SHELL
- 範例與常用技巧
- grep
- test
- awk
- sed
- Sample Scripts
- Regex 正規表示式
- 管理與操作
- Function Examples
- dialog
- Array 陣列
- Learning SHELL
- String Manipulation 字串處理
- loop
- 進度條 progress bar
- find
- uniq
- date
- Parallel and Multi-thread
- Perl
- lsof
- 算術
- Diagrams
- ANSI Color
- Cheat Sheets
範例與常用技巧
檔頭常用宣告
# quickly syntax
set -euo pipefail
# let script exit if a command fails
set -o errexit
# OR
set -e
# let script exit if an unsed variable is used
set -o nounset
# OR
set -u
# This setting prevents errors in a pipeline from being masked.
set -o pipefail
# for Debug
set -x
# setting IFS
IFS=$'\n\t'How set -o pipefail works
$ grep some-string /non/existent/file | sort
grep: /non/existent/file: No such file or directory
$ echo $?
0
$ set -o pipefail
$ grep some-string /non/existent/file | sort
grep: /non/existent/file: No such file or directory
$ echo $?
2How the IFS works
#!/bin/bash
names=(
"Aaron Maxwell"
"Wayne Gretzky"
"David Beckham"
"Anderson da Silva"
)
echo "With default IFS value..."
for name in ${names[@]}; do
echo "$name"
done
echo ""
echo "With strict-mode IFS value..."
IFS=$'\n\t'
for name in ${names[@]}; do
echo "$name"
done
############### Output #############
With default IFS value...
Aaron
Maxwell
Wayne
Gretzky
David
Beckham
Anderson
da
Silva
With strict-mode IFS value...
Aaron Maxwell
Wayne Gretzky
David Beckham
Anderson da Silva檔案的目錄位置
# 指定的檔案
readlink -f <file.name>
# 目前檔案
WORKDIR=$(readlink -f "$0") ;目前檔案的絕對路經
WORKDIR=$( cd $( dirname "$0" ) && pwd )Script 檔案名稱
$ echo $0
./test.sh
$ echo `basename $0`
test.sh 輸出多行的文字訊息
cat <<EOF
Welcome .....
Here are the messages that you want to show up
EOF所有輸出訊息導入一個檔案
Sample #1
#!/bin/sh
LOG="my.log"
(
....
) 2>&1 | tee -a $LOG 不適用在內容裡有 python 指令的訊息輸入,輸入等待的畫面會無法顯示。
Sample #2
temp=$(mktemp)
exec &> ${temp}
echo "All outputs will be saved into the file ${temp}."Sample #3
#!/bin/bash
set -eu
exec 3>&1 4>&2
trap 'exec 2>&4 1>&3' 0 1 2 3
exec 1>/path/to/script.log 2>&1
# rest of the script below
dnf -y in foo bar
# firewall rules goes here
....
...快速修改大量檔案的副檔名
## *.old -> *.new
for fname in $(ls *.old);do echo "mv $fname ->"; echo $(echo $fname |sed 's/.old/.new/');mv $fname $(echo $fname | sed 's/.old/.new/');done快速新增或列出多個指定目錄
mkdir {AAA,BBB,CCC}快速備份設定檔
cp my.cfg{,.bak}計算檔案總數量
用 find
# 計算目前目錄底下所有檔案數
find . -type f | wc -l
# 計算第一層所有子目錄的檔案數並排序清單
find . -maxdepth 1 -type d -print0 | xargs -0 -I {} sh -c 'echo $(find {} -type f | wc -l) {}' | sort -n
NOTE: 第一層子目錄名稱不可包含空格 用 rsync
rsync --stats --dry-run -ax /usr /tmp
Number of files: 326,373 (reg: 211,698, dir: 24,284, link: 90,391)
Number of created files: 326,373 (reg: 211,698, dir: 24,284, link: 90,391)
Number of deleted files: 0
Number of regular files transferred: 211,698
Total file size: 7,180,685,730 bytes
Total transferred file size: 7,178,524,818 bytes
NOTE: 這指令實際不會作檔案複製,/tmp 只是一個假目錄,回傳結果是 reg: 211698 就是檔案總數用 tree
tree /mydir -a | tail -n 1
5 directories, 56 files
NOTE: 當目錄底下有包含 symbolic link 也會被計算執行外部 SHELL 或指令
1. 使用 pipe line
echo"md5sum $X > $X.sum "| bash2. 使用 eval
get_arch="uname -p"
if [ "`eval "$get_arch"`" = "i686" ]; then
....
fi 線上執行 Shell
bash <(curl -fsSL https://raw.githubusercontent.com/IT-BAER/proxmorph/main/install.sh) install提示字元的路徑名稱太長
加上這變數
PROMPT_DIRTRIM=2處理 CSV 檔
- Doing a database join with CSV files
- tvs-utils - eBay's TSV Utilities: Command line tools for large, tabular data files. Filtering, statistics, sampling, joins and more.
- How To Parse CSV Files In Bash Scripts In Linux
- How to convert JSON to CSV using Linux / Unix shell
#!/bin/bash
INPUT=data.cvs
OLDIFS=$IFS
IFS=','
[ ! -f $INPUT ] && { echo "$INPUT file not found"; exit 99; }
while read flname dob ssn tel status
do
echo "Name : $flname"
echo "DOB : $dob"
echo "SSN : $ssn"
echo "Telephone : $tel"
echo "Status : $status"
done < $INPUT
IFS=$OLDIFSCSV and JSON
# JSON to CSV
cat df.json | jq -r '.[]| join(",")'
cat bingbot.json | jq -r '.prefixes[] | {cidr: .ipv4Prefix, comment: "BingBot"} | join(",")' > bingbot.csv
JSON 檔
- [GitHub] gron - Make JSON greppable!
建立暫存檔
tmpfile1=$(mktemp)
tmpfile2="/tmp/$(basename $0).$$.tmp"Get my public IP
curl ifconfig.me
curl ifconfig.me/ip
curl ifconfig.co
curl checkip.amazonaws.com
curl icanhazip.com
curl ipecho.net/plain
dig +short myip.opendns.com @resolver1.opendns.com
dig TXT +short o-o.myaddr.l.google.com @ns1.google.com
dig TXT +short o-o.myaddr.l.google.com @ns1.google.com | awk -F'"' '{print $2}'主機 IP
# On Linux
hostname -I
hostip=$(/sbin/ip a | awk '/eth[012]:|ens192:|bond0:/,/^$/' | grep -E "inet [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}" | head -1 | awk -F " " '{print $2}' | cut -d"/" -f1)
# On AIX
hostip=$( ifconfig -a | grep inet | awk '{print $2}' | head -1 )
hostip=$( ifconfig -a | grep inet | awk '{print $2}' | sed -n '/\([0-9]\{1,3\}\.\)\{3\}[0-9]\{1,3\}/p' | head -1 )找出最大的目錄或檔案
# Way 1
du -a /var | sort -n -r | head -n 10
# Way 2
cd /path/to/some/where
du -hsx * | sort -rh | head -10
du -hsx -- * | sort -rh | head -10
# Way 3
find /path/to/dir/ -printf '%s %p\n'| sort -nr | head -10
find . -printf '%s %p\n'| sort -nr | head -10
## Skip directories and only display files
find /path/to/search/ -type f -printf '%s %p\n'| sort -nr | head -10
# Create a shell alias
## shell alias ##
alias ducks='du -cks * | sort -rn | head'
## deal with special files names ##
alias ducks='du -cks -- * | sort -rn | head'檔名移除空白字元
# With tr
for f in *; do mv "$f" `echo $f | tr ' ' '_'`; done
# With find
find . -type f -name "* *.xml" -exec bash -c 'mv "$0" "${0// /_}"' {} \;read
輸入密碼
echo -n "MySQL username: " ; read username
echo -n "MySQL password: " ; stty -echo ; read password ; stty echo ; echoYes/No
while true; do
echo "The Server IP is $serverip"
read -p "Are you sure that you want to continue? (y/N): " input
input=${input:-n}
case "$input" in
y|Y)
echo
break
;;
n|N)
echo "Exit"
exit 1
;;
*) echo "Please answer Y or N.";;
esac
doneshuf: 隨機排序
curl -s https://www.imdb.com/list/ls020046354/export | cut -d ',' -f 6 | shuftree: 顯示專案目錄的檔案樹
tree --dirsfirst --filelimit 10 --sort=name
# Display size of files
tree -s
# Display permissions of files
tree -p
# Display directory only
tree -d
# Display till a certain level/depth
tree -L 1
# List only those files that match pattern given
tree -P *screenshot*sort : 資料排序
sort -t ',' -k5,5 -k1,1 -k9,9 -k3,3 -k11,11 my.csv- -t 分隔符號
- -k5,5 排序第 5 欄,以字串類型排列
- 欄位排序先後依序為第 5, 1, 9, 3, 11 欄
- 欄位排序若要以數值方式來排,改成 -k5,5n
timeout : 自動停止執行
timeout 10 tail -f /var/log/httpd/access.log
timeout 5m ping 8.8.8.8
timeout 300 tcpdump -n -w data.pcap
# Sending specific signal
# To get a list of all available signals, use the command kill -l .
timeout -s SIGKILL ping 8.8.8.8variables : 變數
| 變數 | 說明 |
| $0 | 腳本檔名 |
| $1 | 第1個參數 |
| $2 | 第2個參數 |
| ${10} | 第10個參數 #10 |
| $# | 參數的個數 |
| $* | 顯示所有參數 (作為一個字串) |
| $@ | 顯示所有參數 (每個為一個獨立字串) |
| ${$*} | 傳遞到腳本中的參數的個數 |
| ${$@} | 傳遞到腳本中的參數的個數 |
| $? | 腳本結束後的傳回值 |
| $$ | 腳本的程序 ID |
| $_ | 前個命令的最後一個參數 |
| $! | 最後一個執行程序的 ID |
| u=${1:-root} | 如果 $1 未指定,就賦予值 root |
| u=${USER:-foo} | 如果 $USER 未指定,就賦予值 foo |
| len=${#var} | 計算 $var 字串的長度 |
如果 $2 未指定或空值,輸出錯誤訊息
${varName?Error varName is not defined}
${varName:?Error varName is not defined or is empty}建立目錄並且切換至目錄
mkdir my-dir && cd $_cut: 切割文字
# AAA = BBB, 取出 BBB
cut -d= -f2
# 111 2222 33 444444 555, 取出 33 以後的所有內容
cut -d ' ' -f3-
# 檢視超長的文字
head -n 1 data.csv | wc # 計算行的字元數
head data.csv | cut -c -30 # 列出前幾行的前 30 個字元, 如果要顯示後 30 個字元,可以用 30-tr: 置換
# aaa bbb ccc
# 換成
# aaa
# bbb
# ccc
echo "aaa bbb ccc" | tr " " "\n"xargs
接入(Pipe) 不支援 stdin 指令的替代方法
printf: 格式化輸出
- %s 字串
- %d 整數
printf "%-40s ..................%s\n" "Disable the service $1" "[$2]"
Disable the service apmd ..................[OK]
Disable the service bluetooth ..................[OK]
Disable the service hidd ..................[OK]
Disable the service cups ..................[OK]
Disable the service firstboot ..................[OK]
Disable the service readahead_early ..................[OK]
printf "%40s ..................%s\n" "Disable the service $1" "[$2]"
Disable the service apmd ..................[OK]
Disable the service bluetooth ..................[OK]
Disable the service hidd ..................[OK]
Disable the service cups ..................[OK]
Disable the service firstboot ..................[OK]
Disable the service readahead_early ..................[OK] 數字四捨五入
printf "%.0f" 9.46666667 # output: 10
printf "%.2f" 9.46666667 # output: 9.47表格式輸出
line="--------------------------------------------------"
printf "+-%.10s-+-%.5s-+-%.6s-+\n" "$line" "$line" "$line"
printf "| %-10s | %-5s | %-6s |\n" "DATE" "CALLS" "ASR(%)"
printf "+-%.10s-+-%.5s-+-%.6s-+\n" "$line" "$line" "$line"
printf "| %.10s | %5d | %.2f | %s\n" "$day" $calls $asr "$flag"
+------------+-------+--------+
| DATE | CALLS | ASR(%) |
+------------+-------+--------+
| 2025-07-10 | 1442 | 97.57 |
| 2025-07-11 | 1266 | 96.99 |
| 2025-07-12 | 1162 | 97.24 |
| 2025-07-13 | 949 | 96.62 |
| 2025-07-14 | 1178 | 98.13 |
| 2025-07-15 | 1665 | 97.05 |
| 2025-07-16 | 1163 | 87.61 |
+------------+-------+--------+
#/bin/bash
seperator=--------------------
seperator=$seperator$seperator
rows="%-15s| %.7d| %3d| %c\n"
TableWidth=37
printf "%-15s| %-7s| %.3s| %s\n" Name ID Age Grades
printf "%.${TableWidth}s\n" "$seperator"
printf "$rows" "Sherlock Holmes" 122 23 A
printf "$rows" "James Bond" 7 27 F
printf "$rows" "Hercules Poirot" 6811 59 G
printf "$rows" "Jane Marple" 1234567 71 C
Name | ID | Age| Grades
-------------------------------------
Sherlock Holmes| 0000122| 23| A
James Bond | 0000007| 27| F
Hercules Poirot| 0006811| 59| G
Jane Marple | 1234567| 71| C印出一個長符號
printf -- '-%.0s' {1..80}
printf -- '=%.0s' {1..80}ping: 掃描一個 IP 範圍
{ for p in {1..254}; do ping -c1 -w1 10.22.9.$p & done } | grep "64 bytes"nice: Reduce CPU and Disk load of backup scripts
# Reduce the I/O priority of the /usr/local/bin/backup.sh script so that it does not interfere with other processes
# The -n parameter must be between 0 and 7, where lower numbers mean higher priority
/usr/bin/ionice -c2 -n7 /usr/local/bin/backup.sh
# To reduce the CPU priority, use the command nice
# The -n parameter can range from -20 to 19, where lower numbers mean higher priority
/usr/bin/nice -n 19 /usr/local/bin/backup.sh
# Nice and ionice can also be combined, to run a script at low I/O and CPU priority
/usr/bin/nice -n 19 /usr/bin/ionice -c2 -n7 /usr/local/bin/backup.shHex to ASCII
# hex = 54657374696e672031203220330
# ascii = Testing 1 2 3
# xxd
echo 54657374696e672031203220330 | xxd -r -p && echo ''
# printf
printf '\x54\x65\x73\x74\x69\x6e\x67\x20\x31\x20\x32\x20\x33\x0' && echo ''
# sed
echo -n 54657374696e67203120322033 | sed 's/\([0-9A-F]\{2\}\)/\\\\\\x\1/gI' | xargs printf && echo ''隨機密碼生成
genpasswd() {
local l=$1
[ "$l" == "" ] && l=16
tr -dc A-Za-z0-9_ < /dev/urandom | head -c ${l} | xargs
}tr -dc A-Za-z0-9_ < /dev/urandom | head -c 16 | xargs
# Generate more than one
tr -dc A-Za-z0-9_ < /dev/urandom | fold -16 | head -5
#
echo FooBar$RANDOM | md5sum | base64 | cut -c 1-12ls: 進階技巧
# Find the biggest zip file
ls -lSrh ~/Downloads/*.zipstat: 檔案屬性
❯ stat --printf='Name: %n\nPermissions: %a\n' my.log
Name: my.log
Permissions: 777
❯ stat --format="%F" my.log
regular file
# Symlink
❯ stat ~/bin/FoxitReader
File: /home/alang/bin/FoxitReader -> /home/alang/opt/foxitsoftware/foxitreader/FoxitReader.sh
Size: 56 Blocks: 0 IO Block: 4096 symbolic link
Device: 10302h/66306d Inode: 787474 Links: 1
Access: (0777/lrwxrwxrwx) Uid: ( 1000/ alang) Gid: ( 1000/ alang)
Access: 2023-07-16 10:26:13.412193581 +0800
Modify: 2023-02-26 12:13:50.234374171 +0800
Change: 2023-02-26 12:13:50.234374171 +0800
Birth: 2023-02-26 12:13:50.234374171 +0800
❯ stat -L ~/bin/FoxitReader
File: /home/alang/bin/FoxitReader
Size: 120 Blocks: 8 IO Block: 4096 regular file
Device: 10302h/66306d Inode: 1457222 Links: 1
Access: (0755/-rwxr-xr-x) Uid: ( 1000/ alang) Gid: ( 1000/ alang)
Access: 2023-07-02 14:34:09.957428285 +0800
Modify: 2023-02-26 12:13:50.246374250 +0800
Change: 2023-02-26 12:13:50.246374250 +0800
Birth: 2023-02-26 12:13:48.530362986 +0800less: 進階技巧
顯示有包含色碼的內容
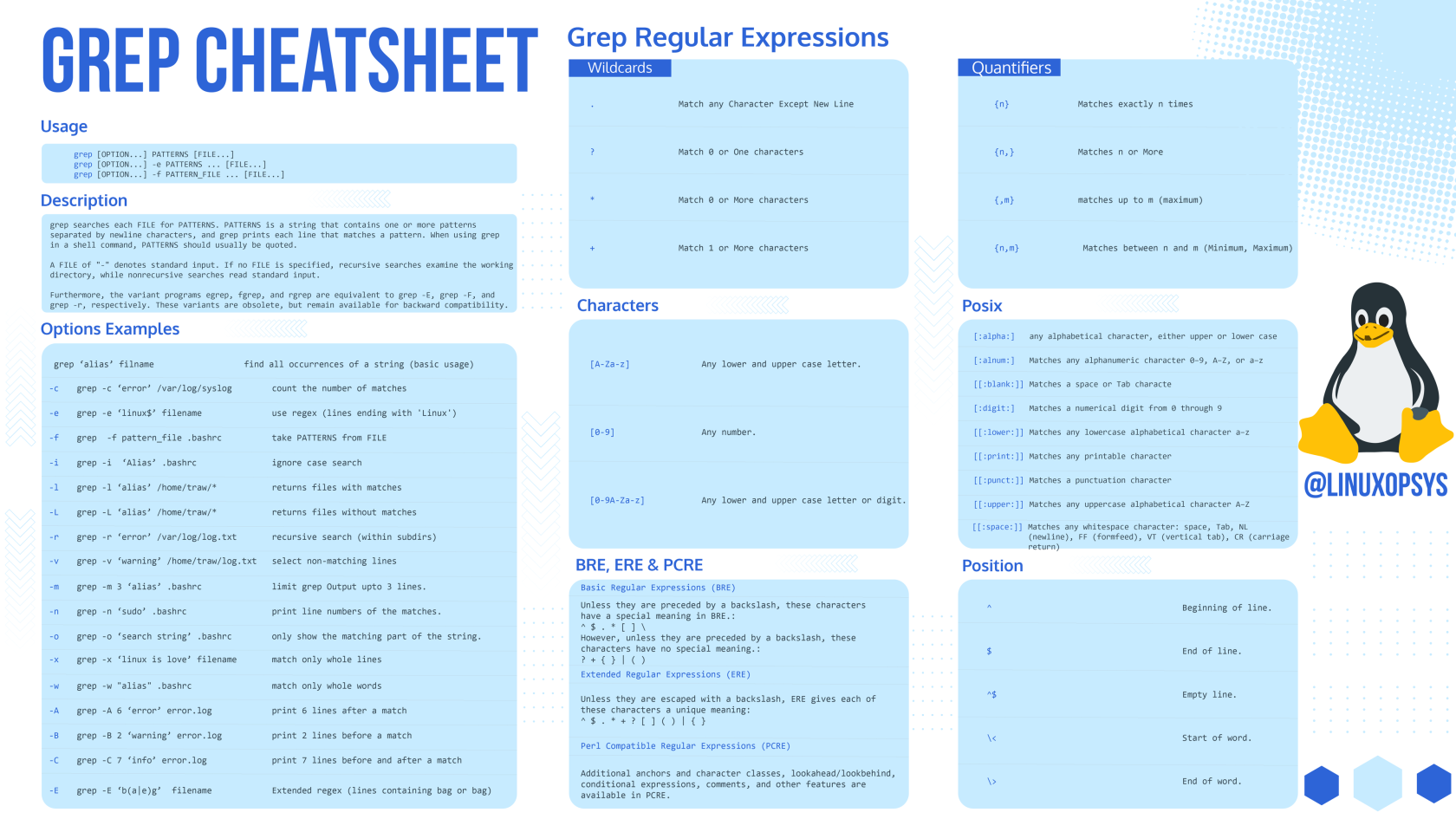
less -r yourfilegrep
教學網站
- http://www.cyberciti.biz/faq/grep-regular-expressions/
- https://www.ubuntupit.com/practical-grep-command-for-linux-enthusiasts/
文字過濾
# 使用 . (period) 表示一個任意字元
> grep dev.sda /etc/fstab
/dev/sda3 / reiserfs noatime,ro 1 1
/dev/sda1 /boot reiserfs noauto,noatime,notail 1 2
/dev/sda2 swap swap sw 0 0
#/dev/sda4 /mnt/extra reiserfs noatime,rw 1 1
# 使用 [ ]
> grep dev.sda[12] /etc/fstab
/dev/sda1 /boot reiserfs noauto,noatime,notail 1 2
/dev/sda2 swap swap sw 0 0
# 使用 [^12] 表示非1,2字元
> grep dev.sda[^12] /etc/fstab
/dev/sda3 / reiserfs noatime,ro 1 1
#/dev/sda4 /mnt/extra reiserfs noatime,rw 1 1
# 使用正規表示
> grep '^#' /etc/fstab
# /etc/fstab: static file system information.
#
> grep '^#.*\.$' /etc/fstab
# /etc/fstab: static file system information.
#
> grep 'foo$' filename
# 列出有符合的關鍵字
> echo "AAA BBB ccc ddd" | grep -wE -o "(cc|BBB|ddd)"
# 搜尋與關鍵字大小寫一致的行
> grep -w "boo" myfile.txt
> grep "\<boo\>" myfile.txt
# 搜尋包含特殊字元 *** 的關鍵字
> grep '\*\*\*' myfile.txt
# 搜尋 email 地址
> grep -E -o "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,6}\b" /path/to/data
# 電話號碼, 1-XXX-ZZZ-YYYY, XXX-ZZZ-YYYY
> grep -E '(1-)?[[:digit:]]{3}-[[:digit:]]{3}-[[:digit:]]{4}' sample.txt
# 搜尋 IP 位址
> egrep '\b(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)' /etc/hosts
> grep -E -o "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)" /var/log/auth.log
# 更多應用語法
> grep '[vV][iI][Vv][Ee][kK]' filename
> grep '[vV]ivek' filename
> grep -w '[vV]ivek[0-9]' filename
> grep 'foo[0-9][0-9]' filename
> grep '[A-Za-z]' filename
> grep [wn] filename搜尋關鍵字
> 搜尋多個關鍵字(使用正規運算式)
ls /var/log/ | grep -E "http|secure"
ls /var/log/ | grep "http\|secure"
grep -Ev "^(#|;)" example.txt> 在許多檔案內尋找特定字串內容
應用:程式碼編寫及除錯
cd /var/www/html
grep -r "[搜尋關鍵字]" *
grep -Ril "specific_text" /path/to/dir > 搜尋特定字串的文字段落內容
應用:檢查系統的硬體裝置,以及類似 AIX 的 grep -p
見附檔: grepp.awk
> 搜尋字串並顯示前或後幾行的內容
# Before n lines
grep -B1 "^SQL" runstats.log
# After n lines
grep -A1 "^SQL" runstats.log
# Without separator '--'
grep -B1 --no-group-separator "^SQL" runstats.log檢查設定檔
排除每行開頭是 # 與空白的文字
grep '^[^# ]' /etc/security/pwquality.confShell 範例
CONFIG_CHECK=`grep "^# SparkleShare$" /etc/ssh/sshd_config`
if ! [ "$CONFIG_CHECK" = "# SparkleShare" ]; then
echo "" >> /etc/ssh/sshd_config
echo "# SparkleShare" >> /etc/ssh/sshd_config
echo "Match User storage" >> /etc/ssh/sshd_config
echo " PasswordAuthentication no" >> /etc/ssh/sshd_config
fi排除 grep 自己,使用 ps 時
↪ ps -ef | grep 'plank' 西元2022年04月24日 (週日) 09時30分51秒 CST
alang 2575 2166 0 09:22 ? 00:00:02 plank
alang 4831 3916 0 09:30 pts/0 00:00:00 grep --color=auto plank <=========
↪ ps -ef | grep '[p]lank' 西元2022年04月24日 (週日) 09時30分55秒 CST
alang 2575 2166 0 09:22 ? 00:00:02 plank外部變數
# 匯出系統密碼檔
while read line; do grep -w "^${line%%:*}" /etc/shadow; done <passwd.bak >shadow.bakCheat Sheet
test
字串或文字的比對
Str1 = str2 | 當str1與str2相同時, 傳回True
Str1 != str2| 當str1與str2不同時, 傳回True
Str1 < Str2
Str1 <= Str2
Str1 > Str2
Str1 >= Str2
Str | 當str不是空字符時, 傳回True
-n str | 當str的長度大於0時, 傳回True
-z str | 當str的長度是0時, 傳回True[ ]與[[ ]] 差別
[ ... ]: POSIX 相容指令,別名 test,用於條件判斷式。[[ ... ]]: Bash 專有語法,可用於更複雜的條件判斷式。[ -n "$VAR_STR"]: 使用 [ ] 時要注意變數的雙引號用法。
範例:
VAR_STR=""
if [[ -n $VAR_STR ]]; then
echo "var str is nonzero with [["
else
echo "var str is zero with [["
fi
if [ -n $VAR_STR ]; then
echo "var str is nonzero with ["
else
echo "var str is zero with ["
fiOutput:
var str is zero with [[
var str is nonzero with [Fix:
VAR_STR=""
if [[ -n $VAR_STR ]]; then
echo "var str is nonzero with [["
else
echo "var str is zero with [["
fi
if [ -n "$VAR_STR" ]; then # <<<<
echo "var str is nonzero with ["
else
echo "var str is zero with ["
fi數值型比對
整數
Int1 -eq int2 |當int1等於int2時, 傳回True
Int1 -ge int2 |當int1大於/等於int2時, 傳回True
Int1 -le int2 |當int1小於/等於int2時, 傳回True
Int1 -gt int2 |當int1大於int2時, 傳回True
Int1 -ne int2 |當int1不等於int2時, 傳回True
Int1 -lt int2 |當int1小於 int2時, 傳回True 浮點數
asr=87.22
thre=90.00
if (( $(echo "$asr < $thre" | bc -l) )); then
return 0 # true
fi檔案的比對
-e file | 檔案是否存在
-d file | 當file是一個目錄時, 傳回 True
-f file | 當file是一個普通檔案時, 傳回 True
-r file | 當file是一個可讀檔案時, 傳回 True
-s file | 當file檔案內容長度大於0時, 傳回 True; 空白內容傳回 False
-w file | 當file是一個可寫檔案時, 傳回 True
-x file | 當file是一個可執行檔案時, 傳回 TrueFile operators list
| Operator | Returns |
|---|---|
| -a FILE | True if file exists. |
| -b FILE | True if file is block special. |
| -c FILE | True if file is character special. |
| -d FILE | True if file is a directory. |
| -e FILE | True if file exists. |
| -f FILE | True if file exists and is a regular file. |
| -g FILE | True if file is set-group-id. |
| -h FILE | True if file is a symbolic link. |
| -L FILE | True if file is a symbolic link. |
| -k FILE | True if file has its `sticky' bit set. |
| -p FILE | True if file is a named pipe. |
| -r FILE | True if file is readable by you. |
| -s FILE | True if file exists and is not empty. |
| -S FILE | True if file is a socket. |
| -t FD | True if FD is opened on a terminal. |
| -u FILE | True if the file is set-user-id. |
| -w FILE | True if the file is writable by you. |
| -x FILE | True if the file is executable by you. |
| -O FILE | True if the file is effectively owned by you. |
| -G FILE | True if the file is effectively owned by your group. |
| -N FILE | True if the file has been modified since it was last read. |
| ! EXPR | Logical not. |
| EXPR1 && EXPR2 | Perform the and operation. |
| EXPR1 || EXPR2 | Perform the or operation. |
布林變數應用
# Let us Declare Two Boolean Variables
# Set this one to true
jobstatus=true
# Check it
if [ "$jobstatus" = true ] ; then
echo 'Okay :)'
else
echo 'Noop :('
fi
# Double bracket format syntax to test Boolean variables in bash
bool=false
if [[ "$bool" = true ]] ; then
echo 'Done.'
else
echo 'Failed.'
fi更多範例
# 如果前個指令執行有錯誤時,會執行兩個程序
[ ! $? -eq 0 ] && echo "Abort the process!! you can try it agian after you made change." && exit 1
# 或者
[ ! $? -eq 0 ] && {
echo "Abort the process!! you can try it agian after you made change."
exit 1
}
#
if [[ $RETURN_CODE != 0 ]]; then
echo "Zulip first start database initi failed in \"initialize-database\" exit code $RETURN_CODE. Exiting."
exit $RETURN_CODE
fi
#
if [[ $TIMEOUT -eq 0 ]]; then
echo "Could not connect to database server. Exiting."
unset PGPASSWORD
exit 1
fi
#
if (($? > 0)); then
echo "$SECRET_KEY = $SECRET_VAR" >> "$DATA_DIR/zulip-secrets.conf"
echo "Secret added for \"$SECRET_KEY\"."
fi
#
if test "x$newbranch" = x; then
newbranch=`git branch -a | grep "*" | cut -d ' ' -f2`
fi
# Check router home directory.
[ -d "$PROD_HOME" ] || {
echo "Router home directory ($PROD_HOME) not found"
exit 1
}
# AND
autoBackupConfiguration() {
if ([ "$AUTO_BACKUP_ENABLED" != "True" ] && [ "$AUTO_BACKUP_ENABLED" != "true" ]); then
rm -f /etc/cron.d/autobackup
echo "Auto backup is disabled. Continuing."
return 0
fi
}
# OR
if [ "$MANUAL_CONFIGURATION" = "False" ] || [ "$MANUAL_CONFIGURATION" = "false" ]; then
databaseConfiguration
secretsConfiguration
authenticationBackends
zulipConfiguration
fi
# Die if $f1 or $f2 is missing
if [ ! -f "$f1" ] || [ ! -f "$f2" ]
then
echo "Required files are missing."
else
echo "Let us build SFTP jail."
fi
# And
if [[ $age -ge 18 ]] && [[ $nat -eq "Indian" ]];then
echo "You can vote!!!"
else
echo "You can not vote"
fi
# multiple AND
if [ -e "$DATA_DIR/.initiated" ] && ([ "$FORCE_FIRST_START_INIT" != "True" ] && [ "$FORCE_FIRST_START_INIT" != "true" ]); then
echo "First Start Init not needed. Continuing."
return 0
fi
# one-liner
[[ -z "$var" ]] && echo "NULL" || echo "NOT NULL"
# if age is greater than or equal to 18 then the program will print "Adult" or it will print "Minor".
[[ $age -ge 18 ]] && echo "Adult" || echo "Minor"
# Contain a substring
if [[ $var = *pattern1* ]]; then
echo "Do something"
fi
[[ $1 != *cyberciti.biz/faq/* ]] && { printf "Error: Specify faq url (e.g., http://www.cyberciti.biz/faq/url-1-2-3/)\n"; exit 2; }
if [[ $fullstring == *"$substr"* ]];
# Regex
if [[ $ip =~ ^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$ ]]; then
head="win00000:hascom_command.ksh : hostname:wintstc, monitor port#:17911"
if [[ $head =~ ^win00000.*$ ]]; then
# Check the the number of the version
[ "$(echo "$TMUX_VERSION >= 2.4" | bc)" = 1 ] || echo "The version $TMUX_VERSION is outdated" Two functions (Is_alert & Notify) return True
if Is_alert && Notify; then
echo "Send_mail"
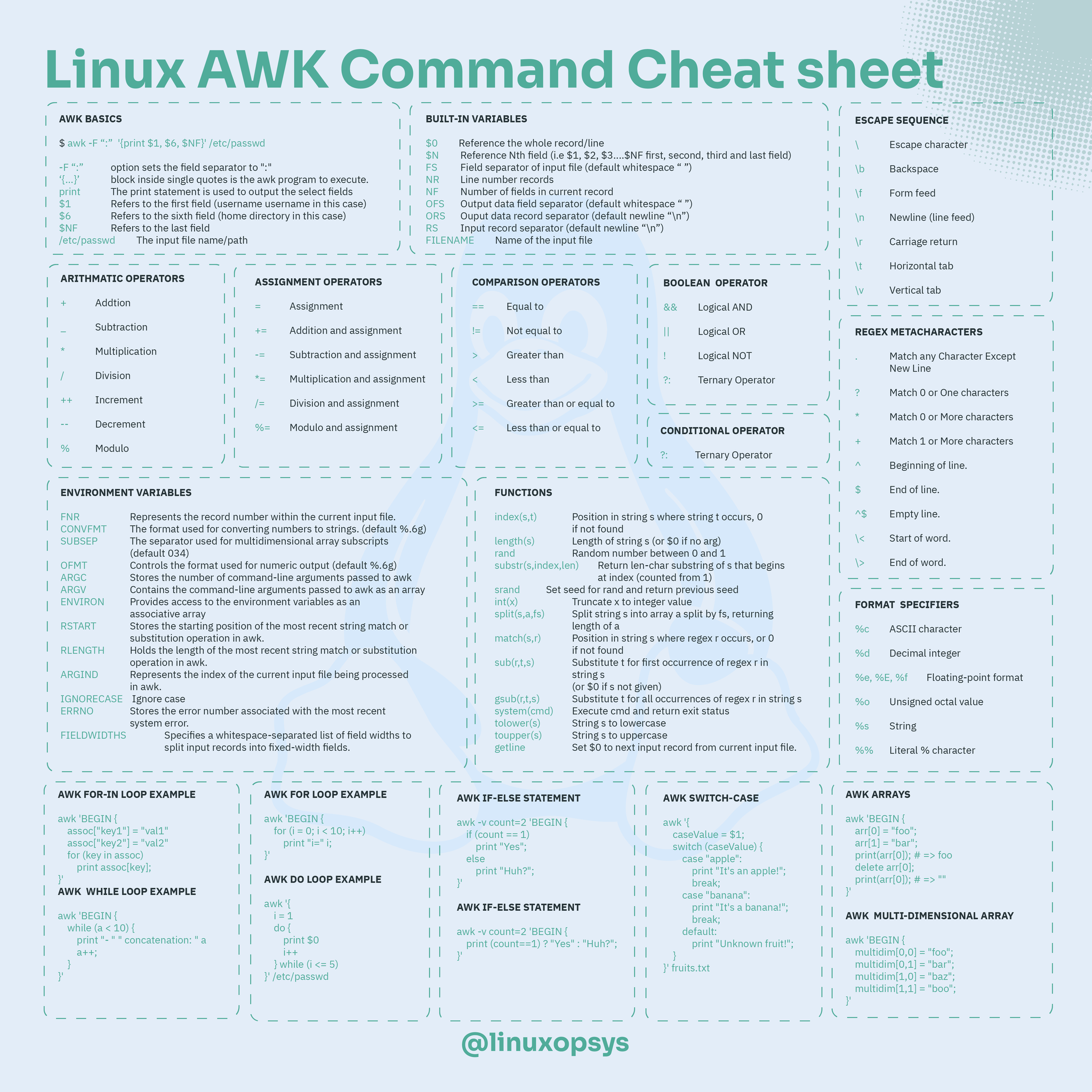
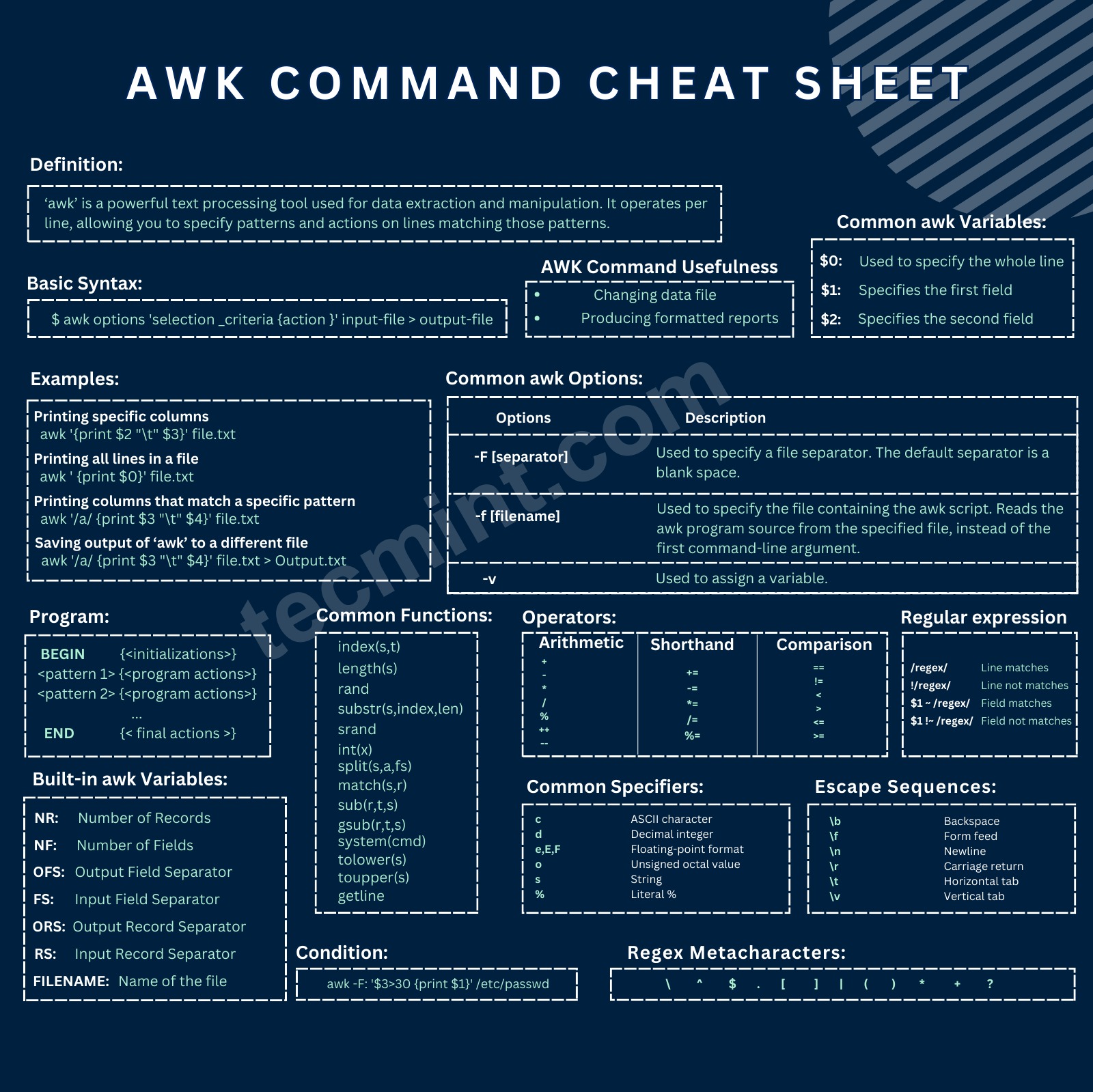
fiawk
教學網站
- https://linuxhandbook.com/awk-command-tutorial/
- Running Awk in parallel to process 256M records
- Awk one-liners
搜尋字串
awk '/^this/{print $0}' #與 sed -n '/^this/p' 相同搜尋取代
# 移除分號
awk { gsub(/\;/, "") }移除重複資料的行
我們經常使用 sort 與 uniq 指令,從檔案中找出並移除重複項目。不過如果你不希望你的原始檔被排序或更動,這時正是 awk 派上用場的時候,我們可以用 awk 截取不重複記錄並儲存在新的檔案中
awk '!x[$0]++' filewithdupes > newfile搜尋含 disabled 的行,並列出第 1, 3 欄的內容
awk '/disabled/{print $1, $3}'取值做計算
awk '{print "up " $1 /60 " minutes"}' /proc/uptime
df -lP -text4 |awk '{sum += $4} END {printf "%d GiB\n", sum/1048576}'
df -lP -text4 |awk '{sum += $4} END {printf "%d GiB\n", sum/2**20}'加上判斷式
df -k |grep "/dev/" | awk '($2 > 0 && ((1 - $3/$2) > 0.9) ) {print $0 }'
awk -F" " '{print ($7 != "A")?$0"***":$0}' myfile搜尋每行的第9欄,如果不是 0x00000000 時就顯示該行訊息
cat info.out | awk '($9 != "0x00000000") {print}'列出 uid >= 500 且 <= 10000 的行
export UGIDLIMIT=500
awk -v LIMIT=$UGIDLIMIT -F: '($3>=LIMIT) && ($3<=10000)' /etc/passwd解決長整數顯示問題
$ awk 'BEGIN {print 12345678901234567890}'
1.23457e+19
方法一
$ awk 'BEGIN {printf("%d\n", 12345678901234567890)}'
12345678901234567168
方法二
$ awk 'BEGIN {OFMT="%.0f"; print 12345678901234567890}'
12345678901234567168 列出 uid=0 的帳號
awk -F: '($3 == "0") {print}' /etc/passwd列出最後一個欄位的值
ls -ltd */ | awk -F ' ' '{print $NF}'列出長度大於 64 的行
awk 'length > 64'格式化輸出
awk '{ printf("1-minute: %s\n5-minute: %s\n15-minute: \
%s\n",$1,$2,$3); }' /proc/loadavg計算目錄的檔案大小
foldersize() {
if [ -d $1 ]; then
ls -alRF $1/ | grep '^-' | awk 'BEGIN {tot=0} { tot=tot+$5 } END { print tot }'
else
echo "$1: folder does not exist"
fi
}計算單字總數(以符號 "空格" 作為單字的識別)
awk '{total=total+NF}; END {print total+0}'搜尋特定字串的文字段落內容
# lspci -v | awk '/ATI/,/^$/'
01:03.0 VGA compatible controller: ATI Technologies Inc Rage XL (rev 27) (prog-if 00 [VGA])
Subsystem: Compaq Computer Corporation: Unknown device 001e
Flags: bus master, stepping, medium devsel, latency 64
Memory at fc000000 (32-bit, non-prefetchable) [size=16M]
I/O ports at 3000 [size=256]
Memory at fbff0000 (32-bit, non-prefetchable) [size=4K]
Capabilities: [5c] Power Management version 2批次 Kill 名稱包含有 /plugins/mactrack 的程式
ps -ef | grep "/plugins/mactrack" | awk '{system("kill " $2);}'使用兩個不同的區隔符號: 空格 + =
# 顯示回應時間
ping 8.8.8.8 | awk -F[\ =] '{print $10}'取出每十行的資料(第 10, 20, 30, ...)
awk '!(NR % 10)' file自動清理舊檔案,保留最近一個檔案
# Sort nmon files by time, delete a file far from the current time, always keep only one nmon file:
ls -t ~/*.nmon |awk '/\.nmon/ {if (NR >1){system ("rm " $1)}}'CSV 指定欄位值
- GoAWK - A POSIX-compliant AWK interpreter written in Go, with CSV support
# 統計第 13 欄 APPNAME 每個值的計數
cat ./ISO27001/db2/fdctest_validate.csv | awk -F, '{a[$13]++} END {for (k in a) print k, a[k]}'
# 變更欄位 3 的值
awk '{ $3 = toupper(substr($3,1,1)) substr($3,2) } $3' FS=, OFS=, file
# 欄位 3 變更成大寫
awk '$3 { print toupper($0); }' file清除空白行
awk NF test.txt範例: 段落文字的解析
script: aud2csv.sh
Raw Data:
timestamp=2023-01-08-23.13.02.322992;
category=CHECKING;
audit event=CHECKING_OBJECT;
event correlator=107;
event status=0;
database=RPTDB;
userid=winmfg;
authid=WINMFG;
application id=10.8.25.30.64020.230108151301;
application name=EXCEL.EXE;
package schema=NULLID;
package name=SYSSH200;
package section=4;
object schema=ISTRPT;
object name=FHOPEHS;
object type=TABLE;
access approval reason=OBJECT;
access attempted=SELECT;
local transaction id=0x00000001b6550792;
global transaction id=0x0000000000000000000000000000000000000000;
instance name=istrpt;
hostname=BSMDB_B;函式說明:
# 宣告: 紀錄的間隔符號為 空行, 欄位間隔符號為 =
# 一個段落文字為一筆紀錄,每一行以 = 為間隔區別不同欄位
BEGIN {
FS="=";
RS="";
}
# 過濾條件: 欄位總數是 nfp2 的值的資料
# 此實例包含了有不一致欄位數的紀錄,所以必須先做過濾
NF==nfp2 {
}
# 移除 分號字元
{ gsub(/\;/, "") }
# TIMESTAMP = 欄位 2
# CATEGORY = 欄位 4
# f1 = 欄位 1
# f2 = 欄位 3
{
TIMESTAMP=2; CATEGORY=4; AUDIT_EVENT=6; EVENT_CORRELATOR=8; EVENT_STATUS=10; DATABASE=12; USERID=14; AUTHID=16; APPLICATION_ID=18; APPLICATION_NAME=20; PACKAGE_SCHEMA=22; PACKAGE_NAME=24; PACKAGE_SECTION=26; OBJECT_SCHEMA=28; OBJECT_NAME=30; OBJECT_TYPE=32; ACCESS_APPROVAL_REASON=34; ACCESS_ATTEMPTED=36; LOCAL_TRANSACTION_ID=38; GLOBAL_TRANSACTION_ID=40; INSTANCE_NAME=42; HOSTNAME=44;
f1=1; f2=3; f3=5; f4=7; f5=9; f6=11; f7=13; f8=15; f9=17; f10=19; f11=21; f12=23; f13=25; f14=27; f15=29; f16=31; f17=33; f18=35; f19=37; f20=39; f21=41; f22=43
}
# 印出 CSV 的 Header 行
if (! headline)
{
headline = sprintf( "%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s", $f1, $f2, $f3, $f4, $f5, $f6, $f7, $f8, $f9, $f10, $f11, $f12, $f13, $f14, $f15, $f16, $f17, $f18, $f19, $f20, $f21, $f22 );
print headline;
}
# 印出 CSV 的資料
dataline = sprintf("%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s", $TIMESTAMP, $CATEGORY, $AUDIT_EVENT, $EVENT_CORRELATOR, $EVENT_STATUS, $DATABASE, $USERID, $AUTHID, $APPLICATION_ID, $APPLICATION_NAME, $PACKAGE_SCHEMA, $PACKAGE_NAME, $PACKAGE_SECTION, $OBJECT_SCHEMA, $OBJECT_NAME, $OBJECT_TYPE, $ACCESS_APPROVAL_REASON, $ACCESS_ATTEMPTED, $LOCAL_TRANSACTION_ID, $GLOBAL_TRANSACTION_ID, $INSTANCE_NAME, $HOSTNAME );
print dataline;
範例: 與 bash 整合
# System Memory Section
mem_raw=$(free -b | awk '/Mem:/ {print $2, $3, $4, $7}')
read -r -a mem_array <<< "$mem_raw"
mem_total_bytes=${mem_array[0]}
mem_used_bytes=${mem_array[1]}
mem_free_bytes=${mem_array[2]}
mem_avail_bytes=${mem_array[3]}
mem_total_gb=$(awk "BEGIN {printf \"%.2f\", $mem_total_bytes / 1024 / 1024 / 1024}")
mem_used_gb=$(awk "BEGIN {printf \"%.2f\", $mem_used_bytes / 1024 / 1024 / 1024}")
mem_free_gb=$(awk "BEGIN {printf \"%.2f\", $mem_free_bytes / 1024 / 1024 / 1024}")
mem_avail_gb=$(awk "BEGIN {printf \"%.2f\", $mem_avail_bytes / 1024 / 1024 / 1024}")
avail_mem_percentage=$(awk "BEGIN {printf \"%.2f\", 100 * $mem_avail_bytes / $mem_total_bytes}")
is_low_mem=$(awk "BEGIN {print ($avail_mem_percentage < 10)}")
if (( is_low_mem )); then
mem_info="Total: ${mem_total_gb} GB, Used: ${mem_used_gb} GB, Free: ${mem_free_gb} GB, Available: ${mem_avail_gb} GB \033[0;31m(Warning!: ${avail_mem_percentage}%%)\033[0m"
else
mem_info="Total: ${mem_total_gb} GB, Used: ${mem_used_gb} GB, Free: ${mem_free_gb} GB, Available: ${mem_avail_gb} GB"
fiCheatsheet

sed
教學網站
- http://www.tecmint.com/linux-sed-command-tips-tricks/
- https://www.cyberciti.biz/faq/how-to-use-sed-to-find-and-replace-text-in-files-in-linux-unix-shell/
- Complete Sed Command Guide
- Sed - An Introduction and Tutorial by Bruce Barnett
- Learn to use the Sed text editor
- THE SED FAQ
- Useful sed
- sed 進階範例
分隔符號
除了常見的 / ,也能使用 @ , | , %
Tip: 有時遇到要搜尋某些特殊符號,可能會需要更換不同的分隔符號。
For s command
# 將 /usr/bin 加上 local 成為 /usr/bin/local
sed 's@/usr/bin@&/local@g' path.txtOther command
# 開頭要加一個反斜線
echo $PATH | sed -n '\@/usr/local/sbin@p'常用語法範例
# 移除註解, 空白行
sed '/^#\|^$\| *#/d' my.conf
# 只移除註解文字,但不刪除整行
sed 's/#.*//' file.txt
# 搜尋取代: 每一行第 1 個 Linux 換成 Unix
sed 's/Linux/Unix/' linuxteck.txt
# 搜尋取代: 每一行第 1 個 Linux 換成 Unix (不分大小寫)
sed 's/Linux/Unix/i' linuxteck.txt
# 搜尋取代: 每一行第 2 個 Linux 換成 Unix
sed 's/Linux/Unix/2' linuxteck.txt
# 搜尋取代: 第二行第 1 個 Linux 換成 Unix
sed '2 s/Linux/Unix/' linuxteck.txt
# 搜尋取代: 全文的 Linux 換成 Unix
sed 's/Linux/Unix/g' linuxteck.txt
# 列印: 行號
sed -n p linuxteck.txt
# 列印: 第 2-4 行
sed -n '2,4p' linuxteck.txt
# 列印: 移除第 2-4 行
sed '2,4d' linuxteck.txt
# 列印: 第 2-3, 5-6 行
sed -n -e '2,3p' -e '5,6p' linuxteck.txt
# 列印: 包含 operating 的行
sed -n /operating/p linuxteck.txt
# 每一行之間加一個空白行
sed G linuxteck.txt
# 在每個註解行下方加一個空行
sed '/^#/G' file.txt
列出搜尋內容
# 列出第 100 行以下的所有文字
# 若要刪除,可將 p 換成 d。
sed -n '100,$p' my.txt
# 列出第 3 行以上的所有文字
sed '3q' my.txt
# 列出第 130 行
sed -n '130{p;q}' my.txt
# 列出第 100 - 130 行文字
sed -n '100,130p' my.txt
sed -n '100,130p;130q' my.txt
# 列出關鍵字 all 以下所有行
sed -n '/all/,$p' my.txt
# 列出關鍵字 start 以上的所有文字
sed '/start/q' file.txt
# 搜尋關鍵字,並列出這個段落的所有文字
sed -n '/keyword/,/^$/p'
# 列出關鍵字 Top 與 Bottom 之間的所有文字
sed -n '/Top/,/Bottom/p'
# 搜尋字串的那一行
sed -n "/PATTERN/p" my.txt
sed -n "/PATN1\|PATN2\|PATN3/p" my.txt刪除搜尋內容
# 刪除行首為# 的行
sed '/^#/d'
# 刪除行首為 # 或空白的行
sed '/^#\|^$\| *#/d'
sed '/^#/d;/^$/d' # for AIX
# 刪除多個關鍵字的行, ADMIN_ERP_ROLE, RPT01,...
sed '/ADMIN_ERP_ROLE/d;/RPT01/d'
# 刪除空白行
sed '/^$/d'
sed '/^\s*$/d'
# 刪除第 42 行文字
sed 42d my.txt
# 刪除空格
sed 's/[[:space:]]//g' mywords
sed 's/^[ \t]*//;s/[ \t]*$//' mywords
sed 's/^\s*\|\s*$//g' mywords
# 刪除所有行尾的空格字元
sed 's/[[:space:]]*$//'
# 刪除行尾的 ^M (CR 字元)
sed 's/^M//g' NOTE: to get ^M type CTRL+V followed by CTRL+M
sed 's/\r$//g'
# 刪除 iXXXX 的帳號, XXXX 是數字
sed '/^i[0-9]*/d' mypasswd
# 刪除最後一行
sed '$d' my.txt搜尋後取代/插入文字
# 在第 2 行的上方,插入文字 xxx
sed '2i xxx' my.txt
# 在第 2 行的下方,插入文字 yyy
sed '2a yyy' my.txt
# 在第二行的行尾,插入文字 ****
sed '3 s/$/ ****/'
# 搜尋最後一行的 }, 取代成 }
sed -i '$ s/},/}/' "$OUTPUT_JSON_FILE"
# 在搜尋的行下方新增字串 newstring
sed '/patterm/a\newstring' my.txt
# 在所有文字的行首加上 #
sed 's/^/# /' my.txt
# 在所有文字的行尾加上 End
sed 's/$/ End/' my.txt
# 將每一行裡是兩個以上空白字元, 都換成一個 comma 符號
sed "s/ \+/,/g"
# 快速取代字串
sed 's/old/new/' mywords
sed 's|old|new|' mywords
# 搜尋關鍵字 'astlogdir =>' 的這一行,取代行字串為 'astlogdir => /mnt/usb/asterisk_log'
# .*$ 表示行尾前的所有字串
sed -i 's/astlogdir =>.*$/astlogdir => \/mnt\/usb\/asterisk_log/g'
# 搜尋 'none',並且在該行行首加上 '#'
sed 's/none/#&/g' mywords
# 在字串 'daemon' 的下方插入另一個檔案 3.txt 的內容
sed '/daemon/r 3.txt' mywords
sed '/INCLUDE/r foo.h' sample.c
# 特殊字元 / \ & 前加上跳脫符號
sed 's/[\/&]/\\&/g' mywords
# 搜尋文字 'daemon',將符合的內容寫到檔案 3.txt
sed -n '/daemon/w 3.txt' 1.txt
# 將符合文字 'root' 內容的下一行,插入特定的文字 'test test'
[root@linux-3 ~]# sed ‘/root/a test test’ 1.txt
root:x:0:0:root:/root:/bin/bash
test test
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
# 將符合文字 'daemon' 內容的上一行,插入特定的文字 'test test'
[root@linux-3 ~]# sed '/^daemon/i test test' 1.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
test test
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
# 搜尋所有文字是 'ext3' 的,用 [ ] 框起來
sed 's/ext3\+/[&]/g' my.txt
# 搜尋文字並取代部份的內容
sed -i 's/^\(User\|Group\).*/\1 asterisk/' /etc/httpd/conf/httpd.conf
# 搜尋開頭是 revoke 的每一行尾,加上分號. & 表示符合搜尋的內容
sed 's/^revoke.*$/&\;/' revoke_winieop.sql
# 搜尋每一行, 並格式為 <<<STRING>>>. "^.*$" 表示每一行, & 表示符合搜尋的內容
sed 's@^.*$@<<<&>>>@g' path.txt
# 將 /usr/bin 加上 local 成為 /usr/bin/local
sed 's@/usr/bin@&/local@g' path.txt備份 *.sh 檔案且移除第一行 #!/bin/bash
sed -i.bak '1i #!/bin/bash' edit.sh執行多個規則
sed -e '/^#/d' -e '/^$/d' 找出關鍵字的右側字串內容
$ cat cookie.txt
xxxx FALSE / FALSE 0 PHPSESSID dbbr5nsmib9tgm0h97sbq8ovd0
$ cat cookie.txt | sed 's/^.*PHPSESSID[ \t]*//'
dbbr5nsmib9tgm0h97sbq8ovd0找出行的左側內容
列出 10.14.25.196 與 GA016E38 (Hex IP)
$ cat input.txt
GA160223.MAE3.219594040120
10.14.25.196.49611.200203080358
GA016E38.O5FA.259D81215343
10.4.1.29.41266.200114031620
GA12640A.M6EE.20EDC3093010
$ sed 's/^\(.*\)\.[A-Z0-9]*\.[A-Z0-9]*/\1/' input.txt
GA160223
10.14.25.196
GA016E38
10.4.1.29
GA12640A對 CSV 檔案的內容,將所有分隔符號 comma 置換成 @@,但必須排除有包含 comma 的文字敘述,這些文字內的 comma 前個字元會有個空白
sed 's/\(,\)\([^ ]\)/@@\2/g' orig.csvs 搜尋
\( \) \( \) 用括弧區分兩個字元
[^ ] 非空白的字元
\2 第二個字元,這裡要配合括弧的用法
g 作全文置換,若沒有此參數,預設只會置換第一個符合的字元
搜尋 A.AA B.BB C.CC 3個數值,並以指定的格式輸出
sed 's/^\([0-9]\+\.[0-9]\+\) \([0-9]\+\.[0-9]\+\) \([0-9]\+\.[0-9]\+\).*$/1-minute: \1\n5-minute: \2\n15-minute: \3/g' /proc/loadavg^\([0-9]\+\.[0-9]\+\) \([0-9]\+\.[0-9]\+\) \([0-9]\+\.[0-9]\+\).*$ 搜尋語法
1-minute: \1\n5-minute: \2\n15-minute: \3 輸出語法
搜尋/驗證 IP 位址
sed -n '/\([0-9]\{1,3\}\.\)\{3\}[0-9]\{1,3\}/p' my.txt取代所有的 mailbox = xxx 為 mailbox = xxx@context
sed 's/^mailbox = [0-9]*/&@context/g' users.conf搜尋特定區段的 AllowOverride None
只取代這個區段所包含的關鍵字
<Directory "/var/www/html">
...
<Directory>
sed -i ':a;N;$!ba;s/AllowOverride None/AllowOverride All/2' /etc/httpd/conf/httpd.conf擷取 { } 所包含的所有文字
<br/> <b>Notice</b>: Undefined variable: sn in <b>/var/www/raida/service/fix.php</b> on line <b>259</b><br/> {"server":"RAIDA17","sn":"","status":"success","message":"Fixed: Unit's AN was changed to the PAN. Update your AN to the new PAN.","time":"2017-04-08 06:08:25"}
echo $( cat http_get.txt ) | sed 's/.* \({.*}\)$/\1/'擷取 [ ] 內的文字
echo "[1070059:1,1070060:1,1070039:1]" | sed 's/^\[\(.*\)\]$/\1/'排除法搜尋
# 移除所有行尾結束字元不是雙引號的
sed '/\"$/!d'
# 移除所有行開頭不是 "2021-09-26-23.13.02.097806" 這樣格式的內容
sed '/^\"[0-9]\+\-[0-9]\+\-[0-9]\+\-[0-9]\+\.*/!d'
# 排除 PATTERN1 + 搜尋 PATTERN2 + 取代 WORDS
sed '/PATTERN1/!s/PATTERN2/WORDS/g'
# 除第5行以外的所有文字,搜尋 foo 並以 bar 取代
sed '5!/s/foo/bar/' file.txt
# 排除 start 到 end 之間段落的所有文字
sed -rn '/start/,/end/ !p' file.txt段落搜尋
# 列出關鍵字 Top 與 Bottom 之間段落的所有文字
sed -n '/Top/,/Bottom/p'
# 在 start 與 end 之間段落,搜尋井字開頭的文字,並刪除;井字前的文字仍會保留
sed -E '/start/,/end/ s/#.*//' file.txt進階應用範例
將數字 123456 格式化成 123,456
echo "123456" | sed 's/\(^\|[^0-9.]\)\([0-9]\+\)\([0-9]\{3\}\)/\1\2,\3/g'(W)elcome (T)o (T)he (G)eek (S)tuff
echo "Welcome To The Geek Stuff" | sed 's/\(\b[A-Z]\)/\(\1\)/g'Get the list of usernames in /etc/passwd
sed 's/\([^:]*\).*/\1/' /etc/passwd變數資料
sed -n '\@/usr/local/bin@p' <<< $PATH將群組清單以行方式列出
Tip:
( ) - +等符號需要加上跳脫字元
groups
# domain users@winfoundry.com vdi_fc_it_std01@winfoundry.com pab_zwin_all2@winfoundry.com mis@winfoundry.com prtg_mfgs-r@winfoundry.com 1-3_vpn_it@winfoundry.com
groups | sed 's/\([a-z0-9_ \-]\+@winfoundry.com \)/\1\n/g'
#domain users@winfoundry.com
#quota@winfoundry.com
#it-w@winfoundry.com
#iso 14001-r@winfoundry.com
#mis@winfoundry.com
#it@winfoundry.com
#cqa_spc-r_old@winfoundry.com
#fab_image-r@winfoundry.com
#hp4155b@winfoundry.com
#1-3_vpn_it@winfoundry.comMarkdown 內容
設定 "第 X 章" 為標題 Level 5 格式
# Search: **第 一 章 總則**
# Replace: ##### 第 一 章 總則
sed 's/^.*\(第\ .*\ 章 .*\)\*\*.*$/##### \1/' markdown/勞動基準法.md
# Serch: **法規名稱:**性別平等工作法
# Replace: #### 法規名稱:性別平等工作法
sed -i 's/^\*\*\(法規名稱:\)\*\*\(.*\)$/#### \1\2/' markdown/勞動基準法.md設定 "第 X 條" 為標題 Level 6 格式
# Search: **第 1 條**
# Replace: ###### 第 1 條
sed 's/^.*\(第\ .*\ 條\).*$/###### \1/' markdown/勞動基準法.md修正不正確的斷行
1
要派單位不得於派遣事業單位與派遣勞工簽訂勞動契約前,有面試該派遣勞工或其他指定特定派遣勞工之行為。
2
要派單位違反前項規定,且已受領派遣勞工勞務者,派遣勞工得於要派單位提供勞務之日起九十日內,以書面向要派單位提出訂定勞動契約之意思表示。修正後
1 要派單位不得於派遣事業單位與派遣勞工簽訂勞動契約前,有面試該派遣勞工或其他指定特定派遣勞工之行為。
2 要派單位違反前項規定,且已受領派遣勞工勞務者,派遣勞工得於要派單位提供勞務之日起九十日內,以書面向要派單位提出訂定勞動契約之意思表示。sed 'N;s/^\([123456789]\)\n/\1 /' markdown/勞動基準法.mdSample Scripts
線上範例
- ip.sh - 主機 Public IP 品質健檢
- whoamifuck.sh - Linux 系統安全檢測
- dump_stats.sh - 收集 Linux/Mac 系統資訊
Auto-rar.sh
解壓縮多個分割檔案 (*.part0XX.rar)
#!/bin/bash
echo "-> Started: "`date +%m/%d/%y\ %H:%M\ %Z`
echo "-> As:"`whoami`
i=1
ARCHIVES="$@"
for f in $ARCHIVES; do
PARTCHECK=$(expr "$f" : ".*\([Pp][Aa][Rr][Tt][0-9]\+\.[Rr][Aa][Rr]\)")
RARCHECK=$(expr "$f" : "\(.*\.[Rr][Aa][Rr]\)")
echo "-> Processing($i of $#): $f"
if [ "$PARTCHECK" ] && [ -f $f ]; then
echo "-> Extracting Multipart Archive"
unrar x $f
if [ $? -eq 0 ]; then
FILES=$(expr "$f" : "\(.*[Pp][Aa][Rr][Tt]\).*")
echo "-> Extraction Successful"
echo "-> Removing $FILES*.rar"
rm $FILES*.rar
else
echo "-> **Extraction Failed"
exit 1
fi
else
if [ "$RARCHECK" ] && [ -f $f ]; then
echo "-> Extracting Single Archive"
unrar x $f
if [ $? -eq 0 ]; then
echo "-> Extraction Successful"
echo "-> Removing $f"
rm $f
else
echo "-> **Extraction Failed"
exit 1
fi
fi
fi
echo ""
i=$(( i+1 ))
doneDomaincheck.sh
#!/bin/bash
#Specify all the domains you want to check
DOMAINS="google.com dribbble.com facebook.com youtube.com"
current_epoch=`date '+%s'`
for dm in $DOMAINS
do
expiry_date=`whois $dm | egrep -i "Expiration Date:|Expires on"| head -1 | awk '{print $NF}'`
echo -n " $dm - Expires on $expiry_date "
expiry_epoch=`date --date="$expiry_date" '+%s'`
epoch_diff=`expr $expiry_epoch - $current_epoch`
days=`expr $epoch_diff / 86400`
echo " $days days remaining. "
doneCheck my.cnf and file permissions
# Check for .my.cnf
if [ ! -f ~/.my.cnf ]; then
echo "It seems MySQL credentials are missing."
echo "Please create a ~/.my.cnf file with the following structure:"
echo ""
echo "[client]"
echo "user=your_username"
echo "password=your_password"
echo ""
echo "Ensure the file permissions are secure: chmod 600 ~/.my.cnf"
exit 1
else
# Check file permissions
file_perm=$(stat -c "%a" ~/.my.cnf)
if [ "$file_perm" -ne 600 ]; then
echo "Error: ~/.my.cnf permissions are $file_perm. Please set them to 600 using 'chmod 600 ~/.my.cnf'."
exit 1
fi
echo "Credentials found in ~/.my.cnf, but the command still failed."
echo "MySQL admin output:"
echo "$output"
echo "Please verify your credentials or server status."
exit 1
fiRegex 正規表示式
教學網站
- https://likegeeks.com/regex-tutorial-linux/
- http://overapi.com/regex
- https://regexper.com/#%2F.echo%24%2F (視覺化正規表示式)
- The Greatest Regex Trick Ever
- How to Get Started With Regular Expressions in the Linux Terminal
- Regex Vis
測試 Regex 語法 (awk)
# echo "Testing regex using awk" | awk '/regex/{print $0}'
Testing regex using awk
# echo "\ is a special character" | awk '/\\/{print $0}'
\ is a special character
# echo "likegeeks website" | awk '/^likegeeks/{print $0}'
likegeeks website基本搜尋
# 搜尋字串區分大小寫
echo "This is a test" | sed -n '/test/p'
echo "This is a test" | awk '/test/{print $0}'
# 可以包含空白與數字
echo "This is a test 2 again" | awk '/test 2/{print $0}' | Operators |
Description |
| [abc] |
Match any single character from from the listed characters |
| [a-z] |
Match any single character from the range of characters |
| [^abc] |
Match any single character not among listed characters |
| [^a-z] |
Match any single character not among listed range of characters |
| . |
Match any single character except a newline |
| \ |
Turn off (escape) the special meaning of a metacharacter |
| ^ |
Match the beginning of a line. |
| $ |
Match the end of a line. |
| * |
Match zero or more instances of the preceding character or regex. |
| ? |
Match zero or one instance of the preceding character or regex. |
| + |
Match one or more instances of the preceding character or regex. |
| {n,m} | Match a range of occurrences (at least n, no more than m) of preceding character of regex. |
| | |
Match the character or expression to the left or right of the vertical bar. |
數字字元
[[:digit:]]*: any number of digits (zero or more)[[:digit:]]+: at least one digit[[:digit:]]?: zero or one digits[[:digit:]]{1,3}: at least one and no more than three digits[[:digit:]]{2,}: two or more digits[[:digit:]]{3}: three digits
特殊字元
字元:.*[]^${}\+?|()
$ cat myfile
There is 10$ on my pocket
awk '/\$/{print $0}' myfile
echo "\ is a special character" | awk '/\\/{print $0}'
echo "This ^ is a test" | sed -n '/s ^/p'搜尋字首與字尾
# 搜尋字首
$ echo "likegeeks website" | awk '/^likegeeks/{print $0}'
# 搜尋字尾
$ echo "This is a test" | awk '/test$/{print $0}'
# 搜尋相同字元行的文字
$ awk '/^this is a test$/{print $0}' myfile
# 不顯示空白行
$ awk '!/^$/{print $0}' myfile搜尋字串
用 dot
# cat myfile
this is a test
This is another test
And this is one more
start with this
# awk '/.st/{print $0}' myfile
this is a test
This is another test用 [ ]
// 包含 oth 與 ith
$ awk '/[oi]th/{print $0}' myfile
This is another test
start with this
// 不包含 oth 與 ith
$ awk '/[^oi]th/{print $0}' myfile
And this is one more
start with this <== 有兩個 th使用範圍
$ awk '/[e-p]st/{print $0}' myfile
this is a test
This is another test
$ echo "123" | awk '/[0-9][0-9][0-9]/'
$ awk '/[a-fm-z]st/{print $0}' myfile
this is a test
This is another test 使用 ? : 特定單一字元出現 0 ~ 1 次
grep -E "^#?DS" /etc/mail/sendmail.cf
# Return:
# DS
# #DS[192.168.21.75]
# #DS[10.14.202.142]管理與操作
基本操作
查出目前使用哪種 SHELL
ps -p $$
echo $0
echo $SHELL 執行 SHELL 的方式
sh file
. file
source file執行前一個指令的參數
ls -l /home/alang/test.py
vi !$
# 或
# 適用 ksh, bash, fish, zsh
vi $_
# 或
vi <alt> + .執行前一個指令
!!搜尋最近曾執行過的指令
<ctrl> + r
(reverse-i-search): 輸入指令開頭的前幾個字元
搜尋所有曾執行過的指令集
$> history | grep "keyword"Alias
以下內容需要編輯 ~/.bashrc
使用方法
# User specific aliases and functions
alias date-time='date && cal'常用 Aliases
# Custom specified aliases
alias lastmod="find . -type f -exec stat --format '%Y :%y %n' \"{}\" \; | sort -nr | cut -d: -f2-"
alias vi="vim"
alias grep="grep --color"自訂 functions
date-time () {
date && cal
return
}
export -f date-time避免誤用 crontab 清除指令
# Avoid crontab deleted by mistake with the command 'crontab -r'.
# shift 1: get rid of the first one argument
crontab() {
case $* in
-r* ) shift 1; echo -n "Really delete your crontab? (y/n)? "; read ans; if [ "$ans" = "y" ]; then command crontab -r; else echo "Canceled."; fi;;
* ) command crontab "$@";;
esac
}管理自訂函式
# List All Functions
declare -F
# View a specific function
declare -F function-name
# Delete a specific function
unset -f function-nameCustom Prompt
.bashrc:
# Kali-like Prompt
if $(__git_ps1 2>/dev/null);then
PS1="\[\033[38;5;209m\]┌──[\[\033[38;5;141m\]\u\[\033[38;5;209m\]@\[\033[38;5;105m\]\h\[\033[38;5;231m\]:\w\[\033[38;5;209m\]]\[\033[33m\]\$(GIT_PS1_SHOWUNTRACKEDFILES=1 GIT_PS1_SHOWDIRTYSTATE=1 __git_ps1)\[\033[00m\]\n\[\033[38;5;209m\]└─\\[\033[38;5;209m\]\\$\[\033[37m\] "
else
source /usr/share/git-core/contrib/completion/git-prompt.sh
PS1="\[\033[38;5;209m\]┌──[\[\033[38;5;141m\]\u\[\033[38;5;209m\]@\[\033[38;5;105m\]\h\[\033[38;5;231m\]:\w\[\033[38;5;209m\]]\[\033[33m\]\$(GIT_PS1_SHOWUNTRACKEDFILES=1 GIT_PS1_SHOWDIRTYSTATE=1 __git_ps1)\[\033[00m\]\n\[\033[38;5;209m\]└─\\[\033[38;5;209m\]\\$\[\033[37m\] "
fi┌──[alang@mint-HX90:~]
└─$ 其他
Formatting Scripts
# Install shfmt
## On Ubuntu
sudo snap install shfmt
## On Alpine Linux
sudo apk add shfmt
## On FreeBSD
sudo pkg install devel/shfmt
# Format shell programs using Shfmt
## -i flag is the amount of spaces that will be used to intend.
shfmt -i 4 myscript.sh
## With Diff style output
shfmt -d -i 4 myscript.sh終端機輸出內容轉存一個檔案
# 1. script
# Once you are done with the session, type the 'exit'.
script my.out
# 2. tee
myprogram | tee my.out常用鍵盤快捷鍵
| Key | Operation |
|---|---|
| Ctrl + a | Go to the beginning of the line. |
| Ctrl + e | Go to the end of the line. |
| Alt + b | Go left(back) one word. |
| Alt + f | Go right(forward) one word. |
| Alt + . | Use the last word of the previous command. |
| Ctrl + r | Search through the command's history |
| Ctrl + u | Cut the part of the line before the cursor, adding it to the clipboard. |
| Ctrl + k | Cut the part of the line after the cursor, adding it to the clipboard. |
| Ctrl + l | Clear the screen |
| Ctrl + w | 刪除游標前個單字 |
| Ctrl+x,Ctrl+e | Edit the current command in your $EDITOR. |

Function Examples
HouseKeeping 目錄
清理目錄裡的 *.gz 檔案,用法: KEEP=100 CleanUp /path/to/dir
HouseKeeping() {
dest="$1"
if [ $dest ];then
CheckDIR $dest
cd $dest
echo "-> Cleaning up the directory $dest [$(date +'%Y-%m-%d %T')] ..."
total=$(ls -lt *.gz 2>/dev/null | grep -v "^d" | grep -v "^total" | wc -l)
echo " [!] The numbers of the existing files: $total"
tail_num=$(( $total - $KEEP ))
if [ $tail_num -gt 0 ];then
for f in $(ls -lt *.gz | grep -v "^d" | grep -v "^total" | tail -$tail_num | awk -F ' ' '{print $9}')
do
#echo " [!] Deleted file: $f"
rm -vf $f
done
else
echo " [!] No need of deletion"
fi
fi
}檢查目錄
用法: CheckDIR /path/to/dir
CheckDIR() {
echo -n "-> Checking the directory <$1> ...... "
if [ ! -d $1 ]
then
echo "[Failed]"
exit 1
else
echo "[OK]"
fi
}ip 驗證
# Test an IP address for validity:
# Usage:
# valid_ip IP_ADDRESS
# if [[ $? -eq 0 ]]; then echo good; else echo bad; fi
# OR
# if valid_ip IP_ADDRESS; then echo good; else echo bad; fi
#
function is_ip()
{
local ip=$1
local stat=1
if [[ $ip =~ ^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$ ]]; then
OIFS=$IFS
IFS='.'
ip=($ip)
IFS=$OIFS
[[ ${ip[0]} -le 255 && ${ip[1]} -le 255 \
&& ${ip[2]} -le 255 && ${ip[3]} -le 255 ]]
stat=$?
fi
return $stat
}驗證數值型資料
Is_number() {
# Usage: Is_number ${your-number} 0
# Type: Number with decimal
# If the number is invalid, return 0.
# If not specify, return NULL
local input err_num re
input=$1
err_num=$2
re="^[0-9]+([.][0-9]+)?$"
if [[ $input =~ $re ]]; then
echo $input
else
echo $err_num
fi
}
log_utilization_percent=$(Is_number $raw 0)
# Validate for integer
[[ $port =~ ^-?[0-9]+$ ]] && dosomething
# No minus character
[[ $port =~ ^[0-9]+$ ]] && dosomething
分割線(自動調整寬度)
CL () {
WORDS=$@; termwidth="$(tput cols)"; padding="$(printf '%0.1s' ={1..500})"; printf '%*.*s %s %*.*s\n' 0 "$(((termwidth-2-${#WORDS})/2))" "$padding" "$WORDS" 0 "$(((termwidth-1-${#WORDS})/2))" "$padding";
}
CL "This is Seperator Line"大小寫轉換
ToUpper() {
echo $1 | tr "[:lower:]" "[:upper:]"
}
ToLower() {
echo $1 | tr "[:upper:]" "[:lower:]"
}
URL 字串編碼
function urlencode() {
local data
if [[ $# != 1 ]]; then
echo "Error: No string to urlencode"
return 1
fi
data="$(curl -s -o /dev/null -w %{url_effective} --get --data-urlencode "$1" "")"
if [[ $? != 3 ]]; then
echo "Unexpected error" 1>&2
else
echo "${data##/?}"
fi
return 0
}
urlencode "$1"
function urldecode() {
# urldecode <string>
local url_encoded="${1//+/ }"
printf '%b' "${url_encoded//%/\\x}"
}
函數回傳字串
- https://linuxhint.com/return-string-bash-functions/
- https://www.linuxjournal.com/content/return-values-bash-functions
Example-1: Using Global Variable
function F1()
{
retval='I like programming'
}
retval='I hate programming'
echo $retval
F1
echo $retval
Example-2: Using Function Command
function F2()
{
local retval='Using BASH Function'
echo "$retval"
}
getval=$(F2)
echo $getval
Example-3: Using Variable
function F3()
{
local arg1=$1
if [[ $arg1 != "" ]];
then
retval="BASH function with variable"
else
echo "No Argument"
fi
}
getval1="Bash Function"
F3 $getval1
echo $retval
getval2=$(F3)
echo $getval2
is_root
用途:檢查是否以 root 帳號執行
is_root()
{
current_user="`id`"
case "$current_user" in
uid=0\(root\)*)
;;
*)
echo "$0: You must have root privileges in order to install ${product_name}"
echo "su as root and try again"
echo
exit 1
;;
esac
}
With if-then
if [ ${EUID} -ne 0 ]
then
exit 1 # this is meant to be run as root
fi
Run_MyCodescheck_os
用途:檢查 OS 版本
範例一
check_os()
{
if [ -f /etc/redhat-release ];then
rhel=`grep "^Red Hat Enterprise Linux" /etc/redhat-release`
centos=`grep "^CentOS" /etc/redhat-release`
release=`cat /etc/redhat-release | cut -d'.' -f1 | awk '{print $NF}'`
if [ ! -z "${rhel}" ];then
sys="rhel"
fi
if [ ! -z "${centos}" ];then
sys="rhel"
fi
fi
if [ -z "${sys}" -o -z "${release}" ];then
echo "Can not determine Linux distribution."
exit 127
fi
if [ -f /proc/vz/veinfo ];then
# we are under Virtuozzo
virtuozzo=1
else
virtuozzo=0
fi
if [ "${VNDEBUG}" ];then
debugrpm='--rpmverbosity=debug'
else
debugrpm=''
fi
}
範例二
# Detect the platform for different environment.
OS="$(uname)"
case $OS in
"Linux")
MAIL_CMD="/bin/mail"
;;
"AIX")
MAIL_CMD="/usr/bin/mail"
;;
*)
MAIL_CMD="/bin/mail"
;;
esac
範例三
get_linux_distribution ()
{
if [ -f /etc/debian_version ]; then
DIST="DEBIAN"
HTTP_DIR="/etc/apache2/"
HTTP_CONFIG=${HTTP_DIR}"apache2.conf"
MYSQL_CONFIG="/etc/mysql/mariadb.conf.d/50-server.cnf"
elif [ -f /etc/redhat-release ]; then
DIST="CENTOS"
HTTP_DIR="/etc/httpd/"
HTTP_CONFIG=${HTTP_DIR}"conf/httpd.conf"
MYSQL_CONFIG="/etc/my.cnf"
else
DIST="OTHER"
echo 'Installation does not support your distribution'
exit 1
fi
}is_running
用途:檢查自身程序是否已經執行中,如果有,程序立即跳離,可避免同一個 script 重複被執行。
IsRunning() {
if [ ! -e $script_pid ];then
RUNCOUNT=0
else
RUNPID=$(cat $script_pid)
RUNCOUNT=$(ps -fp $RUNPID | grep -c `basename $0`)
fi
#echo $RUNCOUNT
if [ $RUNCOUNT -eq 0 ];then
echo $$ > $script_pid
return 1 # return False
else
return 0 # return True
fi
}
script_pid="/tmp/$(basename $0).$(whoami).pid"
# Check if the program is already running.
if IsRunning
then
echo "Abort: The program is already running!"
exit 1
fi
getopts 指令參數
function usage ()
{
cat <<- EOT
Usage : ${0##/*/} [options] -t application -q 1024,1055,1077 -m dpggen -u kroybal -r ods [--]
Options:
-d|debug Bash Debugging Info
-m|machine Database host machine
-t|table Starting table
-u|user User to connect to DB
-q|quals Qualifying records to delete
-r|relation Database name
-s|schema Logical Partition
-h|help Display this message
-v|version Display script version
EOT
} # ---------- end of function usage ----------
#-----------------------------------------------------------------------
# Handle command line arguments
#-----------------------------------------------------------------------
[[ $# -eq 0 ]] && {
# no arguments
usage
exit 1
}
while getopts ":dhm:q:r:s:t:u:v" opt
do
case $opt in
d|debug ) set -x;;
h|help ) usage; exit 0 ;;
t|table ) table=$OPTARG;;
q|quals ) quals=$OPTARG;;
m|machine ) host=$OPTARG;;
u|user ) user=$OPTARG;;
r|relation ) db=$OPTARG;;
s|schema ) schema=$OPTARG;;
v|version ) echo "$0 -- Version $ScriptVersion"; exit 0 ;;
\? ) echo -e "\n Option does not exist : $OPTARG\n"
usage; exit 1 ;;
esac # --- end of case ---
done
shift $(($OPTIND-1))# Display usage information
Usage() {
cat <<- EOT
Usage: ${0##/*/} [options]
Options:
-d, Date Range: Specify a datetime range in the format "YYYY-MM-DD HH:MM:SS YYYY-MM-DD HH:MM:SS".
Default: "\$TODAY 00:00:00 \$TODAY 23:59:59"
1 week ago: \$(date --date="1 weeks ago" +'%Y-%m-%d')
-i, Interval: Set the alert interval in minutes (default: 60).
-t, Threshold: Set the ASR threshold (default: 90).
-e, Email: Specify a space-separated list of email addresses.
-r, Report Mode: Send a report regardless of ASR count.
-k, Lock-id: Prevent interference with Notify() (default: 001).
-h, Help: Display this help menu.
Example:
${0##/*/} -t 93
${0##/*/} -d "2025-07-16 00:00:00 2025-07-16 23:59:59" -t 93 -e "user@my.com"
EOT
}
while getopts ":d:i:t:e:k:rh" opt; do
case $opt in
d) call_dt=$OPTARG ;;
i) intv=$OPTARG ;;
t) thre=$OPTARG ;;
e) email=$OPTARG ;;
r) report=true ;;
k) lckid=$OPTARG ;;
h) Usage; exit 0 ;;
:) printf " Missing argument for option: %s\n" "$OPTARG" >&2; Usage; exit 1 ;;
\?) printf " Illegal option: %s\n" "$OPTARG" >&2; Usage; exit 1 ;;
esac
done常用參數代號
[Option] [Typical meaning]
-a All, append
-b Buffer,block size, batch
-c Command, check
-d Debug, delete, directory
-D Define
-e Execute, edit
-f File, force
-h Headers, help
-i Initialize
-I Include
-k Keep, kill
-l List, long, load
-m Message
-n Number, not
-o Output
-p Port, protocol
-q Quiet
-r Recurse, reverse
-s Silent, subject
-t Tag
-u User
-v Verbose
-V Version
-w Width, warning
-x Enable debugging, extract
-y Yes
-z Enable compressionWithout getopts
while [[ "${1}" != "" ]]; do
case "${1}" in
--vertical) verticle="true" ;;
--add-txt) add_txt="true" ;;
--replace) replace="true" ;;
--verify) verify="true" ;;
esac
shift 1
donePause 暫停
用法: pause
可用於程式開發及偵錯
pause()
{
local force_pause=$1
if [ -z $force_pause ]; then
if test $NONINTERACTIVE; then
return 0
fi
else
shift
fi
[ $# -ne 0 ] && echo -e $* >&2
echo -e "Press [Enter] to continue...\c " >&2
read tmp
return 0
}
Log 訊息
log() { # classic logger
local prefix="[$(date +%Y/%m/%d\ %H:%M:%S)]: "
echo "${prefix} $@" >&2
}
log "INFO" "a message"
name=XXXX
tstamp="$(date '+%F_%H%M')"
log_file="$name-output.$tstamp.txt"
timestamp(){
printf "%s\n" "$(date '+%F %T') $*" >&2
}
timestamp "Dumping Linux specific command outputs"
timestamp "Collected $name output to file: $log_file"Error 錯誤訊息
用途:輸出錯誤訊息
error()
{
echo -e "Error: $*!" >&2
return 0
}
die()
{
echo
echo "ERROR: $*"
echo
echo "Check the error reason, fix and try again."
echo "You are welcome to open a support ticket at https://help.4psa.com!"
echo
rm -f ${repolocal} local$$
rm -f /var/lock/subsys/vninstaller
exit 1
}
die() {
printf "ERR: %s\n" "$1" >&2
exit 1
}
[ -e "$SRC" ] || die "Wal colors not found, exiting script. Have you executed Wal before?"
check_deps()
{
which yum >/dev/null 2>&1
if [ $? -gt 0 ];then
echo "yum binary can not be found."
die "It's not in the system PATH or in a standard location."
fi
which ifconfig >/dev/null 2>&1
if [ $? -gt 0 ];then
yum -y install net-tools >/dev/null 2>&1
if [ $? -gt 0 ];then
echo "ifconfig binary can not be found and package net-tools could not be installed."
die "It's not in the system PATH or in a standard location."
fi
fi
}
詢問 Yes/No
用法: getyn "Would you like to install WANPIPE now? [y]"
$NONINTERACTIVE 如果程式執行時,不想讓 user 做任何的輸入時,可以為 1
NONINTERACTIVE=1 ,或者 = 空白,以顯示相關的提示訊息
prompt()
{
if test $NONINTERACTIVE; then
return 0
fi
echo -ne "$*" >&2
read CMD rest
return 0
}
getyn()
{
if test $NONINTERACTIVE; then
return 0
fi
while prompt "$* (y/n) "
do case $CMD in
[yY]) return 0
;;
[nN]) return 1
;;
*) echo -e "\nPlease answer y or n" >&2
;;
esac
done
} 字串加密 (hash/encryption)
- Hashing, Encryption, Encoding 之間的差異與應用場景: hashing_encryption_encoding.jpg
_Decrypt() {
# Encrypt the string by following the command.
# echo "your password" | openssl enc -base64
# NOTE: The openssl requires to be installed.
#
# Decrypt the hash code by following the command.
# _Decrypt "your-hash-key"
#
local hash
hash="$1"
if which openssl >/dev/null 2>&1;then
if [ -n $hash ];then
echo -n "$hash" | openssl enc -base64 -d
fi
fi
return 0
}# Encrypt
echo -n "123456" | openssl enc -aes-256-cbc -a -pass pass:ThisIsPassword
U2FsdGVkX188Af3yumHOyI19WPbltgRQnPDACmtRniQ=
# Decrypt
echo -n "U2FsdGVkX188Af3yumHOyI19WPbltgRQnPDACmtRniQ=" | openssl enc -aes-256-cbc -a -pass pass:ThisIsPassword -d
123456# Hashing with openssl
echo -n "Hello, World" | openssl dgst -sha256帳密資訊雜湊處裡 (hash + salt)
#!/bin/bash
## Create:
salt=12345_
protocol=sha1sum
read -p "Enter login: " username
read -p "Password: " -s pass1
read -p "Repeat: " -s pass2
if [ "$pass1" != "$pass2" ]; then echo "Pass missmatch"; exit 1; else password=$pass1; fi
echo -en "$username " >> ./mypasswd
echo -e "${salt}${password}" | $protocol | awk '{print $1}' >> ./mypasswd#!/bin/bash
## Read:
salt=12345_ #(samesalt)
protocol=sha1sum
read -p "Enter username: " username
read -p "Enter password: " -s password
if [ `grep $username ./mypasswd | awk '{print $2}'` != `echo "${salt}${password}" | $protocol | awk '{print $1}'` ]; then echo -e "wrong username or password"; exit 127; else echo -e "login successfull"; fi# With openssl
echo 'mypassword' | openssl passwd -stdin
echo 'mypassword' | openssl passwd -salt "sAlT" -stdin
# Toe see mode details
openssl passwd -h批次轉檔
# set q here
q=""
helper(){
local p="$*"
for f in $p
do
echo "Working on $f"
ffmpeg -nostdin -vaapi_device /dev/dri/renderD128 -i "$f" -vf format=nv12,hwupload -c:v hevc_vaapi -f mkv -rc_mode 1 -qp "$q" "${f%.*}.HEVC.mkv"
done
}
helper '/tmp/r/*.mp4'
helper '/tmp/r/*.avi'
helper '/path/to/*.mkv'亂數密碼
genpasswd()
{
length=$1
[ "$length" == "" ] && length=16
tr -dc A-Za-z0-9_ < /dev/urandom | head -c ${length} | xargs
}
password=$(genpasswd)
if [ -e "/root/passwordMysql.log" ] && [ ! -z "/root/passwordMysql.log" ]
then
password=$(awk '{print $1}' /root/passwordMysql.log)
fi
touch /root/passwordMysql.log
echo "$password" > /root/passwordMysql.log對話框 whiptail
訊息視窗
whiptail --title "Example Dialog" --msgbox "This is an example of a message box. You must hit OK to continue." 8 78Yes/No
if (whiptail --title "Example Dialog" --yesno "This is an example of a yes/no box." 8 78); then
echo "User selected Yes, exit status was $?."
else
echo "User selected No, exit status was $?."
fi輸入視窗
COLOR=$(whiptail --inputbox "What is your favorite Color?" 8 39 Blue --title "Example Dialog" 3>&1 1>&2 2>&3)
exitstatus=$?
if [ $exitstatus = 0 ]; then
echo "User selected Ok and entered " $COLOR
else
echo "User selected Cancel."
fi
echo "(Exit status was $exitstatus)"A file
echo "Welcome to Bash $BASH_VERSION" > test_textbox
# filename height width
whiptail --textbox test_textbox 12 80密碼遮蔽
PASSWORD=$(whiptail --passwordbox "please enter your secret password" 8 78 --title "password dialog" 3>&1 1>&2 2>&3)
exitstatus=$?
if [ $exitstatus == 0 ]; then
echo "User selected Ok and entered " $PASSWORD
else
echo "User selected Cancel."
fi
echo "(Exit status was $exitstatus)"選單
whiptail --title "Menu example" --menu "Choose an option" 25 78 16 \
"<-- Back" "Return to the main menu." \
"Add User" "Add a user to the system." \
"Modify User" "Modify an existing user." \
"List Users" "List all users on the system." \
"Add Group" "Add a user group to the system." \
"Modify Group" "Modify a group and its list of members." \
"List Groups" "List all groups on the system."複選清單
whiptail --title "Check list example" --checklist \
"Choose user's permissions" 20 78 4 \
"NET_OUTBOUND" "Allow connections to other hosts" ON \
"NET_INBOUND" "Allow connections from other hosts" OFF \
"LOCAL_MOUNT" "Allow mounting of local devices" OFF \
"REMOTE_MOUNT" "Allow mounting of remote devices" OFF單選清單
whiptail --title "Radio list example" --radiolist \
"Choose user's permissions" 20 78 4 \
"NET_OUTBOUND" "Allow connections to other hosts" ON \
"NET_INBOUND" "Allow connections from other hosts" OFF \
"LOCAL_MOUNT" "Allow mounting of local devices" OFF \
"REMOTE_MOUNT" "Allow mounting of remote devices" OFF進度條
#!/bin/bash
{
for ((i = 0 ; i <= 100 ; i+=5)); do
sleep 0.1
echo $i
done
} | whiptail --gauge "Please wait while we are sleeping..." 6 50 0檢查指令或套件
function color
{
# 定义颜色和样式变量
reset="\033[0m"
bold="\033[1m"
underline="\033[4m"
inverse="\033[7m"
# 定义前景色变量
redx="\e[1;31m"
black="\033[30m"
red="\033[1;31m"
green="\033[32m"
yellow="\033[33m"
orange="\033[1;93m"
blue="\033[1;34m"
purple="\033[35m"
cyan="\033[36m"
white="\033[1;37m"
# 定义背景色变量
bg_black="\033[40m"
bg_red="\033[41m"
bg_green="\033[42m"
bg_yellow="\033[43m"
bg_blue="\033[44m"
bg_purple="\033[45m"
bg_cyan="\033[46m"
bg_white="\033[47m"
}
function os_name
{
if [ -e /etc/os-release ]; then
# Get the name of the current Linux distribution
os_name=$(grep PRETTY_NAME /etc/os-release | cut -d= -f2 | tr -d '"')
if [[ "$os_name" == *"Debian"* ]]; then
OSNAME="Debian"
OSTYPE="T_Debian"
elif [[ "$os_name" == *"CentOS"* ]]; then
OSNAME="CentOS"
OSTYPE="T_RedHat"
elif [[ "$os_name" == *"Ubuntu"* ]]; then
OSNAME="Ubuntu"
OSTYPE="T_Debian"
elif [[ "$os_name" == *"Kali"* ]]; then
OSNAME="Kali"
OSTYPE="T_Debian"
else
OSNAME="Unknown distribution"
OSTYPE="T_RedHat"
fi
fi
}
# NOTE: 不適用於 command 與 package 不同名稱的例子
function i
{
color
os_name
# os
if [[ $OSTYPE == "T_Debian" ]]; then
OS_APP="apt-get"
else
OS_APP="yum"
fi
local package=$1
if ! command -v "$package" &> /dev/null; then
printf "$package ${redx} uninstalled ${reset} \n"
read -p "是否安装 $package? (Y/n): " choice
choice=${choice:-y}
case "$choice" in
y|Y )
echo "正在安装 $package..."
sudo $OS_APP update
sudo $OS_APP install -y "$package"
;;
* )
printf "exit\n"
exit 1
;;
esac
else
printf "$package ${green} installed ${reset} \n"
fi
}
i "rsync"# 'which' 與 'command' 擇一使用
function chk_commands
{
if ! which curl &> /dev/null; then
printf "WARNING curl 指令不存在。\n"
elif ! command -v rsync &> /dev/null; then
printf "WARNING rsync 指令不存在。\n"
fi
}
function chk_command
{
local cmd
cmd=$1
if ! command -v $cmd &> /dev/null; then
printf "WARNING $cmd 指令不存在。\n"
fi
}
chk_command "rsync"用 for loop
# --- Check prerequisites ---
for cmd in jq fail2ban-client; do
if ! command -v "$cmd" &>/dev/null; then
log "ERROR: $cmd is not installed."
exit 1
fi
doneis_alert
value=$1
threshold=10
is_alert=$(awk "BEGIN {print ($value > 10)}")
if (( is_alert )); then
echo "Alert: The value $value has been exceed the threshold $threshold !"
else
echo "Everything is fine."
fiUsage/Help
Usage() {
cat <<- EOT
Usage: ${0##/*/} [options]
Options:
-d, Date Range: Specify a datetime range in the format "YYYY-MM-DD HH:MM:SS YYYY-MM-DD HH:MM:SS".
Default: "\$TODAY 00:00:00 \$TODAY 23:59:59"
1 week ago: \$(date --date="1 weeks ago" +'%Y-%m-%d')
-i, Interval: Set the alert interval in minutes (default: 60).
-t, Threshold: Set the ASR threshold (default: 90).
-e, Email: Specify a space-separated list of email addresses.
-r, Report Mode: Send a report regardless of ASR count.
-k, Lock-id: Prevent interference with Notify() (default: 001).
-h, Help: Display this help menu.
Example:
${0##/*/} -t 93
${0##/*/} -d "2025-07-16 00:00:00 2025-07-16 23:59:59" -t 93 -e "user@my.com"
EOT
}Cleanup
腳本退出時執行自動清理
cleanup() {
if [ -f "$tmpfile" ]; then
rm -f $tmpfile
fi
}
trap cleanup EXIT
##### Below was main code #####Learning
dialog

selection.sh
#!/bin/bash
# while-menu-dialog: a menu driven system information program
DIALOG_CANCEL=1
DIALOG_ESC=255
HEIGHT=0
WIDTH=0
display_result() {
dialog --title "$1" \
--no-collapse \
--msgbox "$result" 0 0
}
while true; do
exec 3>&1
selection=$(dialog \
--backtitle "System Information" \
--title "Menu" \
--clear \
--cancel-label "Exit" \
--menu "Please select:" $HEIGHT $WIDTH 4 \
"1" "Display System Information" \
"2" "Display Disk Space" \
"3" "Display Home Space Utilization" \
2>&1 1>&3)
exit_status=$?
exec 3>&-
case $exit_status in
$DIALOG_CANCEL)
clear
echo "Program terminated."
exit
;;
$DIALOG_ESC)
clear
echo "Program aborted." >&2
exit 1
;;
esac
case $selection in
0 )
clear
echo "Program terminated."
;;
1 )
result=$(echo "Hostname: $HOSTNAME"; uptime)
display_result "System Information"
;;
2 )
result=$(df -h)
display_result "Disk Space"
;;
3 )
if [[ $(id -u) -eq 0 ]]; then
result=$(du -sh /home/* 2> /dev/null)
display_result "Home Space Utilization (All Users)"
else
result=$(du -sh $HOME 2> /dev/null)
display_result "Home Space Utilization ($USER)"
fi
;;
esac
donezenity

who_is.sh
#!/bin/bash
# Get domain name
_zenity="/usr/bin/zenity"
_out="/tmp/whois.output.$$"
domain=$(${_zenity} --title "Enter domain" \
--entry --text "Enter the domain you would like to see whois info" )
if [ $? -eq 0 ]
then
# Display a progress dialog while searching whois database
whois $domain | tee >(${_zenity} --width=200 --height=100 \
--title="whois" --progress \
--pulsate --text="Searching domain info..." \
--auto-kill --auto-close \
--percentage=10) >${_out}
# Display back output
${_zenity} --width=800 --height=600 \
--title "Whois info for $domain" \
--text-info --filename="${_out}"
else
${_zenity} --error \
--text="No input provided"
fiMore Tutorials
Array 陣列
Learning
- Bash Scripting – Indexed Array Explained With Examples
- Bash Scripting – Associative Array Explained With Examples
List Array
- 陣列長度:
${#str_list[@]} - 陣列內容:
${str_list[@]}或${str_list[*]}
#!/bin/bash
str_list=("aaa" "bbb" "ccc" "ddd")
echo ${#str_list[@]}
for i in ${str_list[@]}
do
echo "$i"
done# Script to split a string based on the delimiter
my_string="Ubuntu;Linux Mint;Debian;Arch;Fedora"
IFS=';' read -ra my_array <<< "$my_string"
#Print the split string
for i in "${my_array[@]}"
do
echo $i
done# Script to split a string based on the delimiter
my_string="Ubuntu;Linux Mint;Debian;Arch;Fedora"
my_array=($(echo $my_string | tr ";" "\n"))
#Print the split string
for i in "${my_array[@]}"
do
echo $i
donelocal n=0
until [[ $n -eq ${#asr_array[@]} ]]; do
asr=${asr_array[$n]}
echo $asr
let n++
done
用 printf 輸出陣列內容,搭配 grep 可做條件判斷式
# --- Ban active IPs not already banned ---
for ip in $active_ips; do
if ! printf '%s\n' "${banned_ips[@]}" | grep -qw "$ip"; then
log "Banning IP via Fail2Ban: $ip"
fail2ban-client set "$JAIL" banip "$ip"
fi
done
移除陣列內容
# Delete the 3th element of the array
unset str_list[3]String to Array
while read c1 c2 c3 c4 c5 c6;do
day="$c1"
ncalls="$c4"
scalls="$c6"
asr=$(echo "scale=2; $scalls * 100 / $ncalls" | bc)
day_str+="$day "
asr_str+="$asr "
calls_str+="$ncalls "
done < $tmpfile
read -ra day_array <<< "$day_str"
read -ra asr_array <<< "$asr_str"
read -ra calls_array <<< "$calls_str"mapfile
將檔案內容或指令輸出,逐行寫入陣列。
基本用法
- 以下 lines 是陣列資料
mapfile lines < file.txtmapfile -t lines < <(command)
# File
mapfile MYFILE < example.txt
echo ${MYFILE[@]}
echo ${MYFILE[0]}
# Command
mapfile -t GEEKSFORGEEKS < <(printf "Item 1\nItem 2\nItem 3\n")
echo ${GEEKSFORGEEKS[@]}範例:檢查 ufw 的阻擋 IP
# --- Remove UFW rules for inactive IPs ---
for ip in $inactive_ips; do
# Get UFW rules for this IP in reverse order to avoid shifting rule numbers on deletion
mapfile -t rules < <(ufw status numbered | grep "$ip" | grep "DENY IN" | tac)
for rule in "${rules[@]}"; do
rule_number=$(echo "$rule" | awk -F'[][]' '{print $2}')
log "Removing UFW rule #$rule_number for IP: $ip"
ufw --force delete "$rule_number"
done
doneLearning SHELL
- 7 Bash tutorials to enhance your command line skills in 2021
- Top 10 Free Resources to Learn Shell Scripting
- Better Bash Scripting in 15 Minutes
- explainshell.com
- 10 Useful Tips for Writing Effective Bash Scripts in Linux
應用範例
String Manipulation 字串處理
字串長度
my_string="abhishek"
echo "length is ${#my_string}"Using expr
str="my string"
length=$(expr length "$str")
echo "Length of my string is $length"Using awk
echo "my string" | awk '{print length}'Using wc
str="my string"
length=$(echo -n "my string" | wc -m)
echo "Length of my string is $length"字串比對
Using wildcards
#!/bin/bash
STR='GNU/Linux is an operating system'
SUB='Linux'
if [[ "$STR" == *"$SUB"* ]]; then
echo "It's there."
fiUsing case
#!/bin/bash
STR='GNU/Linux is an operating system'
SUB='Linux'
case $STR in
*"$SUB"*)
echo -n "It's there."
;;
esacUsing Regex
#!/bin/bash
STR='GNU/Linux is an operating system'
SUB='Linux'
if [[ "$STR" =~ .*"$SUB".* ]]; then
echo "It's there."
fiUsing Grep
#!/bin/bash
STR='GNU/Linux is an operating system'
SUB='Linux'
if grep -q "$SUB" <<< "$STR"; then
echo "It's there"
fi字串合併
str1="hand"
str2="book"
str3=$str1$str2STR="Hello"
STR+=", World"
echo $STR字元提取
foss="Fedora is a free operating system"
echo ${foss:0:6}_admin_ip="202.54.1.33|MUM_VPN_GATEWAY 23.1.2.3|DEL_VPN_GATEWAY 13.1.2.3|SG_VPN_GATEWAY"
for e in $_admin_ip
do
ufw allow from "${e%%|*}" to any port 22 proto tcp comment 'Open SSH port for ${e##*|}'
done字元取代
foss="Fedora is a free operating system"
echo ${foss/Fedora/Ubuntu}Summary: String Manipulation and Expanding Variables
${parameter:-defaultValue} |
Get default shell variables value |
${parameter:=defaultValue} |
Set default shell variables value |
${parameter:?"Error Message"} |
Display an error message if parameter is not set |
${#var} |
Find the length of the string |
${var%pattern} |
Remove from shortest rear (end) pattern |
${var%%pattern} |
Remove from longest rear (end) pattern |
${var:num1:num2} |
Substring |
${var#pattern} |
Remove from shortest front pattern |
${var##pattern} |
Remove from longest front pattern |
${var/pattern/string} |
Find and replace (only replace first occurrence) |
|
echo "${PATH//:/$'\n'}" |
Find and replace all occurrences |
${!prefix*} |
Expands to the names of variables whose names begin with prefix. |
|
|
Convert first character to lowercase. |
|
|
Convert all characters to lowercase. |
|
|
Convert first character to uppercase. |
|
|
Convert all character to uppercase. |
Cheatsheet: String Manipulation

String To Integer
# $((string))
sum=$((3+6))
echo $sum
a=11
b=3
c=$(($a+$b))
echo $cAlternate method: expr
Note that it is not a “native” Bash procedure, as you need to have
coreutilsinstalled (by default on Ubuntu) as a separate package.
a=5; b=3; c=2; d=1
expr $a + $b \* $c - $d去除變數的末端字元 .XXX
# Operator "#" means "delete from the left, to the first case of what follows."
x="This is my test string."
echo ${x#* }
is my test string.
# Operator "##" means "delete from the left, to the last case of what follows."
x="This is my test string."
echo ${x##* }
string.
# Operator "%" means "delete from the right, to the first case of what follows."
x="This is my test string."
echo ${x% *}
This is my test
# Operator "%%" means "delete from the right, to the last case of what follows."
x="This is my test string."
$ echo ${x%% *}
Thisloop
for loop
for i in var1 var2 var3; do echo $i; done
for ((i=1;i<=10;i++)); do echo $i; done
for i in $(ls *.log); do echo $i; done
for t in {1..10};do echo $t; done
1
2
3
4
5
6
7
8
9
10
for t in {1..10..2};do echo $t; done
1
3
5
7
9
## 列出目前資料夾的所有目錄名稱
for dir in */;do echo "${dir%/}"; done
## Infinite Loop
for (( ; ; ))
do
echo "infinite loops [ hit CTRL+C to stop]"
donewhile loop
## 讀取檔案內容
cat tables_name.lst | while read sch tab;do
> echo "export to $tab.ixf of ixf messages export_$tab.msg select * from $sch.$tab"
> done
## while loop 的應用
## 每 3 秒監看 /worktmp 的磁碟使用狀況
while true;do
> df -h | grep /worktmp
> sleep 3
> done
## 管理 DB2 時常用
while read s t;do
> db2 "select count(*) from $s.$t"
> done < tables.lst > count-tables.out
## 如果是 CSV
while IFS=, read s t;do
> db2 "select count(*) from $s.$t"
> done < tables.csv > count-tables.out
## 迴圈計數 Loop Counter
x=1
while [ $x -le 5 ]
do
echo "Welcome $x times"
x=$(( $x + 1 )) 或者 x=$[$x + 1]
done
## 內容排序後導入迴圈
## <(sort -r lost.txt) 檔案內容預處理
while IFS='.' read -r a b c d e;do
> echo "$a";
> done < <(sort -r lost.txt)
## 讀取整行
filename=$1
while read line; do
# reading each line
echo $line
done < $filename
## Reading file by omitting backslash escape
while read -r line; do
# Reading each line
echo $line
done < company2.txtuntil loop
until [[ $a -eq 1 ]]
do
echo "Value of a is $a"
let a--
doneInfinite loop 無限迴圈
# while
while true
do
echo "Hi"
sleep 2s #will run every 2 sec
done
# for
for (( ;; ))
do
echo "Hi buddy"
sleep 2s
donebreak and continue
count=0
until false
do
((count++))
if [[ $count -eq 5 ]]
then
continue
elif [[ $count -ge 10 ]]
then
break
fi
echo "Counter = $count"
doneCounter = 1
Counter = 2
Counter = 3
Counter = 4
Counter = 6
Counter = 7
Counter = 8
Counter = 9For loop with array elements
DB_AWS_ZONE=('us-east-2a' 'us-west-1a' 'eu-central-1a')
for zone in "${DB_AWS_ZONE[@]}"
do
echo "Creating rds (DB) server in $zone, please wait ..."
aws rds create-db-instance \
--availability-zone "$zone"
--allocated-storage 20 --db-instance-class db.m1.small \
--db-instance-identifier test-instance \
--engine mariadb \
--master-username my_user_name \
--master-user-password my_password_here
doneLoop with a shell variable
_admin_ip="202.54.1.33|MUM_VPN_GATEWAY 23.1.2.3|DEL_VPN_GATEWAY 13.1.2.3|SG_VPN_GATEWAY"
for e in $_admin_ip
do
ufw allow from "${e%%|*}" to any port 22 proto tcp comment 'Open SSH port for ${e##*|}'
done進度條 progress bar
簡易版
echo -ne '>>> [20%]\r'
# some task
sleep 2
echo -ne '>>>>>>> [40%]\r'
# some task
sleep 2
echo -ne '>>>>>>>>>>>>>> [60%]\r'
# some task
sleep 2
echo -ne '>>>>>>>>>>>>>>>>>>>>>>> [80%]\r'
# some task
sleep 2
echo -ne '>>>>>>>>>>>>>>>>>>>>>>>>>>[100%]\r'
echo -ne '\n'顯示進度條1
#!/bin/bash
#
# inprogress.sh
# Description: this script may show some simple motion in foreground
# when main program in progress.
# Author: A-Lang (alang[dot]hsu[at]gmail[dot]com)
trap "kill $BG_PID;echo;exit" 1 2 3 15
function waiting
{
INTERVAL=0.5
TT='->——
–>—–
—>—-
—->—
—–>–
——>-
——->
——<-
—–<–
—-<—
—<—-
–<—–
-<——
<——-';
echo -ne "Please waiting… \n"
while true
do
for j in $TT
do
echo -ne "Please be patient, $j\r"
sleep $INTERVAL
done
done
}
# Start the waiting, where place your main program.
waiting &
BG_PID=$!
sleep 10
# End of the waiting
kill $BG_PID
echo顯示進度條2
#!/usr/bin/env bash
BATCHSIZE=1
progress-bar() {
local current=$1
local len=$2
local bar_char='|'
local empty_char=' '
local length=50
local perc_done=$((current * 100 / len))
local num_bars=$((perc_done * length / 100))
local i
local s='['
for ((i = 0; i < num_bars; i++)); do
s+=$bar_char
done
for ((i = num_bars; i < length; i++)); do
s+=$empty_char
done
s+=']'
echo -ne "\r$s $current/$len ($perc_done%)"
}
process-files() {
local files=("$@")
sleep .01
}
shopt -s globstar nullglob
echo 'finding files'
files=(./**/*cache)
len=${#files[@]}
echo "found $len files"
for ((i = 0; i < len; i += BATCHSIZE)); do
progress-bar "$((i+1))" "$len"
process-files "${files[@]:i:BATCHSIZE}"
done
progress-bar "$len" "$len"
echo旋轉符號
#!/usr/bin/env bash
spinner()
{
local pid=$!
local delay=${1:1}
local spinstr='|/-\'
while [ "$(ps a | awk '{print $1}' | grep $pid)" ]
do
local temp=${spinstr#?}
printf " [%c] " "$spinstr"
local spinstr=$temp${spinstr%"$temp"}
sleep $delay
printf "\b\b\b\b\b"
done
printf " \b\b\b\b"
}
# Run your program here
#(a_long_running_task) &
sleep 10 &
spinner 0.75整合 LED 的顯示
#!/bin/bash
echo "Starting to format the disk...."
# Start to blink the LED
/root/bin/led.sh b
/root/bin/led.sh blink &
led_pid=$!
# Main codes
echo "formating hdisk2..."
sleep 10
# When the main codes is ending up
# Stop to blink the LED
kill -9 $led_pid
wait $led_pid 2>/dev/null
sleep 2
# Making sure the LED is ON with Blue
/root/bin/led.sh b
echo "done"led.sh 用來控制 LED 的閃燈
wait .... 這行用來隱藏 killed ... 的文字訊息
find
檔案名稱
# Find all *.bak files in the current directory and removes them with confirmation
find . -type f -name "*.bak" -exec rm -i {} \;
# find all *.out, *.bak and *.core files and then delete them
find /projectA/ \( -name '∗.bak' -o -name '*.core' \) -exec rm "{}" \;檔名有包含空白, 換行符號等特殊字元時
find . -type f -name "*.err" -print0 | xargs -I {} -0 rm -v "{}"-print0: Force find command to print the full file name on the standard output, followed by a null character (instead of the newline character that -print uses). This allows file names that contain newlines or other types of white space to be correctly interpreted by programs that process the find output. This option corresponds to the -0 option of xargs.-I {}: Replace occurrences of {} in the initial-arguments with names read from standard input. We pass {} as arg to the rm command.-0: Input items are terminated by a null character instead of by whitespace, and the quotes and backslash are not special (every character is taken literally). Disables the end of file string, which is treated like any other argument. Useful when input items might contain white space, quote marks, or backslashes. The GNU find -print0 option produces input suitable for this mode.rm -v "{}": Run rm command on matched files.
排除特定附檔名
find . ! -name '*.mp3' -type f | xargs cp -t Misc/檔案大小
找出大於 1000 MB 的檔案
find / -type f -size +1000M
find . -type f -size +50000k -exec ls -lh {} \; | awk '{ print $9 ": " $5 }'列出空間使用最高的檔案與目錄的清單
find . -type f -exec wc -c {} \; | sort -nr | head
# show all files/folders in current directory on current filesystem ordered by size
find . -maxdepth 1 -mindepth 1 \( -type d -o -type f \) \( -exec mountpoint -q {} \; -o -exec du -smx {} \; \) | sed "s|./||" | sort -n
# With du
du -xak . |sort -n | tail -50
du -xah . | sort -rh | head -10檔案時間
搬移指定日期範圍的檔案
將修改日期是 2012 - 2014 的所有檔案搬移至 /export_data/2012-2014
touch --date "2012-01-01" /tmp/start
touch --date "2015-01-01" /tmp/end
find /home/ams/ipdr -type f -newer /tmp/start -not -newer /tmp/end > 2012-2014.lst
find /home/ams/ipdr -type f -newer /tmp/start -not -newer /tmp/end -exec cp -a {} /export_data/2012-2014 \;
find /home/ams/ipdr -type f -newer /tmp/start -not -newer /tmp/end -exec rm -f {} \;列出 2018-03-20 至 2018-04-10 期間曾修改過的檔案
find ~/ -xdev -newermt 2018-03-20 \! -newermt 2018-04-10 -type f -ls列出 365天以前/20分鐘以前 的所有檔案
find ./ -ctime +365 -ls
find ./ -cmin +20 -ls- ctime 檔案建立時間
- mtime 最近檔案修改時間
- atime 最近存取檔案時間
找尋3日內曾異動過的檔案,並轉換 Excel format(csv)
find . -xdev -mtime -3 -ls > found.list
sed 's/^[ ]*//g;s/[ ][ ]*/ /g' found.list | awk '{print $3","$5","$6","$7","$8" "$9","$10","$11}' > found.list.csv列出剛剛異動過的檔案
# 最近 5 分鐘異動過的檔案(包含權限與新增檔案)
find dir -cmin -5
# 最近 10 分鐘修改過的檔案
find dir -mmin 10目錄 data 內有許多以日期命名的小 log,需要將去年的所有 log 搬到新目錄 archive-2013
註:排除目錄 ./archive-2013
cd data/
mkdir archive-2013
find ./ -path "./archive-2013" -prune -o -name "dcdb_13*" -exec mv {} archive-2013 \;要排除多個目錄時可以改成
find ./ \( -path "./dir1" -o -path "./dir2" \) -prune -o -name "dcdb_13*" -exec mv {} archive-XXXX \;
按時間先後作排序
find /istrpt/arlog/ -name "*.LOG" -print | xargs ls -lt檔案權限
列出 0777 的目錄
find . -type d -perm 0777 -ls指定權限的檔案
find ~/UbuntuMint -type f -perm 600
find ~/UbuntuMint -type f -perm 111
find ~/UbuntuMint -type f -perm 644
# Use the "-" minus prefix before the file permissions to list all
# the files that possess at least read and write permissions for the file owner.
find ~/UbuntuMint -type f -perm -600
# This "/" will retrieve files within the "UbuntuMint" directory where
# at least one of the categories (owner, group, or others) meets the specified permission bits
find ~/UbuntuMint -type f -perm /600
find ~/UbuntuMint -type f -perm u=rw,g=r,o=r
find ~/UbuntuMint -type f -perm u+rw,g+r,o+r整合其他指令
# use find to list sha256sum files only
find . -type f -exec sha256sum {} +
# search for and get rid of duplicate .jpg files
find . -type f -name '*.jpg' -exec sha256sum {} + | sort -uk1,1特定帳號的檔案
# -xdev 需指定目錄,可以避免 NAS/proc 等目錄
# NOTE: 使用 / 目錄,會使 xdev 失效
find /sp1 /home -xdev -user i00001排除隱藏目錄檔案
定期清除 Archive Log Files
# For Cron on Linux
*/30 * * * * find /istfdc/FDCDB/arclog/istfdc/FDCDB -name "*.LOG" -cmin +60 -exec rm -f {} \;
# For Cron on AIX
50 09 * * * find /istit1/archiveLog/smdb -name "*.LOG" -ctime +5 -exec rm -f {} \\;uniq
uniq 與 sort 一起使用時,可以控制那些重複的資訊。
基本操作
$ cat file2
ChhatrapatiShahuMaharaj
Dr.B.R.Ambedkar
Budhha
Dr.B.R.Ambedkar
Budhha
Dr.B.R.Ambedkar
Budhha
$ uniq file2
ChhatrapatiShahuMaharaj
Dr.B.R.Ambedkar
Budhha
Dr.B.R.Ambedkar
Budhha
Dr.B.R.Ambedkar
Budhha
$ sort file2
Budhha
Budhha
Budhha
ChhatrapatiShahuMaharaj
Dr.B.R.Ambedkar
Dr.B.R.Ambedkar
Dr.B.R.Ambedkar
$ sort file2 | uniq
Budhha
ChhatrapatiShahuMaharaj
Dr.B.R.AmbedkarWith -c, --count option
# using the -c option to count the repeated lines
$ sort file2 | uniq -c
3 Budhha
1 ChhatrapatiShahuMaharaj
3 Dr.B.R.AmbedkarWith -d, --repeated option
# The -d option prints only lines that are repeated.
$ sort file2 | uniq -d
Budhha
Dr.B.R.Ambedkar
# using the -c option to cross-check whether the -d option is only printing the repeated lines or not
$ sort file2 | uniq -cd
3 Budhha
3 Dr.B.R.AmbedkarWith -D, --all-repeated option
# The -D option prints repeated lines and discards the non-duplicate lines
$ sort file2 | uniq -D
Budhha
Budhha
Budhha
Dr.B.R.Ambedkar
Dr.B.R.Ambedkar
Dr.B.R.AmbedkarWith -u, --unique option
# the -u option prints unique lines i.e., non-duplicate lines
$ sort file2 | uniq -u
ChhatrapatiShahuMaharajWith -i, --ignore-case option
# Using the -i option, we can ignore the case sensitivity of characters
$ cat file3
aaaa
aaaa
AAAA
AAAA
bbbb
BBBB
$ uniq file3
aaaa
AAAA
bbbb
BBBB
$ uniq -i file3
aaaa
bbbbWith -f, --skip-fields=N
# skip some fields to filter duplicate lines
$ cat file5
Amit aaaa
Ajit aaaa
Advi bbbb
Kaju bbbb
$ uniq file5
Amit aaaa
Ajit aaaa
Advi bbbb
Kaju bbbb
$ uniq -f 1 file5
Amit aaaa
Advi bbbbWith -s, --skip-char=N option
# skip characters
$ cat file4
22aa
33aa
44bb
55bb
$ uniq file4
22aa
33aa
44bb
55bb
$ uniq -s 2 file4
22aa
44bbWith -w, --check-chars=N option
# consider characters as well using the -w option
$ cat file6
aa12
aa34
bb56
bb78
$ uniq file6
aa12
aa34
bb56
bb78
$ uniq -w 2 file6
aa12
bb56
date
Shell 範例
# Sample
today=$(date +%Y/%m/%d)
NOW=`date "+%Y/%m/%d %H:%M:%S"`
eval `date "+day=%d; month=%m; year=%Y"`
BKNAME="cacti-backup-$year-$month-$day.tar.gz"
# Sample
# %T time; same as %H:%M:%S
NOWD=$(date +"%F") # YYYY-MM-DD
NOWT=$(date +"%T") # H:M:S
#
eggs="202/07/29"
days="20 days"
echo "Eggs expiry date $(date -d "${eggs}+${days}")"將 Date 轉換為 EPOCH 時間格式
## Date to Epoch
# 用 perl 可用於 AIX
perl -e 'use Time::Local; print timelocal(0,25,1,11,11,2008), "\n";'
# On Linux
# Current date
date +%s
# For specified date
date --date="2023/11/1" +%sFor AIX
Time2Epoch() {
local dtime yyyy mm dd HH MM SS
dtime="$1"
yyyy=$(echo "$dtime" | cut -d ' ' -f1 | cut -d '/' -f1)
mm=$(echo "$dtime" | cut -d ' ' -f1 | cut -d '/' -f2)
dd=$(echo "$dtime" | cut -d ' ' -f1 | cut -d '/' -f3)
HH=$(echo "$dtime" | cut -d ' ' -f2 | cut -d ':' -f1)
MM=$(echo "$dtime" | cut -d ' ' -f2 | cut -d ':' -f2)
SS=$(echo "$dtime" | cut -d ' ' -f2 | cut -d ':' -f3)
echo $(perl -e 'use Time::Local; ($yyyy, $mm, $dd, $HH, $MM, $SS)=@ARGV; $tm=timelocal($SS, $MM, $HH, $dd, $mm - 1, $yyyy); print "$tm";' $yyyy $mm $dd $HH $MM $SS)
return
}
Epoch2Date() {
local epochtime datetime
epochtime=$1
datetime=
if [ -n "$epochtime" ]
then
datetime=$(perl -le 'print scalar localtime $ARGV[0]' ${epochtime})
fi
echo $datetime
}常用日期格式
date +"%D %T"
02/04/21 01:42:52
date "+%y-%m-%d_%H%M%S"
17-05-22_105503
date "+%Y/%m/%d"
2015/07/17
date "+%F"
2015-07-17
# Display past date
date --date="49 days ago"
日 9月 11 16:17:02 CST 2016
date --date="1 month ago"
五 9月 30 16:17:34 CST 2016
# Display future date
date --date="next fri"
五 2月 5 00:00:00 CST 2021
date --date='TZ="America/New_York" 10:00 next fri'
五 2月 5 23:00:00 CST 2021計算程式執行所花費的時間
start=`date "+%Y/%m/%d %H:%M:%S"`
start_s=$(date -d "$start" +%s)
Sleep 20
end=`date "+%Y/%m/%d %H:%M:%S"`
end_s=$(date -d "$end" +%s)
diff=$((end_s - start_s))Parallel and Multi-thread
GNU Parallel
Official: https://www.gnu.org/software/parallel/
Download: http://ftp.gnu.org/gnu/parallel/
Install
# CentOS 7
yum group install "Development Tools"
wget http://ftp.gnu.org/gnu/parallel/parallel-latest.tar.bz2
tar xjf parallel-latest.tar.bz2
cd parallel-*
./configure --prefix=/usr/local
make
make install
Don't change the --prefix if you want to use Man to view the manual of the command.
Use case: The common use case I have is to bzip a large file using Parallels. Files with 40 millions rows (8 GB) are compressed to 400MB bz2 files.
cat largefile.csv | /usr/local/bin/parallel --pipe -k bzip2 --best > largefile.bz2Use case: my custom shell
One-liner)
# ./gen_mm_log_insert.v5.sh <input-file> <output-dir>
cat files.lst | parallel -j3 "./gen_mm_log_insert.v5.sh raws/{} output/"Shell Script)
num_processes=3
ls $locdir/mmsevent* | /usr/local/bin/parallel -j $num_processes "./gen_mm_log_insert.v5.sh {} $outputdir"
ls $locdir/mmsevent* | /usr/local/bin/parallel -j $num_processes 'a={}; name=${a##*/};' \
'./gen_mm_log_insert.v5.sh {} "'$outputdir'" 2>"'$logdir'/err.${name}.log"'With Bash
# Multiple files *.lst with lots of file paths such as
# cat 1.lst
# /path/to/file1
# /path/to/file2
# /path/to/file3
#
files="$@"
## An arbitrary limiting factor so that there are some free processes
## in case I want to run something else
num_processes=3
#
echo "Parallel Processing with $num_processes threads (`date "+%F %T"`)"
for lst in $files
do
for f in $(cat $lst | sed '/^#/d')
do
((i=i%num_processes)); ((i++==0)) && wait
yourshell.sh $f &
done
sleep 120
done
Installation
常用的寄送 mail 指令套件:
- mailutils: 支援 HTML 格式的郵件,不支援外部 SMTP 連線
- Heirloom-mailx: RHEL 7/8 內建指令,不支援 HTML 格式的郵件,有支援連線外部 SMTP server。
- BSD-mailx: 支援 HTML 格式的郵件,不支援外部 SMTP 連線
- Mutt: 支援 HTML 格式的郵件
- Sendmail: 支援 HTML 格式的郵件,不支援外部 SMTP 連線
sudo apt install mailutils # [On Debian, Ubuntu and Mint]
sudo yum install mailx # [On RHEL/CentOS/Fedora and Rocky Linux/AlmaLinux]
sudo emerge -a mail-client/mailx # [On Gentoo Linux]
sudo pacman -S mailutils # [On Arch Linux]
sudo zypper install mailutils # [On OpenSUSE] Alternative mailx
Debian 系統預設 mailx 為 heirloom-mailx,因為無法寄送 HTML Mail 格式,想改成 mailutils。
root@A2B:~/bin# dpkg --get-selections | grep mail
bsd-mailx deinstall
heirloom-mailx install
libmail-sendmail-perl install
libmailtools-perl install
libmailutils4 install
mailutils install
mailutils-common install
root@A2B:~/bin# update-alternatives --display mailx
mailx - auto mode
link currently points to /usr/bin/heirloom-mailx
/usr/bin/heirloom-mailx - priority 60
slave Mail: /usr/bin/heirloom-mailx
slave Mail.1.gz: /usr/share/man/man1/heirloom-mailx.1.gz
slave mail: /usr/bin/heirloom-mailx
slave mail.1.gz: /usr/share/man/man1/heirloom-mailx.1.gz
slave mailx.1.gz: /usr/share/man/man1/heirloom-mailx.1.gz
/usr/bin/mail.mailutils - priority 30
slave mail: /usr/bin/mail.mailutils
slave mail.1.gz: /usr/share/man/man1/mail.mailutils.1.gz
slave mailx.1.gz: /usr/share/man/man1/mail.mailutils.1.gz
Current 'best' version is '/usr/bin/heirloom-mailx'.
root@A2B:~/bin# update-alternatives --config mailx
There are 2 choices for the alternative mailx (providing /usr/bin/mailx).
Selection Path Priority Status
------------------------------------------------------------
* 0 /usr/bin/heirloom-mailx 60 auto mode
1 /usr/bin/heirloom-mailx 60 manual mode
2 /usr/bin/mail.mailutils 30 manual mode
Press enter to keep the current choice[*], or type selection number: 2
update-alternatives: using /usr/bin/mail.mailutils to provide /usr/bin/mailx (mailx) in manual mode驗證套件版本
root@A2B:~/bin# update-alternatives --display mailx
mailx - manual mode
link currently points to /usr/bin/mail.mailutils
/usr/bin/heirloom-mailx - priority 60
slave Mail: /usr/bin/heirloom-mailx
slave Mail.1.gz: /usr/share/man/man1/heirloom-mailx.1.gz
slave mail: /usr/bin/heirloom-mailx
slave mail.1.gz: /usr/share/man/man1/heirloom-mailx.1.gz
slave mailx.1.gz: /usr/share/man/man1/heirloom-mailx.1.gz
/usr/bin/mail.mailutils - priority 30
slave mail: /usr/bin/mail.mailutils
slave mail.1.gz: /usr/share/man/man1/mail.mailutils.1.gz
slave mailx.1.gz: /usr/share/man/man1/mail.mailutils.1.gz
Current 'best' version is '/usr/bin/heirloom-mailx'.
root@A2B:~/bin# mail --version
mail (GNU Mailutils) 2.99.97
Copyright (C) 2010 Free Software Foundation, inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.Text Mail
echo "MAIL BODY" | mail -s 'MAIL SUBJECT' receiver@domain_name
# Enter DOT or Ctrl-d to exit the CLI
mail -s "Test mail" receiver@domain_nameHTML Mail
NOTE: RHEL 7+ 的 mailx 指令無法寄送 HTML 格式的郵件;改用 mutt 或 sendmail.postfix。
mailx (舊版)
echo "<b>HTML Message goes here</b>" | mail -s "$(echo -e "This is the subject\nContent-Type: text/html")" receiver@domain_namesendmail for Postfix
NOTE: 如果系統使用 postfix 作為 MTA 時,指令改成 sendmail.postfix。
檢查 sendmail 的版本
┌──[root@tpedevdb02:/worktmp/my_shell]
└─# which sendmail
/usr/sbin/sendmail
┌──[root@tpedevdb02:/worktmp/my_shell]
└─# readlink /usr/sbin/sendmail
/etc/alternatives/mta
┌──[root@tpedevdb02:/worktmp/my_shell]
└─# update-alternatives --display mta
mta - status is auto.
link currently points to /usr/sbin/sendmail.postfix
/usr/sbin/sendmail.postfix - priority 30
slave mta-mailq: /usr/bin/mailq.postfix
slave mta-newaliases: /usr/bin/newaliases.postfix
slave mta-pam: /etc/pam.d/smtp.postfix
slave mta-rmail: /usr/bin/rmail.postfix
slave mta-sendmail: /usr/lib/sendmail.postfix
slave mta-mailqman: /usr/share/man/man1/mailq.postfix.1.gz
slave mta-newaliasesman: /usr/share/man/man1/newaliases.postfix.1.gz
slave mta-sendmailman: /usr/share/man/man1/sendmail.postfix.1.gz
slave mta-aliasesman: /usr/share/man/man5/aliases.postfix.5.gz
Current `best' version is /usr/sbin/sendmail.postfix.Sample #1
(
echo "To: user@example.com"
echo "Subject: HTML test"
echo "Content-Type: text/html"
echo
cat file.html
) | sendmail.postfix -t
Sample #2
echo "FROM: info@mediasystemsfl.com
To: $email
Subject: $subject
Content-Type: text/html; charset=utf-8
<!DOCTYPE html>
<html><head>
<title>$subject</title>
<body>
<pre>
### Attention: Do not reply to this message. ###
$(Show_head)
$(Gen_asr_report)
NOTE: The symbol '<<<' indicates an ASR(Answer-Seizure Ratio) of less than $thre%.
</pre>
</body>
</html>
" | /usr/sbin/sendmail -tmutt on RHEL 7
echo "<b>HTML Message goes here</b>" | mutt -s "Test HTML Mail" -e "my_hdr Content-Type: text/html" user@my.comFunctions
# Show_head & Gen_asr_report are custom functions.
Send_mail() {
subject="This is Mail Subject"
email="user@email.com"
echo -e "
### Attention: Do not reply to this message. ###
$(Show_head)
$(Gen_asr_report)
NOTE: The symbol '<<<' indicates an ASR(answer-seizure ratio) of less than $thre%.
" | /usr/bin/mail -s "$subject" "$email"
}Via SMTP Server
RHEL 7/8 內建的 Heirloom-mailx 支援不需要使用本地的 MTA 服務就可以外寄郵件。
一般沒有認證與加密的 SMTP
mail -v -S smtp=smtp://192.168.21.7:25 -s "Test SMTP" user@domain.tld認證且有加密的 SMTP
新增 ~/.mailrc 或全域環境 /etc/mail.rc (以 Gmail 為例)
set smtp-use-starttls
set ssl-verify=ignore
set smtp=smtp://smtp.gmail.com:587
set smtp-auth=login
set smtp-auth-user=$FROM_EMAIL_ADDRESS
set smtp-auth-password=$EMAIL_ACCOUNT_PASSWORD
set from="$FROM_EMAIL_ADDRESS($FRIENDLY_NAME)"Perl
Tutorials
lsof
Network Port
What process is using the port 50000
lsof -i :50000
lsof -i :https
lsof -i tcp:25
lsof -i udp:53
lsof -i :1-1024
lsof -i udpMount Point
What process is using the mount-point
lsof | grep /path/to/mount-point
lsof +f -- /path/to/dir
lsof +D /path/to/dir
# List all NFS files
lsof -NProcess
What files and directories are using by the process
lsof -p `pidof <app_name>`
lsof -c apache
lsof | grep apache
# list Parent PID of processes
lsof -p [PID] -RUser
# List files opened by processes belonging to a specific user
lsof -u [user-name]
lsof -a -i -u www-dataIP & Domain
List files based on their Internet address
# For IPv4
lsof -i 4
# For IPv6
lsof -i 6File
lsof -t [file-name]
lsof -t /usr/lib/x86_64-linux-gnu/libpcre2-8.so.0.9.0
# Finding open files in a specific directory under Linux or Unix
lsof +D /path/to/dir/
# list any open files which have been removed or deleted
lsof -nP +L1
lsof -nP +L1 +D /path/to/dir/Memory
lsof -d mem算術
let
#!/usr/bin/env bash
let NUMBER1=10
let NUMBER2=3
# Addition => + operator
let ADD=$NUMBER1+$NUMBER2
echo "Addition of two numbers : ${ADD}"
# Subtraction => - operator
let SUB=$NUMBER1-$NUMBER2
echo "Subtraction of two numbers : ${SUB}"
# Multiply => * operator
let MUL=$NUMBER1*$NUMBER2
echo "Multiply two numbers : ${MUL}"
# Divide => / operator
let DIV=$NUMBER1/$NUMBER2
echo "Division of two numbers : ${DIV}"
# Remainder (餘數) => % operator
let REM=$NUMBER1%$NUMBER2
echo "Remainder of two numbers : ${REM}"
# Exponent => ** operator
let EXPO=$NUMBER1**$NUMBER2
echo "Exponent of two numbers : ${EXPO}"
# post increment and post decrement operations
let variable++
let variable--Double Brackets
雙括號,必須是整數型態
((NUMBER2++)
((NUMBER1--))
(( NUMBER2 = NUMBER2 + 10 ))
(( NUMBER2 += 10 )) # Shorthandexpr
必須是整數型態
expr 10 + 3 # Addition
expr 10 - 3 # Subtraction
expr 10 * 3 # Multiply
expr 10 / 3 # Divide
expr 10 % 3 # Remainderbc
# Add
$ echo "10 + 100" | bc
=> 110
$ echo "10.15 + 11.20" | bc
21.35
# Subtract
$ echo "100 - 25" | bc
=> 75
$ echo "100 - 25.5" | bc
=> 74.5
# Multiply
$ echo "10 * 5" | bc
=> 50
$ echo "10.10 * 4" | bc
=> 40.40
# without scale
echo "10.10 / 4" | bc
=> 2
# with scale
echo "scale=2;10.10 / 4" | bc
=> 2.52
$ echo "2.2^4" | bc
=> 23.4awk
$ awk "BEGIN {print 23 * 4.5 }"
=> 103.5
$ awk "BEGIN{print int(10.111) }"
=> 10
$ awk "BEGIN{print sqrt(10) }"
=> 3.16228
# Since this is a CSV file, I am setting the field separator to(-F “,”).
# Here the entire second column is first added and divided by the NR(number of records).
$ awk -F "," '{sum+=$2} END { print "average value from column 2 = ",sum/NR}' data.csvRounding 取整數
| 除法取整數方法 | X / Y (3 / 2) = 1.5 |
| 無條件捨去 (floor rouding) | X / Y , (3 / 2) = 1 |
| 無條件進位 (ceiling rouding) | (X + Y – 1) / Y , (3 + 2 - 1) / 2 = 2 |
| 四捨五入 (half-up rouding) | (X + Y / 2) / Y , (3 + 2 / 2) / 2 = 2 |
# 將 float 轉成 integer
## Way #1
float_num = 12.63333
round_num = $(printf "%.0f" $float_num)
# round_num is 13
## Way #2
float_num = 12.63333
round_num = ${float_num%%.*}
# round_num is 12
# 整數相除 3/2 後取整數值 (無條件捨去)
X=3
Y=2
echo $(( X / Y ))
# Output 1
# 整數相除 3/2 後取整數值 (四捨五入)
echo $(( (X + Y / 2) / Y ))
# Output 2Diagrams
Linux Shell Lifecycle
ANSI Color
高亮文字
highlight() {
mode=$1
string="$2"
case "$mode" in
red) echo -e "\033[0;101m${string}\033[0m";;
green) echo -e "\033[0;102m${string}\033[0m";;
black_yellow) echo -e "\033[33;5;7m${string}\033[0m";;
*) echo $string
esac
}
highlight "green" "Version 1.0.0"
Scripts
echo -e "\033[0;0m -- 0 » no style --\033[0;0m"
echo -e "\033[0;1m -- 1 » white:bolded --\033[0;0m"
echo -e "\033[0;2m -- 2 » white:dimmed --\033[0;0m"
echo -e "\033[0;3m -- 3 » white:italic --\033[0;0m"
echo -e "\033[0;4m -- 4 » white:underline --\033[0;0m"
echo -e "\033[0;5m -- 5 » white:slow blink --\033[0;0m"
echo -e "\033[0;6m -- 6 » white:rapid blink --\033[0;0m"
echo -e "\033[0;7m -- 7 » white background aka 'invert' --\033[0;0m"
echo -e "\033[0;8m -- 8 » hidden --\033[0;0m"
echo -e "\033[0;9m -- 9 » white 'alternate font' --\033[0;0m"
echo -e "\033[0;10m -- 10 » white 'alternate font' --\033[0;0m"
echo -e "\033[0;11m -- 11 » white 'alternate font' --\033[0;0m"
echo -e "\033[0;12m -- 12 » white 'alternate font' --\033[0;0m"
echo -e "\033[0;13m -- 13 » white 'alternate font' --\033[0;0m"
echo -e "\033[0;14m -- 14 » white 'alternate font' --\033[0;0m"
echo -e "\033[0;15m -- 15 » white 'alternate font' --\033[0;0m"
echo -e "\033[0;16m -- 16 » white 'alternate font' --\033[0;0m"
echo -e "\033[0;17m -- 17 » white 'alternate font' --\033[0;0m"
echo -e "\033[0;18m -- 18 » white 'alternate font' --\033[0;0m"
echo -e "\033[0;19m -- 19 » white 'alternate font' --\033[0;0m"
echo -e "\033[0;20m -- 20 » white:Gothic --\033[0;0m"
echo -e "\033[0;21m -- 20 » white:double underline --\033[0;0m"
echo -e "\033[0;22m -- 20 » white:normal intensity --\033[0;0m"
echo -e "\033[0;23m -- 20 » white:Neither italic, nor blackletter --\033[0;0m"
echo -e "\033[0;24m -- 20 » white:Not underlined --\033[0;0m"
echo -e "\033[0;25m -- 20 » white:Not blinking --\033[0;0m"
echo -e "\033[0;26m -- 20 » white:Proportional spacing --\033[0;0m"
echo -e "\033[0;27m -- 20 » white:Not reversed --\033[0;0m"
echo -e "\033[0;28m -- 20 » white:Reveal --\033[0;0m"
echo -e "\033[0;29m -- 20 » white:Not crossed out --\033[0;0m"
echo -e "\033[0;30m -- 30 » black --\033[0;0m (-- 30 » black --) "
echo -e "\033[0;31m -- 31 » red --\033[0;0m"
echo -e "\033[0;32m -- 32 » green --\033[0;0m"
echo -e "\033[0;33m -- 33 » yellow --\033[0;0m"
echo -e "\033[0;34m -- 34 » blue --\033[0;0m"
echo -e "\033[0;35m -- 35 » magenta --\033[0;0m"
echo -e "\033[0;36m -- 36 » teal --\033[0;0m"
echo -e "\033[0;37m -- 37 » grey --\033[0;0m"
echo -e "\033[0;38m -- 38 » white --\033[0;0m"
echo -e "\033[0;39m -- 39 » white/default color --\033[0;0m"
echo -e "\033[0;40m -- 40 » black background? --\033[0;0m"
echo -e "\033[0;41m -- 41 » red background --\033[0;0m"
echo -e "\033[0;42m -- 42 » green background --\033[0;0m"
echo -e "\033[0;43m -- 43 » yellow background --\033[0;0m"
echo -e "\033[0;44m -- 44 » blue background --\033[0;0m"
echo -e "\033[0;45m -- 45 » magenta background --\033[0;0m"
echo -e "\033[0;46m -- 46 » teal background --\033[0;0m"
echo -e "\033[0;47m -- 47 » grey background --\033[0;0m"
echo -e "\033[0;48m -- 48 » Set background color --\033[0;0m"
echo -e "\033[0;49m -- 49 » default background --\033[0;0m"
echo -e "\033[0;50m -- 50 » Disable proportional spacing --\033[0;0m"
echo -e "\033[0;51m -- 51 » Framed --\033[0;0m"
echo -e "\033[0;52m -- 52 » Encircled --\033[0;0m"
echo -e "\033[0;53m -- 53 » Overlined --\033[0;0m"
echo -e "\033[0;54m -- 54 » Neither framed nor encircled --\033[0;0m"
echo -e "\033[0;55m -- 55 » Not overlined --\033[0;0m"
echo -e "\033[0;56m -- 56 » undefined --\033[0;0m"
echo -e "\033[0;57m -- 57 » undefined --\033[0;0m"
echo -e "\033[0;58m -- 58 » Set underline color --\033[0;0m"
echo -e "\033[0;59m -- 59 » Default underline color --\033[0;0m"
echo -e "\033[0;60m -- 60 » Ideogram underline or right side line --\033[0;0m"
echo -e "\033[0;61m -- 61 » Ideogram double underline, or double line on the right side --\033[0;0m"
echo -e "\033[0;62m -- 62 » Ideogram overline or left side line --\033[0;0m"
echo -e "\033[0;63m -- 63 » Ideogram double overline, or double line on the left side --\033[0;0m"
echo -e "\033[0;64m -- 64 » Ideogram stress marking --\033[0;0m"
echo -e "\033[0;65m -- 65 » No ideogram attributes --\033[0;0m"
echo -e "\033[0;66m -- 66 » undefined --\033[0;0m"
echo -e "\033[0;67m -- 67 » undefined --\033[0;0m"
echo -e "\033[0;68m -- 68 » undefined --\033[0;0m"
echo -e "\033[0;69m -- 69 » undefined --\033[0;0m"
echo -e "\033[0;70m -- 70 » undefined --\033[0;0m"
echo -e "\033[0;71m -- 71 » undefined --\033[0;0m"
echo -e "\033[0;72m -- 72 » undefined --\033[0;0m"
echo -e "\033[0;73m -- 73 » Superscript --\033[0;0m"
echo -e "\033[0;74m -- 74 » Subscript --\033[0;0m"
echo -e "\033[0;75m -- 75 » Neither superscript nor subscript --\033[0;0m"
echo -e "\033[0;76m -- 76 » undefined --\033[0;0m"
echo -e "\033[0;77m -- 77 » undefined --\033[0;0m"
echo -e "\033[0;78m -- 78 » undefined --\033[0;0m"
echo -e "\033[0;79m -- 79 » undefined --\033[0;0m"
echo -e "\033[0;80m -- 80 » undefined --\033[0;0m"
echo -e "\033[0;81m -- 81 » undefined --\033[0;0m"
echo -e "\033[0;82m -- 82 » undefined --\033[0;0m"
echo -e "\033[0;83m -- 83 » undefined --\033[0;0m"
echo -e "\033[0;84m -- 84 » undefined --\033[0;0m"
echo -e "\033[0;85m -- 85 » undefined --\033[0;0m"
echo -e "\033[0;86m -- 86 » undefined --\033[0;0m"
echo -e "\033[0;87m -- 87 » undefined --\033[0;0m"
echo -e "\033[0;88m -- 88 » undefined --\033[0;0m"
echo -e "\033[0;89m -- 89 » undefined --\033[0;0m"
echo -e "\033[0;90m -- 90 » Set bright foreground color - grey --\033[0;0m"
echo -e "\033[0;91m -- 91 » Set bright foreground color - red --\033[0;0m"
echo -e "\033[0;92m -- 92 » Set bright foreground color - green --\033[0;0m"
echo -e "\033[0;93m -- 93 » Set bright foreground color - yellow --\033[0;0m"
echo -e "\033[0;94m -- 94 » Set bright foreground color - blue --\033[0;0m"
echo -e "\033[0;95m -- 95 » Set bright foreground color - magenta --\033[0;0m"
echo -e "\033[0;96m -- 96 » Set bright foreground color - teal --\033[0;0m"
echo -e "\033[0;97m -- 97 » Set bright foreground color - white --\033[0;0m"
echo -e "\033[0;98m -- 98 » undefined --\033[0;0m"
echo -e "\033[0;99m -- 99 » undefined --\033[0;0m"
echo -e "\033[0;100m -- 100 » Set bright background color - grey --\033[0;0m"
echo -e "\033[0;101m -- 101 » Set bright background color - red --\033[0;0m"
echo -e "\033[0;102m -- 102 » Set bright background color - green --\033[0;0m"
echo -e "\033[0;103m -- 103 » Set bright background color - yellow --\033[0;0m"
echo -e "\033[0;104m -- 104 » Set bright background color - blue --\033[0;0m"
echo -e "\033[0;105m -- 105 » Set bright background color - magenta --\033[0;0m"
echo -e "\033[0;106m -- 106 » Set bright background color - teal --\033[0;0m"
echo -e "\033[0;107m -- 107 » Set bright background color - white --\033[0;0m"
echo -e "\033[0;108m -- 108 » undefined --\033[0;0m"
echo -e "\033[0;109m -- 109 » undefined --\033[0;0m"Cheat Sheets
Bash Parameter

Bash Loops

Bash Basics
Bash Brackets (括號)

Bash Functions
