RAG
檢索增強生成 - Retrieval Augmented Generation
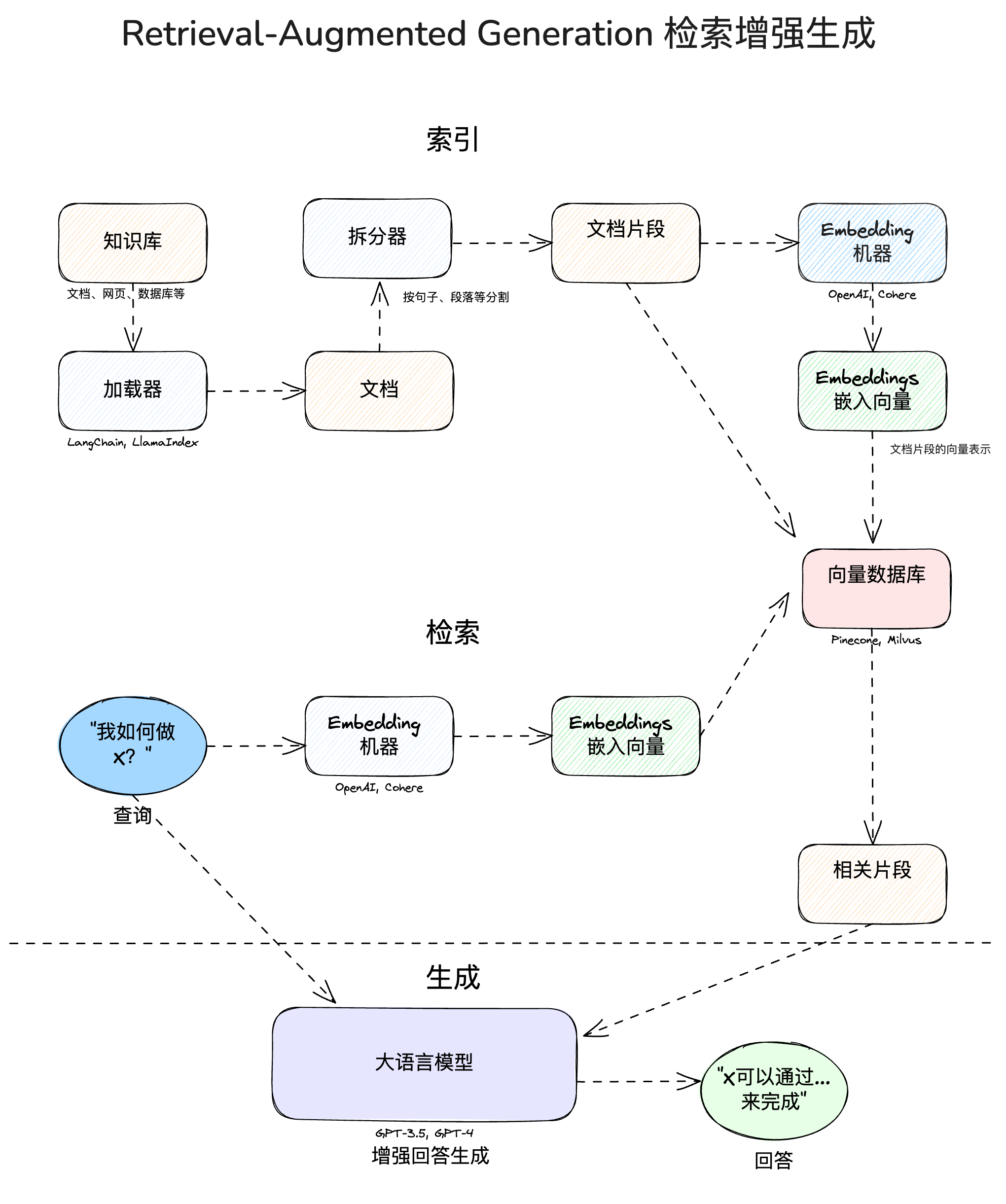
RAG 主要用來解決大型語言模型(LLM)實際應用時的兩大侷限:幻覺/錯覺(hallucination)與資料時限。RAG 結合「資訊檢索(retrieval)」和「生成(generation)」:在文字生成之前,先從資料庫中檢索相關的資料放入上下文,以確保 LLM 可依照正確的最新資訊生成結果。
RAG 優點:
- 降低 AI 幻覺
- 提升資料數據安全
- 減少模型微調
- 改善資料時限
流程示意圖
Introduction
Tutorials
Introduction to RAG
- ollama + Langchain + Gradio RAG 程式碼範例
- A flexible Q&A-chat-app for your selection of documents with langchain, Streamlit and chatGPT | by syrom | Medium
- 【圖解】4步驟教人資打造AI法律顧問!讓你的ChatGPT不再胡說八道|數位時代 BusinessNext (bnext.com.tw)
- 創建本地PDF Chatbot with Llama3 & RAG技術 #chatbot #chatgpt #llama3 #rag #chatpdf - YouTube
- 一些程式範例:https://github.com/Shubhamsaboo/awesome-llm-apps
- Easy AI/Chat For Your Docs with Langchain and OpenAI in Python
- RAG共学一:16个问题帮你快速入门RAG
- YT:RAG共学一:16个问题帮你快速入门RAG - YouTube
- 全端 LLM 應用開發-Day26-用 Langchain 來做 PDF 文件問答 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天 (ithome.com.tw)
- RAG實作教學,LangChain + Llama2 |創造你的個人LLM | by ChiChieh Huang | Medium
- Python RAG Tutorial (with Local LLMs): AI For Your PDFs - YouTube
- 對 PDF 的文字、表格與圖片向量化進行檢索
Embedding/Rerank Models
Vector Databases
- Qdrant - 一個開源的向量搜索引擎,旨在處理高維數據。有GUI管理介面。
- Chroma
- VectorAdmin - 向量資料庫管理介面 (嵌入模型僅支援 OpenAI)
- Pinecone (Cloud)
- Supabase (Cloud)
- Astra DB (Cloud)
Advanced RAG
Advanced RAG: MultiQuery and ParentDocument | RAGStack | DataStax Docs Advanced Retrieval With LangChain (ipynb) Advanced RAG Implementation using Hybrid Search, Reranking with Zephyr Alpha LLM | by Nadika Poudel | Medium
ReRank
Chunking/Splitting
- Mastering RAG: Advanced Chunking Techniques for LLM Applications - Galileo (rungalileo.io)
- 5 Levels Of Text Splitting (ipynb)
RAG Projects
Danswer
Danswer is the AI Assistant connected to your company's docs, apps, and people. Danswer provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud.
Embedchain
Embedchain streamlines the creation of personalized LLM applications, offering a seamless process for managing various types of unstructured data.
GraphRAG
微軟開源一個基於圖譜的檢索與推理增強的解決方案。GraphRAG 透過從預檢索、後檢索到提示壓縮的過程中考慮知識圖譜的檢索與推理,為回答生成提供了一種更精準和相關的方法。
- Get Started
- GitHub: https://github.com/microsoft/graphrag
- YT: Microsoft GraphRAG | 基于知识图谱的RAG套件,构建更完善的知识库 - YouTube
- GitHub: GraphRAG Local with Ollama and Gradio UI
- YT: 颠覆传统RAG!GraphRAG结合本地大模型:Gemma 2+Nomic Embed齐上阵,轻松掌握GraphRAG+Chainlit+Ollama技术栈 #graphrag #ollama #ai - YouTube
- GitHub: GraphRAG + AutoGen + Ollama + Chainlit UI = Local Multi-Agent RAG Superbot
- Doc: GenAI Ecosystem - Neo4j Labs
- 中文: 生成式 AI 的資料救星!GraphRAG 知識圖譜革命,大幅提升 LLM 準確度! | T客邦 (techbang.com)
- NeoConverse - Graph Database Search with Natural Language - Neo4j Labs
- LangChain: Enhancing RAG-based application accuracy by constructing and leveraging knowledge graphs (langchain.dev)
- Build a Question Answering application over a Graph Database | 🦜️🔗 LangChain
- LangChain: https://neo4j.com/labs/genai-ecosystem/langchain/
- https://github.com/neo4j-labs/llm-graph-builder
- ipynb: https://github.com/tomasonjo/blogs/blob/master/llm/enhancing_rag_with_graph.ipynb
Verba
Verba is a fully-customizable personal assistant for querying and interacting with your data, either locally or deployed via cloud. Resolve questions around your documents, cross-reference multiple data points or gain insights from existing knowledge bases. Verba combines state-of-the-art RAG techniques with Weaviate's context-aware database. Choose between different RAG frameworks, data types, chunking & retrieving techniques, and LLM providers based on your individual use-case.
- Github: Retrieval Augmented Generation (RAG) chatbot powered by Weaviate
- Weaviate is an open source, AI-native vector database
- Video: Open Source RAG with Ollama - YouTube
PrivateGPT
- Introduction – PrivateGPT | Docs
- GitHub: https://github.com/zylon-ai/private-gpt
- Video: PrivateGPT 2.0 - FULLY LOCAL Chat With Docs (PDF, TXT, HTML, PPTX, DOCX, and more) - YouTube
- Video: Installing Private GPT to interact with your own documents!! - YouTube
LLMWare
The Ultimate Toolkit for Enterprise RAG Pipelines with Small, Specialized Models.
talkd/dialog
Talkd.ai—Optimizing LLMs with easy RAG deployment and management.
RAG 評估
評估生成(Generation)指標
- 忠誠度(Faithfulness)
忠誠度是評估 RAG 模型生成答案的真實度和可靠性的關鍵指標。它主要衡量生成答案與給定上下文事實之間的一致性。忠誠度高的答案意味著模型能夠準確地從給定的上下文中提取信息,並生成與事實一致的回答。這對於保證生成內容的質量和信任度至關重要。 - 答案相關性(Answer Relevancy)
答案相關性則重點衡量生成答案與用戶提問的匹配程度。高相關性的答案不僅要求模型能夠理解用戶的問題,還要求其能夠生成與問題密切相關的回答。這直接影響到用戶的滿意度和模型的實用性。 - 答案正確性(Answer Correctness)
答案正確性是衡量生成的答案與已知的“地面真相”答案之間的一致性。計算方法是評估生成答案的準確度,即答案與真實答案的一致性。技術達成的方式可以通過比較生成答案與真實答案的文字相似度來完成,這類似於答案相關性,但更側重於答案的準確性。
評估檢索(Retrieval)指標
- 上下文召回率(Context Recall)
上下文召回率關注於模型在檢索過程中能否准確地找到與問題相關的上下文訊息。一個高召回率的模型能夠從大量數據中有效地過濾出最相關的訊息,這是提升問答系統準確性和效率的關鍵。 - 上下文精確度(Context Precision)
上下文精確度是衡量RAG系統在回答問題時使用的上下文資料的相關性。計算方法是確定RAG系統為回答特定問題而選擇的上下文資料與問題的相關性。技術達成的方式通常涵蓋比較RAG選擇的上下文與一組預先定義的相關上下文,計算這些上下文在生成答案時的重要性。