ['scary', 'ghost']- 結尾如果不加
\b無法正確搜尋所有的 eid
def find_eid(report):
pattern = r"[A-Z]-[\d]{7,8}\b" #enter the regex pattern here
result = re.findall(pattern, report) #enter the re method here
return result
print(find_eid("Employees B-1234567 and C-12345678 worked with products X-123456 and Z-123456789"))
# Should return ['B-1234567', 'C-12345678']
print(find_eid("Employees B-1234567 and C-12345678, not employees b-1234567 and c-12345678"))
#Should return ['B-1234567', 'C-12345678'] Capturing Groups
- 用途:提取字串中符合 Regex 規則的不同文字區段
- 特定字元區段的 Regex 可用括號定義成群組
- 多個括號時,依序為群組1,群組2
.groups()method : 輸出 tuple 格式資料,例如 (group1, group2, group3)- result[0]: 完整字串 ,result[1]: 群組1, result[2]: 群組2
import re
result = re.search(r"^(\w*), (\w*)$", "Lovelace, Ada")
print(result)
print(result.groups())
print(result[0])
print(result[1])
print(result[2])
"{} {}".format(result[2], result[1])
# Output
# <_sre.SRE_Match object; span=(0, 13), match='Lovelace, Ada'>
# ('Lovelace', 'Ada')
# Lovelace, Ada
# Lovelace
# Ada
# Ada LovelaceResources
Tuple 元組
元組類似於清單,是任何類型的元素序列,但它們是不可變的,它們以括號表示。
- 符號用括號
- 內容不可變更
- 處理大量資料比 List 節省記憶體
- 讀取速度比串列(List)快
a = (1, 2, 3)
b = ('red', 'green', 'blue')範例:利用 index 取值
t = (1, 2, 3 ,4 ,5)
print(t[0]) # 1
print(t[1]) # 2
print(t[2]) # 3範例:如果函式一次回傳多個值時,這資料類型就是 Tuple。
def convert_seconds(seconds):
hours = seconds // 3600
minutes = (seconds - hours * 3600) // 60
remaining_seconds = seconds - hours * 3600 - minutes * 60
return hours, minutes, remaining_seconds
result = convert_seconds(5000)
type(result)
# Output: <class 'tuple'>範例:Tuple 可以將多個不同值對應不同變數名
def convert_seconds(seconds):
hours = seconds // 3600
minutes = (seconds - hours * 3600) // 60
remaining_seconds = seconds - hours * 3600 - minutes * 60
return hours, minutes, remaining_seconds
result = convert_seconds(5000)
hours, minutes, seconds = result
print(hours, minutes, seconds)
# Output: 1 23 20您可能會想,既然元組和清單類似,為什麼會有元組呢?當我們需要確保某個元素在某個位置且不會改變時,Tuples 就會很有用。由於 List(清單) 是可變的,因此元素的順序可以被改變。由於 Tuple(元組) 中元素的順序無法改變,元素在 Tuple(元組)中的位置就有了意義。一個很好的例子就是當一個函式回傳多個值時。在這種情況下,返回的是一個 Tuple(元組) 中的元素。返回值的順序很重要,而一個 Tuple(元組)可以確保順序不會改變。將 Tuple 的元素儲存於獨立的變數中,稱為 unpacking。這允許您從函數中取得多個回傳值,並將每個值儲存在自己的變數中。
範例:迭代於 List 與 Tuple
def full_emails(people):
result = []
for email, name in people:
result.append("{} <{}>".format(name, email))
return result
print(full_emails([("alex@example.com", "Alex Diego"), ("shay@example.com", "Shay Brandt")]))
# Output: ['Alex Diego <alex@example.com>', 'Shay Brandt <shay@example.com>']Dictionary 字典
不像序列是由一個範圍內的數字當作索引,dictionary 是由鍵 (key) 來當索引,鍵可以是任何不可變的類型;字串和數字都可以當作鍵。Tuple 也可以當作鍵,如果他們只含有字串、數字或 tuple;若一個 tuple 直接或間接地含有任何可變的物件,它就不能當作鍵。你無法使用 list 當作鍵,因為 list 可以經由索引指派 (index assignment)、切片指派 (slice assignment) 或是像 append() 和 extend() 等 method 被修改。
思考 dictionary 最好的方式是把它想成是一組鍵值對 (key: value pair) 的 set,其中鍵在同一個 dictionary 裡必須是獨一無二的。使用一對大括號可建立一個空的 dictionary:{}。將一串由逗號分隔的鍵值對置於大括號則可初始化字典的鍵值對。這同樣也是字典輸出時的格式。
Key type:
- Numbers
- Booleans
- Strings
- Tuples
資料集合
dictionary1 = {"keyA":valuea, "keyB":value2, "keyC":value3, "KeyD":value4}
dictionary2 = {"keyA":["value1", "value2"], "keyB":["value3", "value4"]}搜尋鍵-值
NOTE: Dictionary 如果鍵有重複,新的值會覆蓋舊的。
file_counts = {"jpg":10, "txt":14, "csv":2, "py":23}
file_counts["txt"]
# Output: 14
# 鍵有重複時
file_counts = {"jpg":10, "txt":14, "csv":2, "py":23, "txt":99}
file_counts["txt"]
# Output: 99檢查索引
file_counts = {"jpg":10, "txt":14, "csv":2, "py":23}
"jpg" in file_counts
# Output: True新增元素: dictionary[key] = value
file_counts = {"jpg":10, "txt":14, "csv":2, "py":23}
file_counts["cfg"] = 8
print(file_counts)
# Output {'jpg': 10, 'txt': 14, 'csv': 2, 'py': 23, 'cfg': 8}變更指定索引的元素: dictionary[key] = value
file_counts = {"jpg":10, "txt":14, "csv":2, "py":23}
file_counts["csv"] = 17
print(file_counts)
# Output {'jpg': 10, 'txt': 14, 'csv': 17, 'py': 23}刪除指定索引的元素
file_counts = {"jpg":10, "txt":14, "csv":2, "py":23, 'cfg':8}
del file_counts["cfg"]
print(file_counts)
# Output {'jpg': 10, 'txt': 14, 'csv': 2, 'py': 23}Operations
-
len(dictionary) - Returns the number of items in a dictionary.
-
for key, in dictionary - Iterates over each key in a dictionary.
-
for key, value in dictionary.items() - Iterates over each key,value pair in a dictionary.
-
if key in dictionary - Checks whether a key is in a dictionary.
-
dictionary[key] - Accesses a value using the associated key from a dictionary.
-
dictionary[key] = value - Sets a value associated with a key.
-
del dictionary[key] - Removes a value using the associated key from a dictionary.
字典使用 for loop 迭代時,預設使用 key 存取
file_counts = {"jpg":10, "txt":14, "csv":2, "py":23}
for extension in file_counts:
print(extension)
# Output
jpg
txt
csv
pyMethods
-
dictionary.get(key, default) - Returns the value corresponding to a key, or the default value if the specified key is not present.
-
dictionary.keys() - Returns a sequence containing the keys in a dictionary.
-
dictionary.values() - Returns a sequence containing the values in a dictionary.
-
dictionary[key].append(value) - Appends a new value for an existing key.
-
dictionary.update(other_dictionary) - Updates a dictionary with the items from another dictionary. Existing entries are updated; new entries are added.
-
dictionary.clear() - Deletes all items from a dictionary.
-
dictionary.copy() - Makes a copy of a dictionary.
.item()
.items() 迭代 dictionary 資料時,可存取 key 與 value。
file_counts = {"jpg":10, "txt":14, "csv":2, "py":23}
for ext, amount in file_counts.items():
print("There are {} files with the .{} extension".format(amount, ext))
# Output
There are 10 files with the .jpg extension
There are 14 files with the .txt extension
There are 2 files with the .csv extension
There are 23 files with the .py extension# This function returns the total time, with minutes represented as
# decimals (example: 1 hour 30 minutes = 1.5), for all end user time
# spent accessing a server in a given day.
def sum_server_use_time(Server):
# Initialize the variable as a float data type, which will be used
# to hold the sum of the total hours and minutes of server usage by
# end users in a day.
total_use_time = 0.0
# Iterate through the "Server" dictionary’s key and value items
# using a for loop.
for key,value in Server.items():
# For each end user key, add the associated time value to the
# total sum of all end user use time.
total_use_time += Server[key]
# Round the return value and limit to 2 decimal places.
return round(total_use_time, 2)
FileServer = {"EndUser1": 2.25, "EndUser2": 4.5, "EndUser3": 1, "EndUser4": 3.75, "EndUser5": 0.6, "EndUser6": 8}
print(sum_server_use_time(FileServer)) # Should print 20.1# This function receives a dictionary, which contains common employee
# last names as keys, and a list of employee first names as values.
# The function generates a new list that contains each employees’ full
# name (First_name Last_Name). For example, the key "Garcia" with the
# values ["Maria", "Hugo", "Lucia"] should be converted to a list
# that contains ["Maria Garcia", "Hugo Garcia", "Lucia Garcia"].
def list_full_names(employee_dictionary):
# Initialize the "full_names" variable as a list data type using
# empty [] square brackets.
full_names = []
# The outer for loop iterates through each "last_name" key and
# associated "first_name" values, in the "employee_dictionary" items.
for last_name, first_names in employee_dictionary.items():
# The inner for loop iterates over each "first_name" value in
# the list of "first_names" for one "last_name" key at a time.
for first_name in first_names:
# Append the new "full_names" list with the "first_name" value
# concatenated with a space " ", and the key "last_name".
full_names.append(first_name+" "+last_name)
# Return the new "full_names" list once the outer for loop has
# completed all iterations.
return(full_names)
print(list_full_names({"Ali": ["Muhammad", "Amir", "Malik"], "Devi": ["Ram", "Amaira"], "Chen": ["Feng", "Li"]}))
# Should print ['Muhammad Ali', 'Amir Ali', 'Malik Ali', 'Ram Devi', 'Amaira Devi', 'Feng Chen', 'Li Chen'].keys() .values()
.keys() , .values()
file_counts = {"jpg":10, "txt":14, "csv":2, "py":23}
file_counts.keys() # Return dict_keys(['jpg', 'txt', 'csv', 'py'])
file_counts.values() # Return dict_values([10, 14, 2, 23])file_counts = {"jpg":10, "txt":14, "csv":2, "py":23}
for value in file_counts.values():
print(value)
# Output
10
14
2
23-
Use the dictionary[key] = value operation to associate a value with a key in a dictionary.
-
Iterate over keys with multiple values from a dictionary, using nested for loops and an if-statement, and the dictionary.items() method.
-
Use the dictionary[key].append(value) method to add the key, a string, and the key for each item in the dictionary.
def groups_per_user(group_dictionary):
user_groups = {}
# Go through group_dictionary
for group, users in group_dictionary.items():
# Now go through the users in the group
for user in users:
# Now add the group to the the list of
if user in user_groups:
user_groups[user].append(group)
else:
user_groups[user] = [group]
# groups for this user, creating the entry
# in the dictionary if necessary
return(user_groups)
print(groups_per_user({"local": ["admin", "userA"],
"public": ["admin", "userB"],
"administrator": ["admin"] }))
# Should print {'admin': ['local', 'public', 'administrator'], 'userA': ['local'], 'userB': ['public']}.update()
- dictionary.update(other_dictionary) - Updates a dictionary with the items from another dictionary. Existing entries are updated; new entries are added.
wardrobe = {'shirt': ['red', 'blue', 'white'], 'jeans': ['blue', 'black']}
new_items = {'jeans': ['white'], 'scarf': ['yellow'], 'socks': ['black', 'brown']}
wardrobe.update(new_items)
# wardrobe: {'shirt': ['red', 'blue', 'white'], 'jeans': ['white'], 'scarf': ['yellow'], 'socks': ['black', 'brown']}.copy()
# The scores() function accepts a dictionary "game_scores" as a parameter.
def reset_scores(game_scores):
# The .copy() dictionary method is used to create a new copy of the "game_scores".
new_game_scores = game_scores.copy()
# The for loop iterates over new_game_scores items, with the player as the key
# and the score as the value.
for player, score in new_game_scores.items():
# The dictionary operation to assign a new value to a key is used
# to reset the grade values to 0.
new_game_scores[player] = 0
return new_game_scores
# The dictionary is defined.
game1_scores = {"Arshi": 3, "Catalina": 7, "Diego": 6}
# Call the "reset_scores" function with the "game1_scores" dictionary.
print(reset_scores(game1_scores))
# Should print {'Arshi': 0, 'Catalina': 0, 'Diego': 0}Functions
sorted()
sorted(dict.items()): 預設以 Dictionary 的 key 做排序sorted(, key=operator.itemgetter(0):.itemgettor(0)指 Dictionary 的 key,以此排序sorted(, key=operator.itemgetter(1):.itemgettor(1)指 Dictionary 的 value,以此排序sorted(, reverse=True): 反向排序
fruit = {"oranges": 3, "apples": 5, "bananas": 7, "pears": 2}
sorted(fruit.items())
# [('apples', 5), ('bananas', 7), ('oranges', 3), ('pears', 2)]
import operator
sorted(fruit.items(), key=operator.itemgetter(0))
# [('apples', 5), ('bananas', 7), ('oranges', 3), ('pears', 2)]
sorted(fruit.items(), key=operator.itemgetter(1))
# [('pears', 2), ('oranges', 3), ('apples', 5), ('bananas', 7)]
sorted(fruit.items(), key = operator.itemgetter(1), reverse=True)
# [('bananas', 7), ('apples', 5), ('oranges', 3), ('pears', 2)]Google Python Course
Google Python 訓練課程
Course 1
Naming rules and conventions
命名規則與慣例
When assigning names to objects, programmers adhere to a set of rules and conventions which help to standardize code and make it more accessible to everyone. Here are some naming rules and conventions that you should know:
-
Names cannot contain spaces.
-
Names may be a mixture of upper and lower case characters.
-
Names can’t start with a number but may contain numbers after the first character.
-
Variable names and function names should be written in snake_case, which means that all letters are lowercase and words are separated using an underscore.
-
Descriptive names are better than cryptic abbreviations because they help other programmers (and you) read and interpret your code. For example, student_name is better than sn. It may feel excessive when you write it, but when you return to your code you’ll find it much easier to understand.
Common syntax errors
-
Misspellings (拼寫錯誤)
-
Incorrect indentations (不正確的縮排)
-
Missing or incorrect key characters: (遺漏或不正確的字元)
-
Parenthetical types - ( curved ), [ square ], { curly } 括號型式 - 括號、中括號、大括號
-
Quote types - "straight-double" or 'straight-single', “curly-double” or ‘curly-single’ 引號型式
-
Block introduction characters, like colons - : 程式區塊字元
-
-
Data type mismatches 不符合的資料類型
-
Missing, incorrectly used, or misplaced Python reserved words 遺漏、不正確的使用 Python 保留字元
-
Using the wrong case (uppercase/lowercase) - Python is a case-sensitive language 錯誤使用大小寫
Annotating variables by type
註解變數的資料類型
This has several benefits: It reduces the chance of common mistakes, helps in documenting your code for others to reuse, and allows integrated development software (IDEs) and other tools to give you better feedback.
How to annotate a variable:
a = 3 #a is an integer
captain = "Picard" # type: str
captain: str = “Picard”
import typing
# Define a variable of type str
z: str = "Hello, world!"
# Define a variable of type int
x: int = 10
# Define a variable of type float
y: float = 1.23
# Define a variable of type list
list_of_numbers: typing.List[int] = [1, 2, 3]
# Define a variable of type tuple
tuple_of_numbers: typing.Tuple[int, int, int] = (1, 2, 3)
# Define a variable of type dict
dictionary: typing.Dict[str, int] = {"key1": 1, "key2": 2}
# Define a variable of type set
set_of_numbers: typing.Set[int] = {1, 2, 3}Data type conversions
Implicit vs explicit conversion 隱式 vs 顯式轉換
Implicit conversion is where the interpreter helps us out and automatically converts one data type into another, without having to explicitly tell it to do so.
Example:
# Converting integer into a float
print(7+8.5)Explicit conversion is where we manually convert from one data type to another by calling the relevant function for the data type we want to convert to.
We used this in our video example when we wanted to print a number alongside some text. Before we could do that, we needed to call the str() function to convert the number into a string.
- str() - converts a value (often numeric) to a string data type
- int() - converts a value (usually a float) to an integer data type
- float() - converts a value (usually an integer) to a float data type
Example:
# Convert a number into a string
base = 6
height = 3
area = (base*height)/2
print("The area of the triangle is: " + str(area)) Operators
Arithmetic operators
//整數除法 (Floor division operator)%餘數除法 (Modulo operator)**次方
Example for // & %
# even: 偶數
def is_even(number):
if number % 2 == 0:
return True
return False
#This code has no ouputdef calculate_storage(filesize):
block_size = 4096
# Use floor division to calculate how many blocks are fully occupied
full_blocks = filesize // block_size
# Use the modulo operator to check whether there's any remainder
partial_block_remainder = filesize % block_size
# Depending on whether there's a remainder or not, return
# the total number of bytes required to allocate enough blocks
# to store your data.
if partial_block_remainder > 0:
return (full_blocks + 1) * block_size
return full_blocks * block_size
print(calculate_storage(1)) # Should be 4096
print(calculate_storage(4096)) # Should be 4096
print(calculate_storage(4097)) # Should be 8192
print(calculate_storage(6000)) # Should be 8192Comparison operators
|
Symbol |
Name |
Expression |
Description |
|---|---|---|---|
|
== |
Equality operator |
a == b |
a is equal to b |
|
!= |
Not equal to operator |
a != b |
a is not equal to b |
|
> |
Greater than operator |
a > b |
a is larger than b |
|
>= |
Greater than or equal to operator |
a >= b |
a is larger than or equal to b |
|
< |
Less than operator |
a < b |
a is smaller than b |
|
<= |
Less than or equal to operator |
a <= b |
a is smaller than or equal to b |
Good coding style
-
Create a reusable function - Replace duplicate code with one reusable function to make the code easier to read and repurpose.
-
Refactor code - Update code so that it is self-documenting and the intent of the code is clear.
-
Add comments - Adding comments is part of creating self-documenting code. Using comments allows you to leave notes to yourself and/or other programmers to make the purpose of the code clear. 加入註解是建立自我文件化程式碼的一部分。使用註解可讓您為自己和/或其他程式設計師留下紀錄,以清楚說明程式碼的目的
Loops
While Loops
multiplier = 1
result = multiplier * 5
while result <= 50:
print(result)
multiplier += 1
result = multiplier * 5
print("Done")Common errors in Loops
-
Failure to initialize variables. Make sure all the variables used in the loop’s condition are initialized before the loop.
-
Unintended infinite loops. Make sure that the body of the loop modifies the variables used in the condition, so that the loop will eventually end for all possible values of the variables. You can often prevent an infinite loop by using the break keyword or by adding end criteria to the condition part of the while loop.
For Loops
friends = ['Taylor', 'Alex', 'Pat', 'Eli']
for friend in friends:
print("Hi " + friend)# °F to ℃
def to_celsius(x):
return (x-32)*5/9
for x in range(0,101,10):
print(x, to_celsius(x))for number in range(1, 6+1, 2):
print(number * 3)
# The loop should print 3, 9, 15Nested for Loops
嵌入式 for 迴圈
# home_team 主隊, away_team 客隊
teams = [ 'Dragons', 'Wolves', 'Pandas', 'Unicorns']
for home_team in teams:
for away_team in teams:
if home_team != away_team:
print(home_team + " vs " + away_team)List comprehensions
列表生成式: [x for x in sequence if condition]
# with for loop
numbers = [1, 2, 3, 4, 5]
squared_numbers = [x ** 2 for x in numbers]
print(squared_numbers)# with for loop and if
sequence = range(10)
new_list = [x for x in sequence if x % 2 == 0]Recursive function
遞歸函式 Use cases
- Goes through a bunch of directories in your computer and calculates how many files are contained in each.
- Review groups in Active Directory.
'''
def recursive_function(parameters):
if base_case_condition(parameters):
return base_case_value
recursive_function(modified_parameters)
'''
def factorial(n):
if n < 2:
return 1
return n * factorial(n-1)def factorial(n):
print("Factorial called with " + str(n))
if n < 2:
print("Returning 1")
return 1
result = n * factorial(n-1)
print("Returning " + str(result) + " for factorial of " + str(n))
return result
factorial(4)Types of iterables
- String: 有順序 (sequential)、不可變 (immutable) 的文字資料的集合
- List: 有順序 (sequential)、可變 (mutable) 的任何類型資料的集合
- Dictionary: 沒有順序、儲存 key:value 鍵值對的資料
- Tuple: 有順序 (sequential)、不可變 (immutable) 的任何類型資料的集合
- Set: 沒有順序 (unordered)、不重複 (unique) 元素資料的集合
Resources
Naming rules and conventions
Annotating variables by type
Dictionaries vs. Lists
Dictionaries are similar to lists, but there are a few differences:
Both dictionaries and lists:
-
are used to organize elements into collections;
-
are used to initialize a new dictionary or list, use empty brackets;
-
can iterate through the items or elements in the collection; and
-
can use a variety of methods and operations to create and change the collections, like removing and inserting items or elements.
Dictionaries only:
-
are unordered sets;
-
have keys that can be a variety of data types, including strings, integers, floats, tuples;.
-
can access dictionary values by keys;
-
use square brackets inside curly brackets { [ ] };
-
use colons between the key and the value(s);
-
use commas to separate each key group and each value within a key group;
-
make it quicker and easier for a Python interpreter to find specific elements, as compared to a list.
pet_dictionary = {"dogs": ["Yorkie", "Collie", "Bulldog"], "cats": ["Persian", "Scottish Fold", "Siberian"], "rabbits": ["Angora", "Holland Lop", "Harlequin"]}
print(pet_dictionary.get("dogs", 0))
# Should print ['Yorkie', 'Collie', 'Bulldog']Lists only:
-
are ordered sets;
-
access list elements by index positions;
-
require that these indices be integers;
-
use square brackets [ ];
-
use commas to separate each list element.
pet_list = ["Yorkie", "Collie", "Bulldog", "Persian", "Scottish Fold", "Siberian", "Angora", "Holland Lop", "Harlequin"]
print(pet_list[0:3])
# Should print ['Yorkie', 'Collie', 'Bulldog']
Classes and methods
Defining classes and methods
class ClassName:
def method_name(self, other_parameters):
body_of_methodSpecial methods
-
Special methods start and end with
__. -
Special methods have specific names, like
__init__for the constructor or__str__for the conversion to string. -
The methods
__str__and__repr__allow you to define human-readable and unambiguous string representations of your objects, respectively. -
By defining methods like
__eq__,__ne__,__lt__,__gt__,__le__, and__ge__, you can control how objects of your class are compared.
With the __init__ method:
用途:接受參數的傳入,並帶入變數 self.XXX
class Apple:
def __init__(self, color, flavor):
self.color = color
self.flavor = flavor
honeycrisp = Apple("red", "sweet")
fuji = Apple("red", "tart")
print(honeycrisp.flavor)
print(fuji.flavor)With the __str__ method:
When you print() something, Python calls the object’s __str__() method and outputs whatever that method returns
class Apple:
def __init__(self, color, flavor):
self.color = color
self.flavor = flavor
def __str__(self):
return "an apple which is {} and {}".format(self.color, self.flavor)
honeycrisp = Apple("red", "sweet")
print(honeycrisp)
# prints "an apple which is red and sweet"With the custom method
class Triangle:
def __init__(self, base, height):
self.base = base
self.height = height
def area(self):
return 0.5 * self.base * self.height
def __add__(self, other):
return self.area() + other.area()
triangle1 = Triangle(10, 5)
triangle2 = Triangle(6, 8)
print("The area of triangle 1 is", triangle1.area())
print("The area of triangle 2 is", triangle2.area())
print("The area of both triangles is", triangle1 + triangle2)Examples
登入紀錄報告
- Custom Class
- Dictionary/Set/List Data
- Set Methods
def get_event_date(event):
return event.date
def current_users(events):
events.sort(key=get_event_date)
machines = {}
for event in events:
if event.machine not in machines:
machines[event.machine] = set()
if event.type == "login":
machines[event.machine].add(event.user)
elif event.type == "logout":
machines[event.machine].remove(event.user)
return machines
def generate_report(machines):
for machine, users in machines.items():
if len(users) > 0:
user_list = ", ".join(users)
print("{}: {}".format(machine, user_list))
class Event:
def __init__(self, event_date, event_type, machine_name, user):
self.date = event_date
self.type = event_type
self.machine = machine_name
self.user = user
events = [
Event('2020-01-21 12:45:46', 'login', 'myworkstation.local', 'jordan'),
Event('2020-01-22 15:53:42', 'logout', 'webserver.local', 'jordan'),
Event('2020-01-21 18:53:21', 'login', 'webserver.local', 'lane'),
Event('2020-01-22 10:25:34', 'logout', 'myworkstation.local', 'jordan'),
Event('2020-01-21 08:20:01', 'login', 'webserver.local', 'jordan'),
Event('2020-01-23 11:24:35', 'login', 'mailserver.local', 'chris'),
]
users = current_users(events)
print(users)
# Output: {'webserver.local': {'lane'}, 'myworkstation.local': set(), 'mailserver.local': {'chris'}}
generate_report(users)
# Output:
# webserver.local: lane
# mailserver.local: chris分析 Syslog
- dictionary.get()
- re.search()
- with open() as f
import re
import sys
logfile = sys.argv[1]
usernames = {}
with open(logfile) as f:
for line in f:
if "CRON" not in line:
continue
pattern = r"USER \((\w+)\)$"
result = re.search(pattern, line)
if result is None:
continue
name = result[1]
usernames[name] = usernames.get(name, 0) + 1
print(usernames)進階版
fishy.log:
July 31 02:25:52 mycomputername system[41921]: WARN Failed to start CPU thread[39016]
July 31 02:34:37 mycomputername kernel[32280]: INFO Loading...
July 31 02:36:44 mycomputername NetworkManager[90289]: WARN Failed to start CPU thread[39016]
July 31 02:39:01 mycomputername CRON[89330]: ERROR Unable to perform package upgrade
July 31 02:45:39 mycomputername utility[57387]: INFO Access permitted
July 31 02:58:44 mycomputername process[44707]: WARN Computer needs to be turned off and on again
July 31 02:59:35 mycomputername system[55024]: WARN Packet loss
July 31 03:09:30 mycomputername kernel[40705]: ERROR The cake is a lie!
July 31 03:23:16 mycomputername cacheclient[57185]: INFO Checking process [16121]
July 31 03:26:56 mycomputername cacheclient[90154]: INFO Healthy resource usage
July 31 03:28:52 mycomputername CRON[55441]: INFO Loading...
July 31 03:29:34 mycomputername dhcpclient[69232]: ERROR Unable to download more RAM
July 31 03:34:41 mycomputername NetworkManager[14120]: ERROR 404 error not found
July 31 03:36:26 mycomputername dhcpclient[79731]: ERROR The cake is a lie!
July 31 03:38:24 mycomputername CRON[92141]: INFO Access permitted
July 31 03:40:00 mycomputername dhcpclient[40114]: INFO Starting sync
July 31 03:42:45 mycomputername utility[53726]: INFO I'm sorry Dave. I'm afraid I can't do that
July 31 03:47:07 mycomputername NetworkManager[63805]: WARN Please reboot user
July 31 04:09:16 mycomputername CRON[52593]: WARN PC Load Letter
July 31 04:11:32 mycomputername CRON[51253]: ERROR: Failed to start CRON job due to script syntax error. Inform the CRON job owner!
July 31 04:11:32 mycomputername jam_tag=psim[84082]: ERROR ID: 10t
July 31 04:12:05 mycomputername utility[63418]: INFO Successfully connected
July 31 04:14:22 mycomputername utility[53225]: ERROR I am error
July 31 04:31:00 mycomputername NetworkManager[23060]: ERROR Out of yellow ink, specifically, even though you want grayscalefind_error.py
Usage: ./find_error.py fishy.log
import sys
import os
import re
def error_search(log_file):
error = input("What is the error? ")
returned_errors = []
with open(log_file, mode='r', encoding='UTF-8') as file:
for log in file.readlines():
error_patterns = ["error"]
for i in range(len(error.split(' '))):
error_patterns.append(r"{}".format(error.split(' ')[i].lower()))
if all(re.search(error_pattern, log.lower()) for error_pattern in error_patterns):
returned_errors.append(log)
file.close()
return returned_errors
def file_output(returned_errors):
with open(os.path.expanduser('~') + '/data/errors_found.log', 'w') as file:
for error in returned_errors:
file.write(error)
file.close()
if __name__ == "__main__":
log_file = sys.argv[1]
returned_errors = error_search(log_file)
file_output(returned_errors)
sys.exit(0)分析 Syslog 2
syslog.log :
Jan 31 00:09:39 ubuntu.local ticky: INFO Created ticket [#4217] (mdouglas)
Jan 31 00:16:25 ubuntu.local ticky: INFO Closed ticket [#1754] (noel)
Jan 31 00:21:30 ubuntu.local ticky: ERROR The ticket was modified while updating (breee)
Jan 31 00:44:34 ubuntu.local ticky: ERROR Permission denied while closing ticket (ac)
Jan 31 01:00:50 ubuntu.local ticky: INFO Commented on ticket [#4709] (blossom)
Jan 31 01:29:16 ubuntu.local ticky: INFO Commented on ticket [#6518] (rr.robinson)
Jan 31 01:33:12 ubuntu.local ticky: ERROR Tried to add information to closed ticket (mcintosh)
Jan 31 01:43:10 ubuntu.local ticky: ERROR Tried to add information to closed ticket (jackowens)
Jan 31 01:49:29 ubuntu.local ticky: ERROR Tried to add information to closed ticket (mdouglas)
Jan 31 02:30:04 ubuntu.local ticky: ERROR Timeout while retrieving information (oren)
Jan 31 02:55:31 ubuntu.local ticky: ERROR Ticket doesn't exist (xlg)
Jan 31 03:05:35 ubuntu.local ticky: ERROR Timeout while retrieving information (ahmed.miller)
Jan 31 03:08:55 ubuntu.local ticky: ERROR Ticket doesn't exist (blossom)
Jan 31 03:39:27 ubuntu.local ticky: ERROR The ticket was modified while updating (bpacheco)
Jan 31 03:47:24 ubuntu.local ticky: ERROR Ticket doesn't exist (enim.non)
Jan 31 04:30:04 ubuntu.local ticky: ERROR Permission denied while closing ticket (rr.robinson)
Jan 31 04:31:49 ubuntu.local ticky: ERROR Tried to add information to closed ticket (oren)
Jan 31 04:32:49 ubuntu.local ticky: ERROR Timeout while retrieving information (mcintosh)
Jan 31 04:44:23 ubuntu.local ticky: ERROR Timeout while retrieving information (ahmed.miller)
Jan 31 04:44:46 ubuntu.local ticky: ERROR Connection to DB failed (jackowens)
Jan 31 04:49:28 ubuntu.local ticky: ERROR Permission denied while closing ticket (flavia)
Jan 31 05:12:39 ubuntu.local ticky: ERROR Tried to add information to closed ticket (oren)
Jan 31 05:18:45 ubuntu.local ticky: ERROR Tried to add information to closed ticket (sri)
Jan 31 05:23:14 ubuntu.local ticky: INFO Commented on ticket [#1097] (breee)
Jan 31 05:35:00 ubuntu.local ticky: ERROR Connection to DB failed (nonummy)
Jan 31 05:45:30 ubuntu.local ticky: INFO Created ticket [#7115] (noel)
Jan 31 05:51:30 ubuntu.local ticky: ERROR The ticket was modified while updating (flavia)
Jan 31 05:57:46 ubuntu.local ticky: INFO Commented on ticket [#2253] (nonummy)
Jan 31 06:12:02 ubuntu.local ticky: ERROR Connection to DB failed (oren)
Jan 31 06:26:38 ubuntu.local ticky: ERROR Timeout while retrieving information (xlg)
Jan 31 06:32:26 ubuntu.local ticky: INFO Created ticket [#7298] (ahmed.miller)
Jan 31 06:36:25 ubuntu.local ticky: ERROR Timeout while retrieving information (flavia)
Jan 31 06:57:00 ubuntu.local ticky: ERROR Connection to DB failed (jackowens)
Jan 31 06:59:57 ubuntu.local ticky: INFO Commented on ticket [#7255] (oren)
Jan 31 07:59:56 ubuntu.local ticky: ERROR Ticket doesn't exist (flavia)
Jan 31 08:01:40 ubuntu.local ticky: ERROR Tried to add information to closed ticket (jackowens)
Jan 31 08:03:19 ubuntu.local ticky: INFO Closed ticket [#1712] (britanni)
Jan 31 08:22:37 ubuntu.local ticky: INFO Created ticket [#2860] (mcintosh)
Jan 31 08:28:07 ubuntu.local ticky: ERROR Timeout while retrieving information (montanap)
Jan 31 08:49:15 ubuntu.local ticky: ERROR Permission denied while closing ticket (britanni)
Jan 31 08:50:50 ubuntu.local ticky: ERROR Permission denied while closing ticket (montanap)
Jan 31 09:04:27 ubuntu.local ticky: ERROR Tried to add information to closed ticket (noel)
Jan 31 09:15:41 ubuntu.local ticky: ERROR Timeout while retrieving information (oren)
Jan 31 09:18:47 ubuntu.local ticky: INFO Commented on ticket [#8385] (mdouglas)
Jan 31 09:28:18 ubuntu.local ticky: INFO Closed ticket [#2452] (jackowens)
Jan 31 09:41:16 ubuntu.local ticky: ERROR Connection to DB failed (ac)
Jan 31 10:11:35 ubuntu.local ticky: ERROR Timeout while retrieving information (blossom)
Jan 31 10:21:36 ubuntu.local ticky: ERROR Permission denied while closing ticket (montanap)
Jan 31 11:04:02 ubuntu.local ticky: ERROR Tried to add information to closed ticket (breee)
Jan 31 11:19:37 ubuntu.local ticky: ERROR Connection to DB failed (sri)
Jan 31 11:22:06 ubuntu.local ticky: ERROR Timeout while retrieving information (montanap)
Jan 31 11:31:34 ubuntu.local ticky: ERROR Permission denied while closing ticket (ahmed.miller)
Jan 31 11:40:25 ubuntu.local ticky: ERROR Connection to DB failed (mai.hendrix)
Jan 31 11:47:07 ubuntu.local ticky: INFO Commented on ticket [#4562] (ac)
Jan 31 11:58:33 ubuntu.local ticky: ERROR Tried to add information to closed ticket (ahmed.miller)
Jan 31 12:00:17 ubuntu.local ticky: INFO Created ticket [#7897] (kirknixon)
Jan 31 12:02:49 ubuntu.local ticky: ERROR Permission denied while closing ticket (mai.hendrix)
Jan 31 12:20:23 ubuntu.local ticky: ERROR Connection to DB failed (kirknixon)
Jan 31 12:20:40 ubuntu.local ticky: ERROR Ticket doesn't exist (flavia)
Jan 31 12:24:32 ubuntu.local ticky: INFO Created ticket [#5784] (sri)
Jan 31 12:50:10 ubuntu.local ticky: ERROR Permission denied while closing ticket (blossom)
Jan 31 12:58:16 ubuntu.local ticky: ERROR Tried to add information to closed ticket (nonummy)
Jan 31 13:08:10 ubuntu.local ticky: INFO Closed ticket [#8685] (rr.robinson)
Jan 31 13:48:45 ubuntu.local ticky: ERROR The ticket was modified while updating (breee)
Jan 31 14:13:00 ubuntu.local ticky: INFO Commented on ticket [#4225] (noel)
Jan 31 14:38:50 ubuntu.local ticky: ERROR The ticket was modified while updating (enim.non)
Jan 31 14:41:18 ubuntu.local ticky: ERROR Timeout while retrieving information (xlg)
Jan 31 14:45:55 ubuntu.local ticky: INFO Closed ticket [#7948] (noel)
Jan 31 14:50:41 ubuntu.local ticky: INFO Commented on ticket [#8628] (noel)
Jan 31 14:56:35 ubuntu.local ticky: ERROR Tried to add information to closed ticket (noel)
Jan 31 15:27:53 ubuntu.local ticky: ERROR Ticket doesn't exist (blossom)
Jan 31 15:28:15 ubuntu.local ticky: ERROR Permission denied while closing ticket (enim.non)
Jan 31 15:44:25 ubuntu.local ticky: INFO Closed ticket [#7333] (enim.non)
Jan 31 16:17:20 ubuntu.local ticky: INFO Commented on ticket [#1653] (noel)
Jan 31 16:19:40 ubuntu.local ticky: ERROR The ticket was modified while updating (mdouglas)
Jan 31 16:24:31 ubuntu.local ticky: INFO Created ticket [#5455] (ac)
Jan 31 16:35:46 ubuntu.local ticky: ERROR Timeout while retrieving information (oren)
Jan 31 16:53:54 ubuntu.local ticky: INFO Commented on ticket [#3813] (mcintosh)
Jan 31 16:54:18 ubuntu.local ticky: ERROR Connection to DB failed (bpacheco)
Jan 31 17:15:47 ubuntu.local ticky: ERROR The ticket was modified while updating (mcintosh)
Jan 31 17:29:11 ubuntu.local ticky: ERROR Connection to DB failed (oren)
Jan 31 17:51:52 ubuntu.local ticky: INFO Closed ticket [#8604] (mcintosh)
Jan 31 18:09:17 ubuntu.local ticky: ERROR The ticket was modified while updating (noel)
Jan 31 18:43:01 ubuntu.local ticky: ERROR Ticket doesn't exist (nonummy)
Jan 31 19:00:23 ubuntu.local ticky: ERROR Timeout while retrieving information (blossom)
Jan 31 19:20:22 ubuntu.local ticky: ERROR Timeout while retrieving information (mai.hendrix)
Jan 31 19:59:06 ubuntu.local ticky: INFO Created ticket [#6361] (enim.non)
Jan 31 20:02:41 ubuntu.local ticky: ERROR Timeout while retrieving information (xlg)
Jan 31 20:21:55 ubuntu.local ticky: INFO Commented on ticket [#7159] (ahmed.miller)
Jan 31 20:28:26 ubuntu.local ticky: ERROR Connection to DB failed (breee)
Jan 31 20:35:17 ubuntu.local ticky: INFO Created ticket [#7737] (nonummy)
Jan 31 20:48:02 ubuntu.local ticky: ERROR Connection to DB failed (mdouglas)
Jan 31 20:56:58 ubuntu.local ticky: INFO Closed ticket [#4372] (oren)
Jan 31 21:00:23 ubuntu.local ticky: INFO Commented on ticket [#2389] (sri)
Jan 31 21:02:06 ubuntu.local ticky: ERROR Connection to DB failed (breee)
Jan 31 21:20:33 ubuntu.local ticky: INFO Closed ticket [#3297] (kirknixon)
Jan 31 21:29:24 ubuntu.local ticky: ERROR The ticket was modified while updating (blossom)
Jan 31 22:58:55 ubuntu.local ticky: INFO Created ticket [#2461] (jackowens)
Jan 31 23:25:18 ubuntu.local ticky: INFO Closed ticket [#9876] (blossom)
Jan 31 23:35:40 ubuntu.local ticky: INFO Created ticket [#5896] (mcintosh)ticky_check.py
Usage: ./ticky_check.py
#!/usr/bin/env python3
import sys
import re
import operator
import csv
# Dict: Count number of entries for each user
per_user = {} # Splitting between INFO and ERROR
# Dict: Number of different error messages
errors = {}
# * Read file and create dictionaries
with open('syslog.log') as file:
# read each line
for line in file.readlines():
# regex search
# * Sample Line of log file
# "May 27 11:45:40 ubuntu.local ticky: INFO: Created ticket [#1234] (username)"
match = re.search(
r"ticky: ([\w+]*):? ([\w' ]*)[\[[#0-9]*\]?]? ?\((.*)\)$", line)
code, error_msg, user = match.group(1), match.group(2), match.group(3)
# Populates error dict with ERROR messages from log file
if error_msg not in errors.keys():
errors[error_msg] = 1
else:
errors[error_msg] += 1
# Populates per_user dict with users and default values
if user not in per_user.keys():
per_user[user] = {}
per_user[user]['INFO'] = 0
per_user[user]['ERROR'] = 0
# Populates per_user dict with users logs entry
if code == 'INFO':
if user not in per_user.keys():
per_user[user] = {}
per_user[user]['INFO'] = 0
else:
per_user[user]["INFO"] += 1
elif code == 'ERROR':
if user not in per_user.keys():
per_user[user] = {}
per_user[user]['INFO'] = 0
else:
per_user[user]['ERROR'] += 1
# Sorted by VALUE (Most common to least common)
errors_list = sorted(errors.items(), key=operator.itemgetter(1), reverse=True)
# Sorted by USERNAME
per_user_list = sorted(per_user.items(), key=operator.itemgetter(0))
file.close()
# Insert at the beginning of the list
errors_list.insert(0, ('Error', 'Count'))
per_user_list.insert(0, ('Username', {'INFO': 'INFO', 'ERROR': 'ERROR'}))
# * Create CSV file user_statistics
with open('user_statistics.csv', 'w', newline='') as user_csv:
for key, value in per_user_list:
user_csv.write(str(key) + ',' +
str(value['INFO']) + ',' + str(value['ERROR'])+'\n')
# * Create CSV error_message
with open('error_message.csv', 'w', newline='') as error_csv:
for key, value in errors_list:
error_csv.write(str(key) + ',' + str(value) + '\n')csv_to_html.py
Usage: ./csv_to_html.py user_statistics.csv /var/www/html/<html-filename>.html
#!/usr/bin/env python3
import sys
import csv
import os
def process_csv(csv_file):
"""Turn the contents of the CSV file into a list of lists"""
print("Processing {}".format(csv_file))
with open(csv_file,"r") as datafile:
data = list(csv.reader(datafile))
return data
def data_to_html(title, data):
"""Turns a list of lists into an HTML table"""
# HTML Headers
html_content = """
<html>
<head>
<style>
table {
width: 25%;
font-family: arial, sans-serif;
border-collapse: collapse;
}
tr:nth-child(odd) {
background-color: #dddddd;
}
td, th {
border: 1px solid #dddddd;
text-align: left;
padding: 8px;
}
</style>
</head>
<body>
"""
# Add the header part with the given title
html_content += "<h2>{}</h2><table>".format(title)
# Add each row in data as a row in the table
# The first line is special and gets treated separately
for i, row in enumerate(data):
html_content += "<tr>"
for column in row:
if i == 0:
html_content += "<th>{}</th>".format(column)
else:
html_content += "<td>{}</td>".format(column)
html_content += "</tr>"
html_content += """</tr></table></body></html>"""
return html_content
def write_html_file(html_string, html_file):
# Making a note of whether the html file we're writing exists or not
if os.path.exists(html_file):
print("{} already exists. Overwriting...".format(html_file))
with open(html_file,'w') as htmlfile:
htmlfile.write(html_string)
print("Table succesfully written to {}".format(html_file))
def main():
"""Verifies the arguments and then calls the processing function"""
# Check that command-line arguments are included
if len(sys.argv) < 3:
print("ERROR: Missing command-line argument!")
print("Exiting program...")
sys.exit(1)
# Open the files
csv_file = sys.argv[1]
html_file = sys.argv[2]
# Check that file extensions are included
if ".csv" not in csv_file:
print('Missing ".csv" file extension from first command-line argument!')
print("Exiting program...")
sys.exit(1)
if ".html" not in html_file:
print('Missing ".html" file extension from second command-line argument!')
print("Exiting program...")
sys.exit(1)
# Check that the csv file exists
if not os.path.exists(csv_file):
print("{} does not exist".format(csv_file))
print("Exiting program...")
sys.exit(1)
# Process the data and turn it into an HTML
data = process_csv(csv_file)
title = os.path.splitext(os.path.basename(csv_file))[0].replace("_", " ").title()
html_string = data_to_html(title, data)
write_html_file(html_string, html_file)
if __name__ == "__main__":
main()Course 2
Understanding Slowness
Slow Web Server
ab - Apache benchmark tool
ab -n 500 site.example.comProfiling - Improving the code
Profiling 可透過監控和分析即時資源使用情況,協助軟體工程師設計高效率且有效的應用程式。對 IT 專業人員而言,Profile 的能力是非常寶貴的工具。雖然 Profiling 並非新技術,但類似技術在今日仍然適用,而且 Profiling 可改善反應速度並最佳化資源使用,為軟體開發奠定穩固的基礎
A profiler is a tool that measures the resources that our code is using, giving us a better understanding of what's going on.
- gprof : For C program
- cProfile : For Python program
- pprofile3 + kcachegrind(GUI) : For Python program
- Flat, Call-graph, and Input-sensitive are integral to debugging
- timeit (python module) : Measure execution time of small code snippets
Parallelizing operations
Python modules
- threading
- asyncio
- future
Concurrency for I/O-bound tasks
Python has two main approaches to implementing concurrency: threading and asyncio.
-
Threading is an efficient method for overlapping waiting times. This makes it well-suited for tasks involving many I/O operations, such as file I/O or network operations that spend significant time waiting. There are however some limitations with threading in Python due to the Global Interpreter Lock (GIL), which can limit the utilization of multiple cores.
-
Alternatively, asyncio is another powerful Python approach for concurrency that uses the event loop to manage task switching. Asyncio provides a higher degree of control, scalability, and power than threading for I/O-bound tasks. Any application that involves reading and writing data can benefit from it, since it speeds up I/O-based programs. Additionally, asyncio operates cooperatively and bypasses GIL limitations, enabling better performance for I/O-bound tasks.
Python supports concurrent execution through both threading and asyncio; however, asyncio is particularly beneficial for I/O-bound tasks, making it significantly faster for applications that read and write a lot of data.
Parallelism for CPU-bound tasks
Parallelism is a powerful technique for programs that heavily rely on the CPU to process large volumes of data constantly. It's especially useful for CPU-bound tasks like calculations, simulations, and data processing.
Instead of interleaving and executing tasks concurrently, parallelism enables multiple tasks to run simultaneously on multiple CPU cores. This is crucial for applications that require significant CPU resources to handle intense computations in real-time.
Multiprocessing libraries in Python facilitate parallel execution by distributing tasks across multiple CPU cores. It ensures performance by giving each process its own Python interpreter and memory space. It allows CPU-bound Python programs to process data more efficiently by giving each process its own Python interpreter and memory space; this eliminates conflicts and slowdowns caused by sharing resources. Having said that, you should also remember that when running multiple tasks simultaneously, you need to manage resources carefully.
Combining concurrency and parallelism
Combining concurrency and parallelism can improve performance. In certain complex applications with both I/O-bound and CPU-bound tasks, you can use asyncio for concurrency and multiprocessing for parallelism.
With asyncio, you make I/O-bound tasks more efficient as the program can do other things while waiting for file operations.
On the other hand, multiprocessing allows you to distribute CPU-bound computations, like heavy calculations, across multiple processors for faster execution.
By combining these techniques, you can create a well-optimized and responsive program. Your I/O-bound tasks benefit from concurrency, while CPU-bound tasks leverage parallelism.
psutil
# Installation
pip3 install psutilUsage
import psutil
# for checking CPU usage
psutil.cpu_percent()
# For checking disk I/O,
psutil.disk_io_counters()
# For checking the network I/O bandwidth:
psutil.net_io_counters()rsync with python
Use the rsync command in Python
import subprocess
src = "<source-path>" # replace <source-path> with the source directory
dest = "<destination-path>" # replace <destination-path> with the destination directory
subprocess.call(["rsync", "-arq", src, dest])Segmentation fault
記憶體區段錯誤 - 這通常發生在低階語言開發的程式,例如 C, C++。這類的程式開發會需要對記憶體進行配置,當程式嘗試存取無效的記憶體位址時,程式就會當掉結束,並出現這種錯誤。
gdb
ulimit -c unlimited: 設定產生 core file 時為 unlimitedgdb -c <core-file> <program-name>: 解析 core file 的內容
ulimit -c unlimited
gdb -c core examplegdb sub-commands
- backtrace : 回溯程式異常中止的狀態
- up : 移至 backtrace 中斷點的函數資訊
- list : 顯示目前程式碼周圍的行
- print : 輸出變數的內容
gdb -c core example
....
(gdb) backtrace
....
(gdb) up
...
list
...
print i
...
print argv[0]
...
print argv[1]Python Cheat Sheet
String Methods
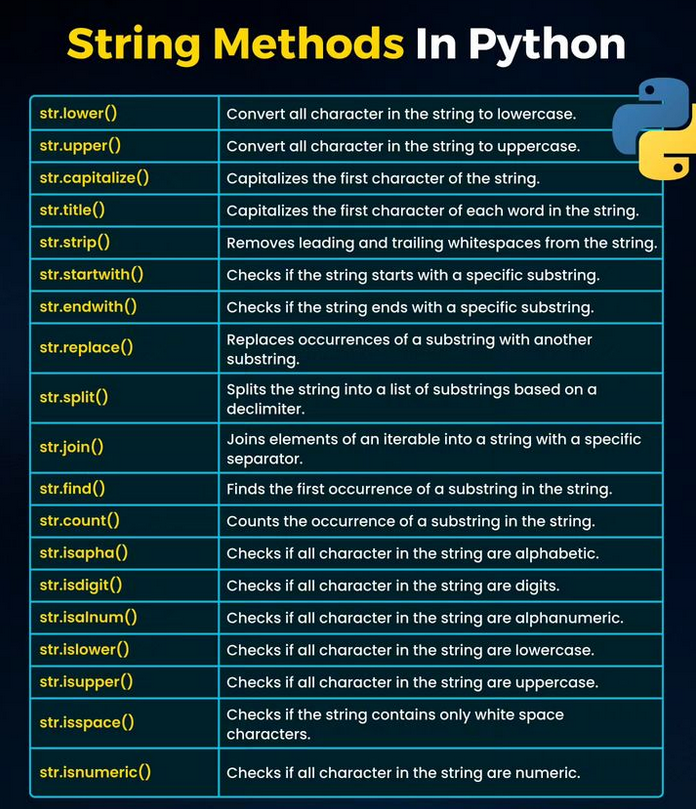
Set/List/Dictionary Methods

List methods

List methods
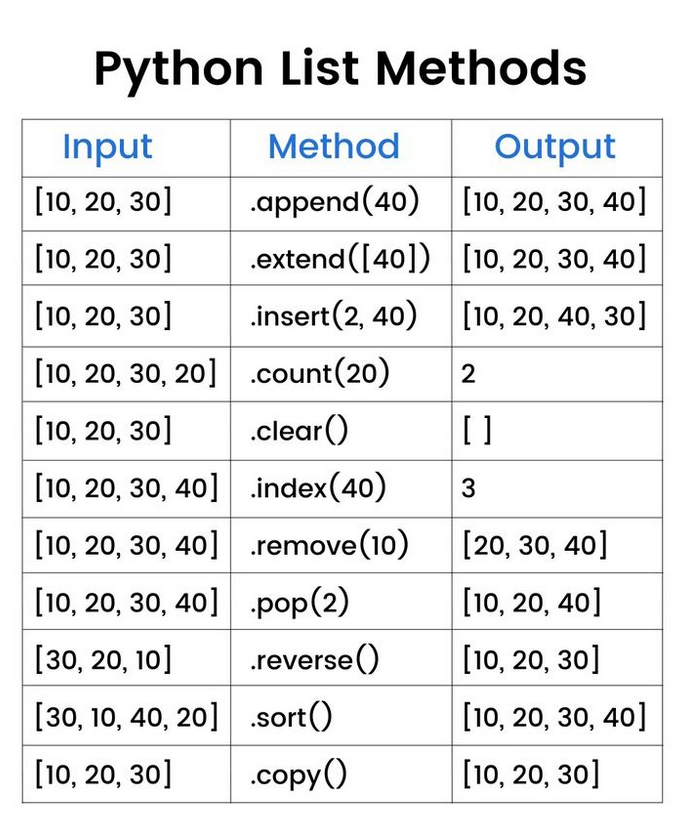
Data Structures

Pandas

Set 集合
當您想要儲存一堆元素,並確定這些元素只出現一次時,就會使用集合(set)。集合(set)的元素也必須是不可變的。您可以將其視為字典 (dictionary) 中沒有關聯值 (value) 的鍵 (key)
- 符號用大括號
- 內容必須是唯一值,不可重複;如果提供的元素有重複值,程式不會發生錯誤,set 只會存在一個元素
- 建立空白 set 要用函式
set() - 資料不是序列,元素之間沒有索引及順序關係
A = {"jlanksy", "drosas", "nmason"}
# Create an empty set
B = set()
# set 不會有重複的元素
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # show that duplicates have been removed
# Output: {'orange', 'banana', 'pear', 'apple'}Methods
.add()
.add() 新增元素
s = {1, 2, 3, 4, 5}
s.add(6)
s.add(7)
s.add(7)
print(s)
# Output {1, 2, 3, 4, 5, 6, 7}.remove()
.remove() 刪除元素
s = {1, 2, 3, 4, 5}
s.remove(5)
#s.remove(6) # Error
print(s)
# Output {1, 2, 3, 4}範例
元素 in set
fruits = {'apple','banana','orange','lemon'}
print('tomato' in fruits) # Output False
result = 'apple' in fruits
print(result) # Output TrueSet 交集
fruits1 = {'apple','banana','orange','lemon'}
fruits2 = {'tomato','apple','banana'}
print(fruits1 & fruits2) # Output {'apple', 'banana'}
print(fruits2 & fruits1) # Output {'apple', 'banana'}nums1 = {1,2,3,4,5}
nums2 = {2,4,6,8,10}
print(nums1.intersection(nums2)) # Output {2, 4}
print(nums2.intersection(nums1)) # Output {2, 4}Set 聯集
fruits1 = {'apple','banana','orange','lemon'}
fruits2 = {'tomato','apple','banana'}
print(fruits1 | fruits2) # Output {'orange', 'banana', 'tomato', 'lemon', 'apple'}
print(fruits2 | fruits1) # Output {'orange', 'banana', 'tomato', 'lemon', 'apple'}nums1 = {1,2,3,4,5}
nums2 = {2,4,6,8,10}
print(nums1.union(nums2)) # Output {1, 2, 3, 4, 5, 6, 8, 10}
print(nums2.union(nums1)) # Output {1, 2, 3, 4, 5, 6, 8, 10}Set 差集
fruits1 = {'apple','banana','orange','lemon'}
fruits2 = {'orange','lemon','tomato'}
print(fruits1 - fruits2) # Output {'apple', 'banana'}
print(fruits2 - fruits1) # Output {'tomato'}nums1 = {1,2,3,4,5}
nums2 = {4,5,6,7,8}
print(nums1.difference(nums2)) # Output {1, 2, 3}
print(nums2.difference(nums1)) # Output {8, 6, 7}Set 對稱差集
fruits1 = {'apple','banana','orange','lemon'}
fruits2 = {'orange','lemon','tomato'}
print(fruits1 ^ fruits2) # Output {'tomato', 'banana', 'apple'}
print(fruits2 ^ fruits1) # Output {'tomato', 'banana', 'apple'}nums1 = {1,2,3,4,5}
nums2 = {4,5,6,7,8}
print(nums1.symmetric_difference(nums2)) # Output {1, 2, 3, 6, 7, 8}
print(nums2.symmetric_difference(nums1)) # Output {1, 2, 3, 6, 7, 8}CSV
Reading CSV files
csv.reader(<file-object>, delimiter=':'): input is CSV file. the parameterdelimiteris optional
csv_file.txt
Sabrina Green,802-867-5309,System Administrator
Eli Jones,684-3481127,IT specialist
Melody Daniels,846-687-7436,Programmer
Charlie Rivera,698-746-3357,Web Developerimport csv
f = open("csv_file.txt")
csv_f = csv.reader(f)
for row in csv_f:
name, phone, role = row
print("Name: {}, Phone: {}, Role: {}".format(name, phone, role))
f.close()Output:
Name: Sabrina Green, Phone: 802-867-5309, Role: System Administrator
Name: Eli Jones, Phone: 684-3481127, Role: IT specialist
Name: Melody Daniels, Phone: 846-687-7436, Role: Programmer
Name: Charlie Rivera, Phone: 698-746-3357, Role: Web DeveloperGenerating CSV
csv.writer(): input is a list with sublist, for example[[col1, col2, col3], [col1, col2, col3]].writerow(): 一次寫一筆.writerows(): 一次寫多筆
import csv
hosts = [["workstation.local", "192.168.25.46"],["webserver.cloud", "10.2.5.6"]]
with open('hosts.csv', 'w') as hosts_csv:
writer = csv.writer(hosts_csv)
writer.writerows(hosts)With list
Reading a CSV with the list
user_emails.csv
Full Name, Email Address
Blossom Gill, blossom@xyz.edu
Hayes Delgado, nonummy@utnisia.com
Petra Jones, ac@xyz.edu
Oleg Noel, noel@liberomauris.ca
Ahmed Miller, ahmed.miller@nequenonquam.co.uk
Macaulay Douglas, mdouglas@xyz.edu
Aurora Grant, enim.non@xyz.edulist(csv.reader(file)): 用list()函式將 CSV 內容轉成 List 格式,不使用函式也行,預設格式就是 Listuser_data_list[1:]: 不包含第一行標題的所有內容- data[1].strip() : CSV 第 2 欄資料且移除前後空白字元
user_email_list = []
with open(csv_file_location, 'r') as f:
user_data_list = list(csv.reader(f))
user_email_list = [data[1].strip() for data in user_data_list[1:]]With dictionary
Reading a CSV with the dictionary
csv.DictReader(): input is a CSV file, 預設第一行為標題行
# software.csv
# name,version,status,users
# MailTree,5.34,production,324
# CalDoor,1.25.1,beta,22
# Chatty Chicken,0.34,alpha,4
with open('software.csv') as software:
reader = csv.DictReader(software)
for row in reader:
print(("{} has {} users").format(row["name"], row["users"]))
# Output:
# MailTree has 324 users
# CalDoor has 22 users
# Chatty Chicken has 4 usersWriting a CSV with the dictionary
csv.DictWriter(<file-object>, fieldnames=<column-list>): input is a dictionary- .writerheader() : 寫標題行
- .writerows() : input is a list with multiple dictionaries
users = [ {"name": "Sol Mansi", "username": "solm", "department": "IT infrastructure"},
{"name": "Lio Nelson", "username": "lion", "department": "User Experience Research"},
{"name": "Charlie Grey", "username": "greyc", "department": "Development"}]
keys = ["name", "username", "department"]
with open('by_department.csv', 'w') as by_department:
writer = csv.DictWriter(by_department, fieldnames=keys)
writer.writeheader()
writer.writerows(users)
# by_department.csv:
# Name,username,department
# Sol Mansi,solm, IT infrastructure
# Lio Nelson,lion,User Experience Researcher
# Charlie Grey,greyc,DevelopmentError Handling
捕捉錯誤與異常訊息
適用實例:
-
A file doesn’t exist
-
A network or database connection fails
-
Your code receives invalid input
- Unit Test (單元測試)
Try-Except
except Exception: 任何異常print(, file=sys.stderr): 以 STDERR 方式輸出
def main():
if len(sys.argv) < 2:
return usage()
try:
date, title, emails = sys.argv[1].split('|')
message = message_template(date, title)
send_message(message, emails)
print("Successfully sent reminders to:", emails)
except Exception as e:
print("Failure to send email", file=sys.stderr)
except Exception as e:
print("Failure to send email: {}".format(e), file=sys.stderr)except OSError
def character_frequency(filename):
"""Counts the frequency of each character in the given file."""
# First try to open the file
try:
f = open(filename)
except OSError:
return None
# Now process the file
characters = {}
for line in f:
for char in line:
characters[char] = characters.get(char, 0) + 1
f.close()
return charactersfinally
def calculate_average(numbers):
try:
return sum(numbers) / len(numbers)
except TypeError:
raise InvalidInputError(f"Expected a list or tuple, but got {type(numbers)}")
except ZeroDivisionError:
raise EmptyInputError("The list is empty. Cannot calculate the average.")
finally:
print("Execution of calculate_average function completed.")Raise
raise ValueError("Some custom error messages")
def validate_user(username, minlen):
assert type(username) == str, "username must be a string"
if minlen < 1:
raise ValueError("minlen must be at least 1")
if len(username) < minlen:
return False
if not username.isalnum():
return False
return TrueFor unit test
.assertRaises()
import unittest
from validations import validate_user
class TestValidateUser(unittest.TestCase):
def test_valid(self):
self.assertEqual(validate_user("validuser", 3), True)
def test_too_short(self):
self.assertEqual(validate_user("inv", 5), False)
def test_invalid_characters(self):
self.assertEqual(validate_user("invalid_user", 1), False)
def test_invalid_minlen(self):
self.assertRaises(ValueError, validate_user, "user", -1)
# Run the tests
unittest.main()- FileNotFoundError : The file might not exist
- IndexError : The file might not have enough lines of data
- ValueError : The data in the file might not be convertible to integers
- ZeroDivisionError : The second number might be zero
def enhanced_read_and_divide(filename):
try:
with open(filename, 'r') as file:
data = file.readlines()
# Ensure there are at least two lines in the file
if len(data) < 2:
raise ValueError("Not enough data in the file.")
num1 = int(data[0])
num2 = int(data[1])
# Check if second number is zero
if num2 == 0:
raise ZeroDivisionError("The denominator is zero.")
return num1 / num2
except FileNotFoundError:
return "Error: The file was not found."
except ValueError as ve:
return f"Value error: {ve}"
except ZeroDivisionError as zde:
return f"Division error: {zde}"Examples
User's emails
user_emails.csv :
Blossom Gill,blossom@abc.edu
Hayes Delgado,nonummy@abc.edu
Petra Jones,ac@abc.edu
Oleg Noel,noel@abc.edu
Ahmed Miller,ahmed.miller@abc.edu
Macaulay Douglas,mdouglas@abc.edu
Aurora Grant,enim.non@abc.edu
Madison Mcintosh,mcintosh@abc.edu
Montana Powell,montanap@abc.edu
Rogan Robinson,rr.robinson@abc.edu
Simon Rivera,sri@abc.edu
Benedict Pacheco,bpacheco@abc.edu
Maisie Hendrix,mai.hendrix@abc.edu
Xaviera Gould,xlg@abc.edu
Oren Rollins,oren@abc.edu
Flavia Santiago,flavia@abc.edu
Jackson Owens,jacksonowens@abc.edu
Britanni Humphrey,britanni@abc.edu
Kirk Nixon,kirknixon@abc.edu
Bree Campbell,breee@abc.eduemails.py : Main program
#!/usr/bin/env python3
import sys
import csv
def populate_dictionary(filename):
"""Populate a dictionary with name/email pairs for easy lookup."""
email_dict = {}
with open(filename) as csvfile:
lines = csv.reader(csvfile, delimiter = ',')
for row in lines:
name = str(row[0].lower())
email_dict[name] = row[1]
return email_dict
def find_email(argv):
""" Return an email address based on the username given."""
# Create the username based on the command line input.
try:
fullname = str(argv[1] + " " + argv[2])
# Preprocess the data
email_dict = populate_dictionary('/home/student/data/user_emails.csv')
# Find and print the email
if email_dict.get(fullname.lower()):
return email_dict.get(fullname.lower())
else:
return "No email address found"
except IndexError:
return "Missing parameters"
def main():
print(find_email(sys.argv))
if __name__ == "__main__":
main()emails_test.py : For unit test
#!/usr/bin/env python3
import unittest
from emails import find_email
class EmailsTest(unittest.TestCase):
def test_basic(self):
testcase = [None, "Bree", "Campbell"]
expected = "breee@abc.edu"
self.assertEqual(find_email(testcase), expected)
def test_one_name(self):
testcase = [None, "John"]
expected = "Missing parameters"
self.assertEqual(find_email(testcase), expected)
def test_two_name(self):
testcase = [None, "Roy", "Cooper"]
expected = "No email address found"
self.assertEqual(find_email(testcase), expected)
if __name__ == '__main__':
unittest.main()Binary Search
二分搜尋(Binary Search)是一種高效的搜尋演算法,用於在已排序的串列(List)中尋找特定元素的位置或值。
前提條件:
資料集合必須是已排序的,可以是升序或降序排列。這是因為二分搜尋利用了排序順序來有效地縮小搜索範圍。
步驟:
- 初始化左右邊界:將搜尋範圍的左邊界 left 設為 0,右邊界 right 設為資料集合的最後一個元素的索引。
- 重複以下步驟,直到左邊界 left 大於右邊界 right:
- 計算中間索引 mid,可以使用 mid = (left + right) // 2。
- 檢查中間元素 arr[mid] 與目標元素 target 的比較:
- 如果 arr[mid] 等於 target,則找到目標元素,返回 mid。
- 如果 arr[mid] 大於 target,則將右邊界 right 設為 mid - 1,縮小搜索範圍為左半部分。
- 如果 arr[mid] 小於 target,則將左邊界 left 設為 mid + 1,縮小搜索範圍為右半部分。
- 如果搜索範圍內找不到目標元素,則返回 -1,表示目標元素不存在於數列中。
特點:
- 二分搜尋是一種高效的搜尋演算法,因為它可以在每次迭代中將搜索範圍縮小一半,而不是線性搜索逐一檢查每個元素。
- 時間複雜度為 O(log n),其中 n 是資料集合中的元素數量。因此,二分搜尋適用於大型排序數列。
- 二分搜尋通常用於數列搜尋,但也可以應用於其他已排序的數據結構,如二叉搜尋樹。
二分搜尋是一個高效的搜尋演算法,特別適用於已排序的數列中尋找目標元素。它的主要優勢在於其快速的搜索速度,特別在大型資料集合中表現出色。
Example: Linear Search
def linear_search(list, key):
"""If key is in the list returns its position in the list,
otherwise returns -1."""
for i, item in enumerate(list):
if item == key:
return i
return -1Example: Binary Search
def binary_search(list, key):
"""Returns the position of key in the list if found, -1 otherwise.
List must be sorted.
"""
# Sort the List
list.sort() # 排序串列
left, right = 0, len(list) - 1 # 初始化左右邊界
while left <= right:
middle = (left + right) // 2 # 計算中間索引
if list[middle] == key:
return middle # 找到目標元素,傳回索引位置
if list[middle] > key:
right = middle - 1 # 調整右邊界值,縮小搜索範圍為左半部分
if list[middle] < key:
left = middle + 1 # 調整左邊界,縮小搜索範圍為右半部分
return -1 # 目標元素不存在於數列中,返回-1
# 測試
my_list = [2, 4, 7, 12, 15, 21, 30, 34, 42]
target_number = 15
result = binary_search(my_list, target_number)
if result != -1:
print(f"目標數字 {target_number} 存在於數列中,索引位置為 {result}")
else:
print(f"目標數字 {target_number} 不存在於數列中")Example2: Binary Search
def find_item(list, item):
#Returns True if the item is in the list, False if not.
if len(list) == 0:
return False
list.sort()
#Is the item in the center of the list?
middle = len(list)//2
if list[middle] == item:
return True
#Is the item in the first half of the list?
if item < list[middle]:
#Call the function with the first half of the list
return find_item(list[:middle], item)
else:
#Call the function with the second half of the list
return find_item(list[middle+1:], item)
return False
list_of_names = ["Parker", "Drew", "Cameron", "Logan", "Alex", "Chris", "Terry", "Jamie", "Jordan", "Taylor"]
print(find_item(list_of_names, "Alex")) # True
print(find_item(list_of_names, "Andrew")) # False
print(find_item(list_of_names, "Drew")) # True
print(find_item(list_of_names, "Jared")) # False使用案例
- 查找元素: 最常見的用途是在已排序的數列或列表中查找特定的元素。因為數據已經排序,所以你可以迅速縮小搜索範圍,從而實現快速查找。
- 字典或詞彙搜尋: 在字典或詞彙中查找單詞或詞彙時,可以使用二分搜尋,特別是當詞彙是按字母順序排列時。
- 庫存管理系統: 在庫存管理系統中,你可以使用二分搜尋來查找特定產品或物品的庫存信息。庫存項目通常按照產品編號或名稱排序。
- 數學方程求解: 在數學應用中,你可以使用二分搜尋來解方程或找到方程的根。通過不斷縮小可能的解的範圍,可以高效地找到解。
- 遊戲開發: 在遊戲中,你可以使用二分搜尋來實現各種功能,如查找玩家在排行榜中的位置、確定物體是否在特定範圍內等。
- 日曆應用: 在日曆應用中,你可以使用二分搜尋來查找特定日期,尤其是當日期已按日期順序排列時。
- 簡單排序: 雖然二分搜尋主要是一個搜尋演算法,但也可以在排序中使用。你可以使用二分搜尋來找到應該插入的位置,以實現插入排序。
- 音樂播放器: 在音樂播放器中,你可以使用二分搜尋來查找特定歌曲或歌手,特別是當音樂庫已按標題或藝術家名稱排序時。
- 路線規劃: 在地圖或路線規劃應用中,你可以使用二分搜尋來查找最接近的地點或路徑,以提高搜索速度。
Linear vs. Binary Search
def linear_search(list, key):
#Returns the number of steps to determine if key is in the list
#Initialize the counter of steps
steps=0
for i, item in enumerate(list):
steps += 1
if item == key:
break
return steps
def binary_search(list, key):
#Returns the number of steps to determine if key is in the list
#List must be sorted:
list.sort()
#The Sort was 1 step, so initialize the counter of steps to 1
steps=1
left = 0
right = len(list) - 1
while left <= right:
steps += 1
middle = (left + right) // 2
if list[middle] == key:
break
if list[middle] > key:
right = middle - 1
if list[middle] < key:
left = middle + 1
return steps
def best_search(list, key):
steps_linear = linear_search(list, key)
steps_binary = binary_search(list, key)
results = "Linear: " + str(steps_linear) + " steps, "
results += "Binary: " + str(steps_binary) + " steps. "
if (steps_linear < steps_binary):
results += "Best Search is Linear."
elif (steps_linear > steps_binary):
results += "Best Search is Binary."
else:
results += "Result is a Tie."
return results
print(best_search([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 1))
#Should be: Linear: 1 steps, Binary: 4 steps. Best Search is Linear.
print(best_search([10, 2, 9, 1, 7, 5, 3, 4, 6, 8], 1))
#Should be: Linear: 4 steps, Binary: 4 steps. Result is a Tie.
print(best_search([10, 9, 8, 7, 6, 5, 4, 3, 2, 1], 7))
#Should be: Linear: 4 steps, Binary: 5 steps. Best Search is Linear.
print(best_search([1, 3, 5, 7, 9, 10, 2, 4, 6, 8], 10))
#Should be: Linear: 6 steps, Binary: 5 steps. Best Search is Binary.
print(best_search([5, 1, 8, 2, 4, 10, 7, 6, 3, 9], 11))
#Should be: Linear: 10 steps, Binary: 5 steps. Best Search is Binary.
Debug
Debugging
assert
- 主要用在開發與測試階段
- 可用在程式的條件測試
assert <condition>, <message>: 如果 condition 為 True,沒有作用;如果為 False,會產生錯誤,並顯示訊息- 跳過所有
assert語句,可以使用python -O sample.py。
檢查變數的值
x = 5
assert x == 5, "x should be 5"
assert type(username) == str, "username must be a string"def calculate_square_root(x):
assert x >= 0, "The input must be non-negative."
return x ** 0.5
print(calculate_square_root(4)) # 輸出: 2.0
print(calculate_square_root(-1)) # 引發 AssertionError 並顯示 "The input must be non-negative."檢查函示回傳值有無偶數
def get_even_number(numbers):
for num in numbers:
if num % 2 == 0:
return num
assert False, "No even number found in the list."
numbers = [1, 3, 5, 7, 10]
print(get_even_number(numbers)) # 輸出: 10
numbers = [1, 3, 5, 7]
print(get_even_number(numbers)) # 引發 AssertionError 並顯示 "No even number found in the list."
prinf debugging
print("Processing {}".format(basename))strace
# Installation on RHEL if it's not installed
yum install strace
# Tracing system calls made by a program
strace ./my-program.py
strace -o my-program.strace ./my-programCrash
pdb
功能:
- 設定程式中斷點
- 逐行檢查程式碼
- 檢查變數
- 以互動方式評估表達式
pdb3 myprog.pypdb-subcommands
- continue : 繼續執行直到異常的程式碼
- print() : 輸出變數的內容
(Pdb) continue
...
(Pdb) print(row)Step 1: Set a breakpoint
import pdb
def add_numbers(a, b):
pdb.set_trace() # This will set a breakpoint in the code
result = a + b
return result
print(add_numbers(3, 4))Setp 2: Enter the interactive debugger
-
a (args): Show the arguments of the current function.
-
b: Manually set a persistent breakpoint while in debugger.
-
n (next): Execute the next line within the current function.
-
s (step): Execute the current line and stop at the first possible occasion (e.g., in a function that is called).
-
c (continue): Resume normal execution until the next breakpoint.
-
p (print): Evaluate and print the expression, e.g., p variable_name will print the value of variable_name.
-
Pp (pretty-print): Pretty-print the value of the expression.
-
q (quit): Exit the debugger and terminate the program.
-
r (return): Continue execution until the current function returns.
-
tbreak: Manually set a temporary breakpoint that goes away once hit the first time.
-
!: Prefix to execute an arbitrary Python command in the current environment, e.g., !variable_name = "new_value" will set variable_name to "new_value".
Step 3: Inspect variables
To inspect the variables, simply type the single character, p, then the variable name to see its current value. For instance, if you have a variable in your code named sentiment_score, just type p sentiment_score at the pdb prompt to inspect its value.
Step 4: Modify variables
A big advantage of pdb is that you can change the value of a variable directly in the debugger. For example, to change sentiment_score to 0.9, you'd type !sentiment_score = 0.9.
To confirm these changes, use a or directly probe the value with p <value name>.
Step 5: Exit the debugger
When you’re done, simply enter q (quit) to exit the debugger and terminate the program.
Post-mortem debugging
python -m pdb your_script.pyMemory Leaks
當不再需要的記憶體未釋放時,就會發生記憶體洩漏。即使重新啟動,仍需要大量記憶體的應用程式,很可能指向記憶體洩漏
memory_profiler
第一欄顯示每一行執行時所需的記憶體數量。第二欄顯示每一行所增加的記憶體
python3 -m memory_profiler myprog.pyIn Code
- 在
main()上方加上@profile標籤 - @ 標籤稱為 Decorator: 在 Python 中使用它來為函數增加額外的行為,而不需要修改程式碼
- memory-profiler
from memory_profiler import profile
...
...
@profile
def main():
...
...
Python Virtual Environment
Tutorials
uv
- 用途: 套件 + 虛擬環境的管理工具
- 官網: uv
- 安裝不需要 root 權限
- 單一 uv 指令可以取代 pip, pip-tools, pipx, poetry, pyenv, twine, virtualenv 等指令
# Install with curl or wget
curl -LsSf https://astral.sh/uv/install.sh | sh
wget -qO- https://astral.sh/uv/install.sh | sh
# Instal with pip
pip install uv# To install the latest Python version:
uv python install
# To install a specific Python version:
uv python install 3.12
# To reinstall uv-managed Python versions
uv python install --reinstall
# To view available and installed Python versions:
uv python list
uv python list --managed-python
uv python list --no-managed-python# Crerate a new project
uv init hello-world
cd hello-world
# Alternatively, you can initialize a project in the working directory:
mkdir hello-world
cd hello-world
uv init
# Create virtual environment
uv venv
# Or
uv venv --python=3.12 .venv
# Activate
source .venv/bin/activate
# Exit the VENV
deactivate# Add a package
uv add requests
uv add 'requests==2.31.0'
# Add all dependencies from `requirements.txt`.
uv add -r requirements.txt
# To remove a package
uv remove requests其他人或在異地需要執行專案
git clone https://path/to/your/project/yourepo.git
cd yourepo/
uv venv # 建立虛擬環境
source .venv/bin/activate # 啟動虛擬環境
uv sync # 根據專案的 pyproject.toml + uv.lock 安裝所有相依性套件Pixi
Miniconda
# Install
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm ~/miniconda3/miniconda.sh
# Post-Install
source ~/miniconda3/bin/activate
conda init --all
# Verify
conda list
conda --version
# Optional: Uninstall
conda deactivate
~/miniconda3/uninstall.shConda
# Create a virtual env
conda create -n myproj python=3.11
# Activate the virtual env
conda activate myproj
# Deactivate the virtual env
conda deactivatePython 3.4+ built-in venv
# Install venv
sudo apt install python3-venv
# Enable venv
mkdir myproject
cd myproject
python -m venv .venv
# Activate the venv
source .venv/bin/activate
# Delete the venv
deactivate
rm -rf .venv
# Change the App directory after activating venv
cd /path/to
mv old new
cd new/.venv/bin
old_path="/path/to/old/.venv"
new_path="/path/to/new/.venv"
find ./ -type f -exec sed -i "s|$old_path|$new_path|g" {} \;
cd /path/to/new
source .venv/bin/activatevirtualenv and virtualenvwrapper
# Installing virtualenv and virtualenvwrapper
sudo pip install virtualenv virtualenvwrapper
# Update the profile ~/.bashrc
# Add the following lines
# Python virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
# Reload the profile
source ~/.bashrc
# Creating python virtual environment
# The py3cv3 is a self-defined name
mkvirtualenv py3cv3 -p python3
# Enter the specified virtual environment
workon py3cv3
# Exit the the specified virtual environment
deactivate
# List all of the environments.
lsvirtualenv
# Remove an environment
rmvirtualenv py3cv3Custom Setup.py
為自己的專案訂製一個 setup.py 安裝程序
Commands
Install all dependencies
cd <your-repo>
pip install -e .
Sample codes
FastAPI
Getting Started
Introduction
FastAPI is a modern, high-performance web framework for building APIs using Python. Designed with efficiency and developer productivity in mind, it takes full advantage of Python’s type hints to provide automatic validation, serialization, and robust error handling. FastAPI is particularly well-suited for building RESTful APIs, microservices, and backend services for real-time applications.
Core Features
- Asynchronous Programming
- Automatic Interactive API Documentation
- Type-Driven Development
- Data Validation with Pydantic
- Built-in Dependency Injection
- Security and Authentication
Tutorials
Official: FastAPI
PyImageSearch
- Getting Started with Python and FastAPI: A Complete Beginner’s Guide - PyImageSearch
- Deploying a Vision Transformer Deep Learning Model with FastAPI in Python - PyImageSearch
- Preparing FastAPI for Production: A Comprehensive Guide | by Raman Bazhanau | Medium
Getting Started
Installation
- Installs FastAPI, the framework we’ll use to build our APIs.
- Installs Uvicorn, the Asynchronous Server Gateway Interface (ASGI) that will run the FastAPI app and serve it to clients.
- Installs PyTest, a testing framework that allows us to write and run test cases for our FastAPI endpoints efficiently.
pip install fastapi uvicorn pytestVerify the installation
python -m uvicorn --helpRunning a Basic Server
main.py: (NOTE: 檔名不能與專案名相同,例如 fastapi.py)
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def read_root():
return {"message": "Hello, World!"}Command to start the API Server
uvicorn main:app --reloadAccess the Application : http://127.0.0.1:8000/
Example Code
Quick Test
from fastapi import FastAPI, File, UploadFile, HTTPException
app = FastAPI()
# http://127.0.0.1:8000/
@app.get("/")
async def read_root():
return {"message": "Hello, World!"}
# http://127.0.0.1:8000/square?num=3
@app.get("/square")
async def calculate_square(num: int):
return {"number": num, "square": num ** 2}
# http://127.0.0.1:8000/users/123
@app.get("/users/{user_id}")
async def read_user(user_id: int):
return {"user_id": user_id}Constraint/Validation
Pyantic: Base Constraint
from pydantic import BaseModel, Field
class User(BaseModel):
name: str = Field(..., max_length=50)
age: int = Field(..., gt=0, le=100)
email: str = Field(..., regex="^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$")Pyantic: Custom Error Messages
from pydantic import BaseModel, Field
class User(BaseModel):
name: str = Field(..., max_length=50, description="Name must be under 50 characters")
age: int = Field(..., gt=0, le=100, description="Age must be between 1 and 100")
email: str = Field(..., regex="^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$", description="Invalid email format")Pyantic: Combining Multiple Constraints
from pydantic import BaseModel, Field
class User(BaseModel):
username: str = Field(..., min_length=3, max_length=20, regex="^[a-zA-Z0-9_.]+$")Pyantic: Integration with FastAPI Endpoints
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
app = FastAPI()
class User(BaseModel):
name: str = Field(..., max_length=50)
age: int = Field(..., gt=0, le=100)
email: str = Field(..., regex="^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$")
@app.post("/user/")
async def create_user(user: User):
return userUpload File
Tutorials
Installation
pip install fastapi uvicorn python-multipartQuick Test
# curl -X POST "http://127.0.0.1:8000/uploadfile/" -H "accept: application/json" -H "Content-Type:multipart/form-data" -F "file=@your.pdf"
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile | None = None):
if not file:
return {"message": "No upload file sent"}
else:
return {"filename": file.filename}
@app.post("/tempfile/")
async def temp_file(file: UploadFile | None = None):
with tempfile.NamedTemporaryFile(delete=False) as temp_file:
content = await file.read()
temp_file.write(content)
temp_file.close
return {"filepath": temp_file.name, "filename": file.filename, "content_type": file.content_type, "size": file.size}Client Test with curl
curl -X POST "http://127.0.0.1:8000/uploadfile/" -H "accept: application/json" -H "Content-Type:multipart/form-data" -F "file=@/path/to/your.pdf"Upload single file
from fastapi import FastAPI, File, UploadFile, HTTPException
from fastapi.responses import JSONResponse
from typing import List
import os
import shutil
from pathlib import Path
# Create upload directory
UPLOAD_DIR = Path("uploads")
UPLOAD_DIR.mkdir(exist_ok=True)
app = FastAPI(title="FastAPI File Upload Service")
@app.post("/upload/single")
async def upload_single_file(file: UploadFile = File(...)):
"""Upload a single file with basic validation"""
if file.filename == "":
raise HTTPException(status_code=400, detail="No file selected")
file_path = UPLOAD_DIR / file.filename
with open(file_path, "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
return {
"filename": file.filename,
"content_type": file.content_type,
"size": file.size,
"location": str(file_path)
}With validations
validators.py:
from pathlib import Path
from fastapi import UploadFile
class DocumentValidator:
def __init__(self, max_size: int = 10 * 1024 * 1024): # 10MB default
self.max_size = max_size
self.allowed_extensions = {'.pdf', '.txt', '.json'}
async def validate_file(self, file: UploadFile) -> dict:
"""Check if the document file is valid"""
result = {"valid": True, "errors": []}
# Check if user selected a file
if not file.filename or file.filename.strip() == "":
result["valid"] = False
result["errors"].append("No file selected")
return result
# Check file extension
file_ext = Path(file.filename).suffix.lower()
if file_ext not in self.allowed_extensions:
result["valid"] = False
result["errors"].append(
f"File extension '{file_ext}' not allowed. Use: .pdf, .txt, or .json"
)
# Read file to check size
content = await file.read()
await file.seek(0) # Reset file pointer for later use
# Check file size
file_size = len(content)
if file_size > self.max_size:
result["valid"] = False
result["errors"].append(
f"File too large ({file_size:,} bytes). Maximum: {self.max_size:,} bytes"
)
return resultmain.py
from fastapi import FastAPI, File, UploadFile, HTTPException
from fastapi.responses import JSONResponse
from typing import List
import os
import shutil
import uuid
from pathlib import Path
from datetime import datetime
from validators import DocumentValidator
# Create upload directory
UPLOAD_DIR = Path("uploads")
UPLOAD_DIR.mkdir(exist_ok=True)
app = FastAPI(title="FastAPI File Upload Service")
# Create validator instance
doc_validator = DocumentValidator(max_size=25 * 1024 * 1024) # 25MB limit
@app.post("/upload/single")
async def upload_single_file(file: UploadFile = File(...)):
"""Upload a single file with validation"""
# Validate the file first
validation = await doc_validator.validate_file(file)
if not validation["valid"]:
raise HTTPException(
status_code=400,
detail={
"message": "File validation failed",
"errors": validation["errors"]
}
)
# Create unique filename to prevent conflicts
file_ext = Path(file.filename).suffix
unique_filename = f"{uuid.uuid4()}{file_ext}"
file_path = UPLOAD_DIR / unique_filename
try:
with open(file_path, "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
except Exception as e:
raise HTTPException(
status_code=500,
detail=f"Failed to save file: {str(e)}"
)
return {
"success": True,
"original_filename": file.filename,
"stored_filename": unique_filename,
"content_type": file.content_type,
"size": file.size,
"upload_time": datetime.utcnow().isoformat(),
"location": str(file_path)
}
@app.get("/")
async def root():
return {"message": "FastAPI File Upload Service is running"}Deployment
Tutorials
Authentication
Tutorials
Basic Authentication
auth.py
import secrets
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import HTTPBasic, HTTPBasicCredentials
security = HTTPBasic()
def authenticate_user(credentials: HTTPBasicCredentials = Depends(security)):
# In a real application, you'd verify against a database
correct_username = secrets.compare_digest(credentials.username, "admin")
correct_password = secrets.compare_digest(credentials.password, "secret")
if not (correct_username and correct_password):
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid credentials",
headers={"WWW-Authenticate": "Basic"},
)
return credentials.usernamemain.py
from fastapi import FastAPI, Depends
from auth import authenticate_user
app = FastAPI(title="Authentication Demo", version="1.0.0")
@app.get("/")
async def root():
return {"message": "Welcome to FastAPI Authentication Demo"}
@app.get("/protected")
async def protected_route(current_user: str = Depends(authenticate_user)):
return {"message": f"Hello {current_user}, this is a protected route!"}Example: Internet Speed Tacker
Prerequisites
sudo apt install speedtest-cliinternet_speed_tracker.py
#!/usr/bin/env python3
import subprocess
import csv
import os
from datetime import datetime
#--------------CONFIGURATIONs--------------
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
LOG_FILE = os.path.join(BASE_DIR, "speed_log.csv")
def run_speed_test():
try:
# Run speedtest in simple mode
result = subprocess.check_output(["speedtest-cli", "--simple"]).decode("utf-8")
# These settings parse the text. For example: Ping: 20 ms, Download: 50.5 Mbit/s, etc
lines = result.split('\n')
ping = lines[0].split()[1]
download = lines[1].split()[1]
upload = lines[2].split()[1]
return ping, download, upload
#These settings keep Speedtest from crashing by logging zeroes when the internet is totally down
except Exception:
return "0", "0", "0"
def main():
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
ping, download, upload = run_speed_test()
# Check if file exists to add headers if it doesn't
file_exists = os.path.isfile(LOG_FILE)
with open(LOG_FILE, mode='a', newline='') as f:
writer = csv.writer(f)
if not file_exists:
writer.writerow(["Timestamp", "Ping (ms)", "Download (Mbit/s)", "Upload (Mbit/s)"])
writer.writerow([timestamp, ping, download, upload])
if __name__ == "__main__":
main()Configure systemd
/etc/systemd/system/internet-speed-tracker.service
[Service]
ExecStart=/usr/bin/python3 "home/alang/internet_speed_tracker.py"
User=alang/etc/systemd/system/internet-speed-tracker.timer
[Timer]
OnBootSec=5min
OnUnitActiveSec=2min
Persistent=true
[Install]
WantedBy=timers.targetStart the service
sudo systemctl daemon-reload
sudo systemctl enable --now internet-speed-tracker.timer
Flask API
Tutorials
Basic Example
from flask import Flask
import subprocess
app = Flask(__name__)
@app.route('/pull-repo', methods=['POST'])
def pull_repo():
try:
# Fetch the latest changes from the remote repository
subprocess.run(["git", "-C", "/path/to/your/repository", "fetch"], check=True)
# Force reset the local branch to match the remote 'test' branch
subprocess.run(["git", "-C", "/path/to/your/repository", "reset", "--hard", "origin/test"], check=True) # Replace 'test' with your branch name
return "Force pull successful", 200
except subprocess.CalledProcessError:
return "Failed to force pull the repository", 500
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)